

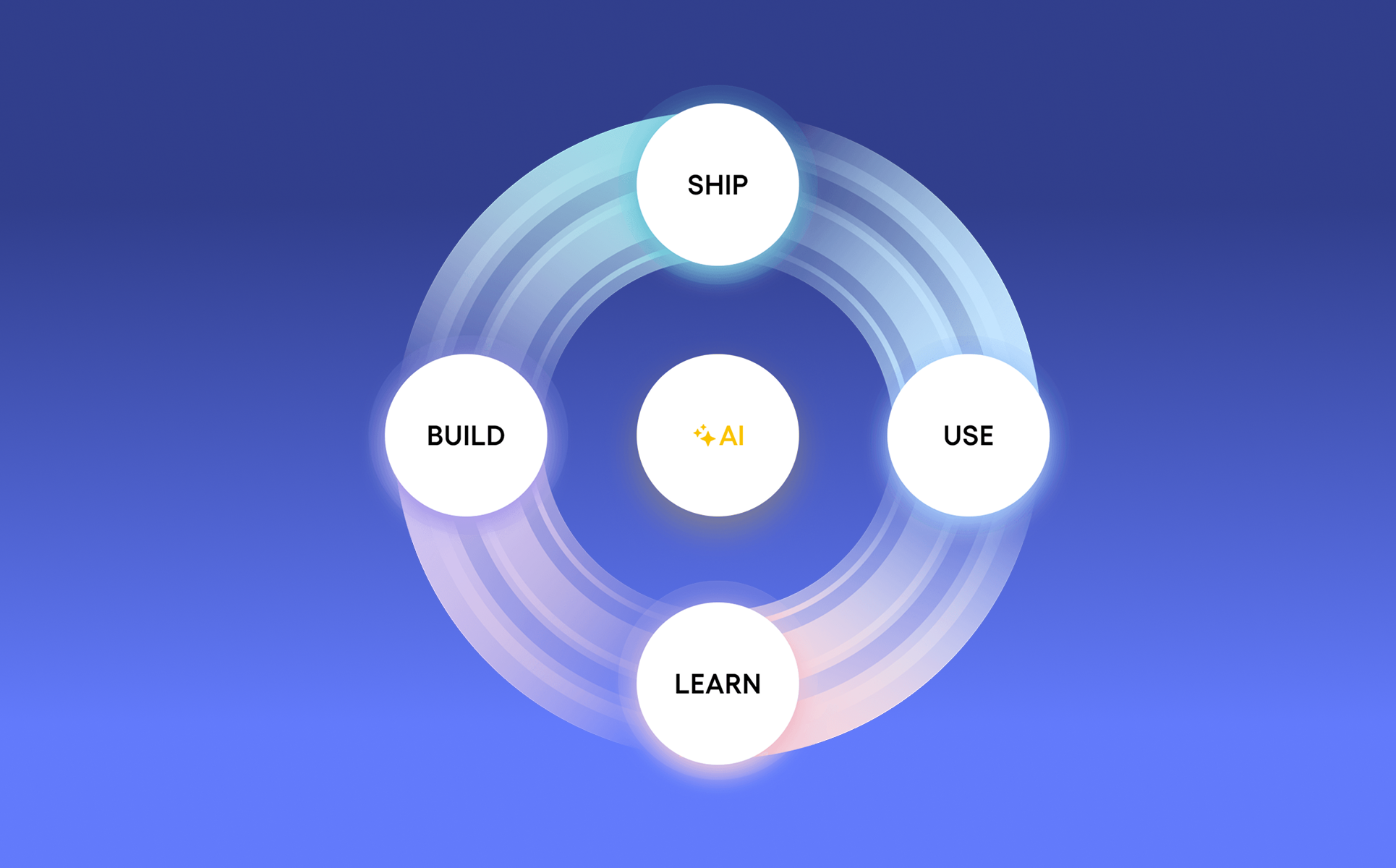
제 커리어는 마케터와 팀장을 거쳐 PO, 그리고 직접 창업을 하고 정리하는 과정을 거쳐 미국 B2B 사업 총괄을 맡기까지 끊임없이 변곡점을 그려왔습니다. 사실 창업을 마무리하던 시기는 개인적으로 꽤 고통스러웠어요. 그로 인해 낮아졌던 자신감과 성취감을 다시 회복하기 시작한 것이 미국 사업 총괄을 맡으면서였습니다. 상반기 거래액을 전년 대비 20배 성장 시키고 CAC를 95% 줄이면서, “아, 나는 어떤 환경에서도 성장을 만들어낼 수 있는 사람이구나”라는 확신을 비로소 다시 얻고 있었죠.
그 시점에 선규님(CEO)을 만났습니다. 인상적이었던 건, 선규님이 제가 거쳐온 마케팅, 창업, 프로덕트, 글로벌 사업이라는 파편화된 경험들을 각각의 경력이 아니라 “지금 마티니 그로스팀에 가장 필요한 단 하나의 완성된 퍼즐”로 정의해 주셨다는 점입니다. 저의 모든 굴곡을 전문가로서의 단단한 무기로 봐주신 것에 마음이 움직였고, 퍼포먼스·CRM·그로스가 유기적으로 실행되는 마티니의 구조라면 제 모든 경험이 최고의 임팩트를 낼 수 있겠다고 확신해 합류했습니다.
사실 대행사나 단순 컨설팅에 대한 선입견도 있었어요. 많은 그로스 컨설턴트는 실행에 책임지지 않고, 대행사는 수동적으로 좋아할만한 겉모습만 만들어주는 모습을 많이 생각했거든요. 그런데 마티니는 퍼포먼스, CRM, 그로스가 분리된 게 아니라 풀퍼널 마케팅을 함께 그로스하고 실행하는 구조였어요. 저를 필요로 해주는 환경, 그걸 잘 실현할 수 있는 환경, 그리고 사람으로서의 매력까지 — 세 가지가 맞아 떨어졌습니다.
특정 고객사의 프로젝트보다는 팀 자체에 대한 과제부터 시작했어요. 제가 왔을 때 마티니 전체에는 스마트하고 역량 있는 사람들이 정말 많았어요. 데이터 분석 능력도 있고, 전문 영역도 분명했고요. 그런데 하지만 개개인의 능력이 뛰어난 것과, 팀이 하나의 유기체처럼 한 방향으로 움직이는 것은 다른 차원의 일이다 라고 생각하거든요.
팀원들과 문제 접근 방식에 대한 생각을 정렬하는 작업부터 했어요. 조직 내에 파편화돼 있던 문서들도 다 거기에 맞게 정리했고요. 같은 뷰를 보되 같은 관점에서 문제를 정의 내릴 수 있는 구조를 만드는 데 가장 많은 시간을 썼습니다.
단순히 숫자를 가공하는 리포터가 아니라, 데이터 속에 숨겨진 비즈니스 인과관계를 추론하고 결정을 설계하는 ‘아키텍트’로서의 사고방식을 이식하고자 했습니다. “분석을 빨리 하는 팀이 아니라, 정의를 먼저 맞추는 팀”이 되는 것, 그것이 제가 이식하고자 한 첫 번째 변화였습니다.
저희 팀에서는 목표가 나오면 데이터부터 보는 게 아니라 서로 싱크를 맞추는 작업부터 해요. '목표를 어떤 기준으로 볼 거냐', '핵심 지표를 어떻게 정의할 거냐' — 이걸 먼저 맞추고 나서 분석에 들어가는 거죠. 그게 지금까지 팀이 온 방식이에요.
일반적으로 그로스팀 하면 지표 분석이나 실험을 많이 돌리는 조직이라고 생각하시는데요. 저와 저희 팀이 생각하는 그로스는 전체 비즈니스를 이해하고, 목표에 도달하기 위한 최단 거리를 찾아가는 과정이에요. 정답에 가까운 문제를 먼저 선택하고, 그걸 해결하는 과정이죠. 분석은 그 선택한 문제가 맞는지를 검증하는 도구로 생각합니다.
많은 조직이 지표를 올리기 위해 즉각적인 프로모션이나 채널 확장에 매몰되곤 합니다. 하지만 저희는 그보다 앞서 성장의 구조를 수식으로 분해(Growth Accounting)관점을 통해 성장의 건전성을 진단하라고 강조합니다.
이렇게 분해하면 지금 우리가 목표를 달성하기 위해서 어디에 집중해야할 때인지 훨씬 명확해집니다.
단순히 숫자를 키우는 것이 아니라, 비즈니스를 계산 가능한 구조로 치환하는 것, 그것이 마티니 그로스의 본질입니다.
결국 성장이라는 건 회사가 생존하는 데 근간이 되는 매출과 직결된다고 봅니다. 당장 거래액을 올리겠다가 아니더라도, 거래액에 관여할 수 있는 특정 지표 즉, 우리가 지금 당장 움직여야 할 레버(Lever)가 어느부분인지 비즈니스 모델을 계산 가능한 구조로 치환하는 것이죠.
가장 큰 차이는, 분석이 메인이 되지 않는다는 거예요. 저희는 "우리가 어디까지 가야 하는데, 그 방향을 정하기 위한 분석"을 해요. 거기까지 도달하려면 어떻게 해야 하는가의 관점에서 분석이 도구의 역할을 하는 거지, 분석 자체가 목적이 되지 않습니다.
현장에서 정말 많이 본 장면이 있어요. 데이터도 많고 분석도 많이 하는데, 대부분이 현황에 대한 진단 정도에서 끝나는 거예요. 그래서 "이걸 어떻게 바꿀 거냐"로 넘어가지 못하고, 액션까지 연결이 안 되는 경우가 정말 많았습니다. 의사결정을 돕지 못하고, 복잡도만 올라가고, 뭔가를 분석도 많이 하고 실험도 돌리는데 정작 바뀌는 건 없는 상태요.
그래서 분석을 하기 전에 "무엇을 바꿀지"를 먼저 정의하는 것, 판단 기준을 먼저 고정하는 것에 대해 이야기하고 싶었어요. 어떤 기준으로 목표를 볼 건지, 우리가 어디를 움직일 건지 — 이 기본적인 선택이 완료되고 데이터의 파도 속에서도 실행 속도를 압도적으로 높일 수 있고 분석도 더 명확해질 수 있습니다.


명확한 기준이 있어야 한다고 생각해요. 기준이 명확할수록 팀원들은 생각이 더 단순해질 수 있거든요. 일하다 보면 "이걸 해야 될까 말아야 될까, 해도 되는 건가" 애매한 경우들이 있는데, 그걸 명확하게 해줄 수 있어야 해요.
그리고 저는 답을 주는 걸 지향하지 않습니다. 특히 그로스 같은 경우에는 절대적 정답이 없기에, 제 경험이 팀원의 창의성과 논리를 가로막아서는 안 됩니다. 누가 생각하느냐에 따라 접근 방식이 다 다를 수 있어요. 그래서 답 대신 스스로 판단 기준을 세울 수 있도록 사고의 프레임워크를 함께 공유하는 편이에요.
팀원들이 목표를 어떻게 구조화하고, 어떤 기준으로 달성 여부를 판단할 수 있는지가 논리적으로 정리될 수 있다면, 그렇게 사고할 수 있는 방식을 서로 공유하는 게 훨씬 중요하다고 생각합니다. 제가 경험이 더 많으니까 따라달라는 게 아니라, 팀원들도 "이건 이렇게 보는 게 더 좋을 것 같아요"라고 논리적으로 주도적인 의견을 낼 수 있는 환경을 만드는 것이 훨씬 중요하다고 생각하거든요.
원온원(1:1) 미팅을 하다 보면, 같은 업무를 하고 있어도 3년 뒤에 그리는 본인의 모습이 서로 다르거든요. 그걸 알지 못한 채 당장 해결해야 하는 업무 위주로만 내려가다 보면, 팀원이 가고자 하는 방향과 어긋날 때가 있어요. 그게 쌓이면 성장한다고 못 느끼게 되고, 결국 떠나게 되죠.
그래서 최대한 팀원이 가고자 하는 방향을 같이 고민해주는 편이에요. 이 업무가 본인의 성장에서 어떤 역할을 해줄지, 어떤 영향을 줄지를 같이 설명해주면 의욕도 늘어나고 동기부여도 되는 것 같아요. 성장은 옆에서 도와줄 수는 있어도 끌어 올려줄 수는 없다고 생각해요. 방향만 잘 잡아주는 거죠.
원온원을 통해 각자의 커리어 로드맵과 현재의 업무를 정렬(Alignment)하는 데 공을 들입니다. 팀원이 그리는 3년 뒤의 모습과 지금의 프로젝트가 어떤 연결고리가 있는지 설명되지 않으면 동기부여는 깨지기 마련입니다. 성장은 리더가 끌어올려 주는 것이 아니라, 팀원이 스스로 나아갈 수 있도록 ‘성장의 방향’과 ‘업무의 의미’를 일치시켜 주는 가이드 역할에 집중합니다.
CRM팀과 협업이 가장 많아요. 택소노미 설계나 QA 같은 부분에서 서로 업무 효율성을 높이기 위해 해왔던 것들을 공유하고, CRM팀에서도 자동화 같은 업무 편의성을 위해 만든 것들을 공유해 주시고요. 서로가 투명하게 공유된다는 게 굉장히 인상 깊었습니다.
그리고 그로스팀 특성상 방향성을 제시하거나 역할을 요구하는 경우도 있는데, 그 과정에서 서로 건설적인 의견이 항상 오가요. 싱크 미팅도 잦고, 같은 목표를 향해 함께 만들어 가는 것 자체가 조직 전체적으로 좋은 경험을 만들어내고 있습니다.
눈높이가 다르다는 걸 먼저 생각합니다. "왜 이게 궁금할까"를 먼저 정리해보고, 그 관점에서 제가 가지고 있는 경험이 어떻게 도움이 될 수 있을지를 고민하는 편이에요.
CRM팀에서 궁금한 점들을 정리해서 보내주신 적이 있는데, 원래 CRM 분들한테만 공유하려다가 저희 팀한테도 중요한 내용이어서 그로스팀과 CRM팀이 같이 들었어요. "제 생각을 공유하는 자리"에 가까웠는데, 분석을 어떻게 접근하는지, 뭘 분석해야 할지 모를 때 어떻게 하는지 같은 주제였어요. 이런 게 다른 회사에서는 찾아보기 쉽지 않은, 마티니의 좋은 DNA라고 생각합니다.

첫째, 업무의 투명성이요. 막혔거나 도움이 필요하거나 같이 고민이 필요할 때 주저 없이 얘기할 수 있는 게 가장 중요하다고 생각합니다.
둘째, "왜"를 계속 되짚어보는 습관이에요. "이게 왜 이렇게 나왔지?", "왜 이러지?" — 이런 질문이 항상 있어야 한다고 생각합니다.
그리고 하나 더 — 연차보다 ‘고민의 총량’을 존중하는 문화입니다. 그로스는 경험도 물론 중요하지만, 압도적으로 중요한 건 고민의 총량이에요. 특정 문제에 대해 누가 더 지독하게 집착하고, 얼마나 깊게 파보려고 하느냐가 더 중요하거든요. 고민의 깊이가 깊고 끈질기다면 주니어도 시니어 이상의 임팩트를 낼수 있고, 그런 팀원들이 압도적인 경험과 기회를 얻는 문화를 지켜나가고 싶습니다.
아이디어가 톡톡 튀거나 번쩍이는 사람도 물론 좋지만, 저는 "모호함"에 대해 구조적으로 분해할 수 있는 사람이 그로스팀에 더 잘 맞는다고 생각해요. 고객사와 소통하거나 문제를 정의할 때 90% 이상이 모호한 정의들이거든요. 그 모호한 정의를 조금 더 확실하게 잡고, 구조적으로 분해해서 숫자로 구조를 만들고, 실행까지 끈기 있게 연결할 수 있는 사람이라면 마티니 그로스팀에 오시면 정말 빠르게 배우고, 크게 성장할 수 있다고 생각합니다.
궁금한 점이 생겼을 때, 그 답을 알려면 무엇을 봐야 하는지 명확하게 정의하는 습관을 들이는 거예요. 꼭 업무가 아니더라도, 일상에서 "이게 궁금해졌는데, 그럼 이걸 알기 위해서 뭘 찾아봐야 하지?"라는 습관을 계속하다 보면 문제를 정의하는 감각이 생긴다고 생각해요.
예를들면 “저 가게는 왜 장사가 잘될까?” 같은 궁금함이 생겼을 때, 그걸 확인하려면 어떤 지표를 봐야 할지 스스로 정의해 보는 거죠. 그런 일상의 습관들이 모여 날카로운 그로스 감각이 됩니다.
1~3개월: '세상을 바라보는 안경'을 바꾸는 시기입니다.
처음 오시면 저와 가장 많이 대화하실 거예요. "이 지표가 왜 중요할까?", "이 지표가 오르면 어떤걸 증명하는 걸까?" 같은 질문을 주고받으면서, 복잡한 비즈니스를 아주 단순하고 명쾌한 숫자의 구조로 쪼개보는 연습을 합니다. 맛집 줄을 서면서도 '이 가게의 회전율과 객단가는 얼마일까?'를 자연스럽게 계산하게 되는, 이른바 '그로스 안경'을 쓰는 단계라고 보시면 됩니다.
~6개월: '이론'이 '임팩트'로 바뀌는 짜릿함을 맛볼수 있습니다.
내가 찾은 '성장의 레버'를 가지고 퍼포먼스, CRM 마케터 및 다른 여러 팀들과 많은 프로젝트에서 임팩트를 움직이는 경험들을 하게 됩니다. 단순한 분석가를 넘어 '진짜 비즈니스를 움직이는 법'을 몸소 체험한다고 생각해주시면 좋겠어요
1년: 어떤 판에 던져져도 '답'을 찾아내는 사람이 됩니다.
1년쯤 지나면 도메인을 가리지 않는 자신감이 생길 거예요. 커머스든, 금융이든, 게임이든 상관없습니다. 어떤 헝클어진 실타래 같은 비즈니스 모델을 만나도 "아, 이 판은 여기만 풀면 되지않을까?"라고 핵심을 짚어내고, 무(無)에서 유(有)로 성장의 경로를 그려낼 수 있는 사람으로 바뀌고 있는 자신을 발견할 수 있습니다.
“그로스는 특별한 기술이 아니라, 집요하게 궁금해하는 마음 그 자체입니다.”
"왜 저 앱은 자꾸 나한테 알림을 보낼까?", "왜 이 서비스는 결제하기가 이렇게 편할까?" 같은 일상의 사소한 '왜'를 그냥 지나치지 않는 분이라면 이미 그로스팀의 자질이 충분합니다.
리포트 한 장 쓰고 끝나는 분석 말고, 내 손으로 직접 비즈니스의 지형을 바꾸는 ‘진짜 결정’을 내려보고 싶은 분들, 그 짜릿한 성장의 서사를 마티니에서 저와 함께 써 내려갔으면 좋겠습니다.

|
마티니 Growth 팀과 함께 할
|


데이터를 분석하다 보면 ‘이 질문에 답하려면 어떤 차트를 만들어야 할까?’라는 고민을 자주 하게 됩니다. 앰플리튜드(Amplitude)는 이러한 고민을 덜어주기 위해 Ask Amplitude를 선보였습니다.
Ask Amplitude는 사용자가 자연어로 질문을 입력하면, 곧바로 적합한 차트를 생성하고 인사이트를 제공합니다. 지금부터 Ask Amplitude를 실무에서 어떻게 활용할 수 있는지, 구체적인 사례를 통해 살펴보겠습니다.
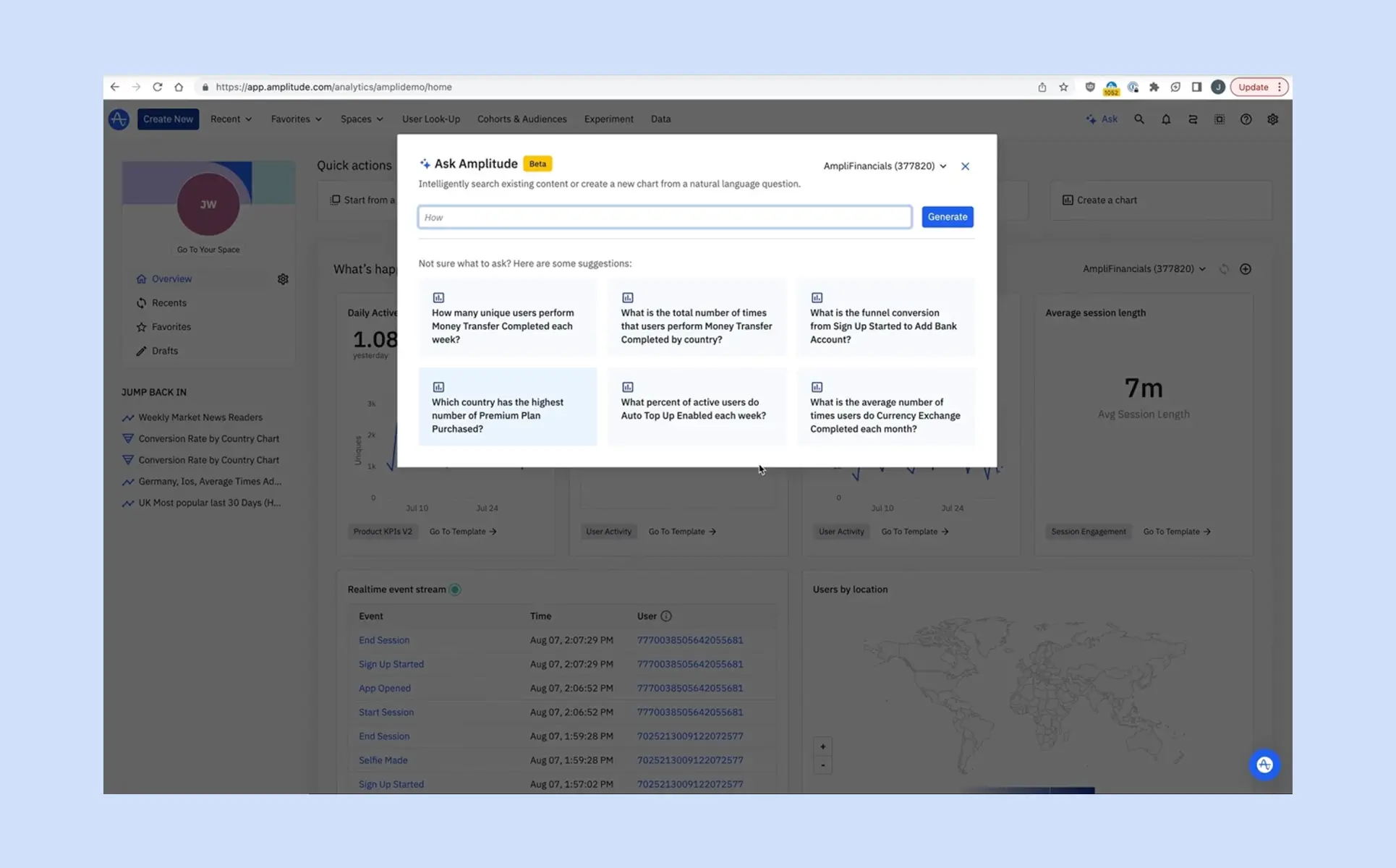
행동 데이터의 핵심 가치는 질문에 답하고, 의사 결정에 필요한 인사이트를 도출하는 데 있습니다. 그러나 지금까지 앰플리튜드를 사용하는 많은 사용자들은 제품 UI에서 차트를 단계별로 직접 구성해야 했습니다.
이제 Ask Amplitude를 통해 이러한 복잡한 차트 작성 과정을 대폭 간소화할 수 있습니다. 여러 단계를 거쳐 차트를 구성할 필요 없이, 아래 예시처럼 궁금한 내용을 질문 형태로 입력하기만 하면 됩니다.
Ask Amplitude는 질문을 이해하고, 적절한 차트 유형과 이벤트, 속성을 자동으로 선택해 결과를 보여줍니다. Amplitude AI Agent 기능과 함께 활용하면, 데이터 분석에 필요한 시간과 노력을 크게 줄일 수 있습니다.
Ask Amplitude는 데이터팀에 의존하지 않고도 누구나 스스로 데이터를 탐색할 수 있도록 설계되었습니다. 단순히 질문에 답하는 AI가 아니라, 실무자가 제품 데이터를 직접 활용할 수 있도록 돕습니다.
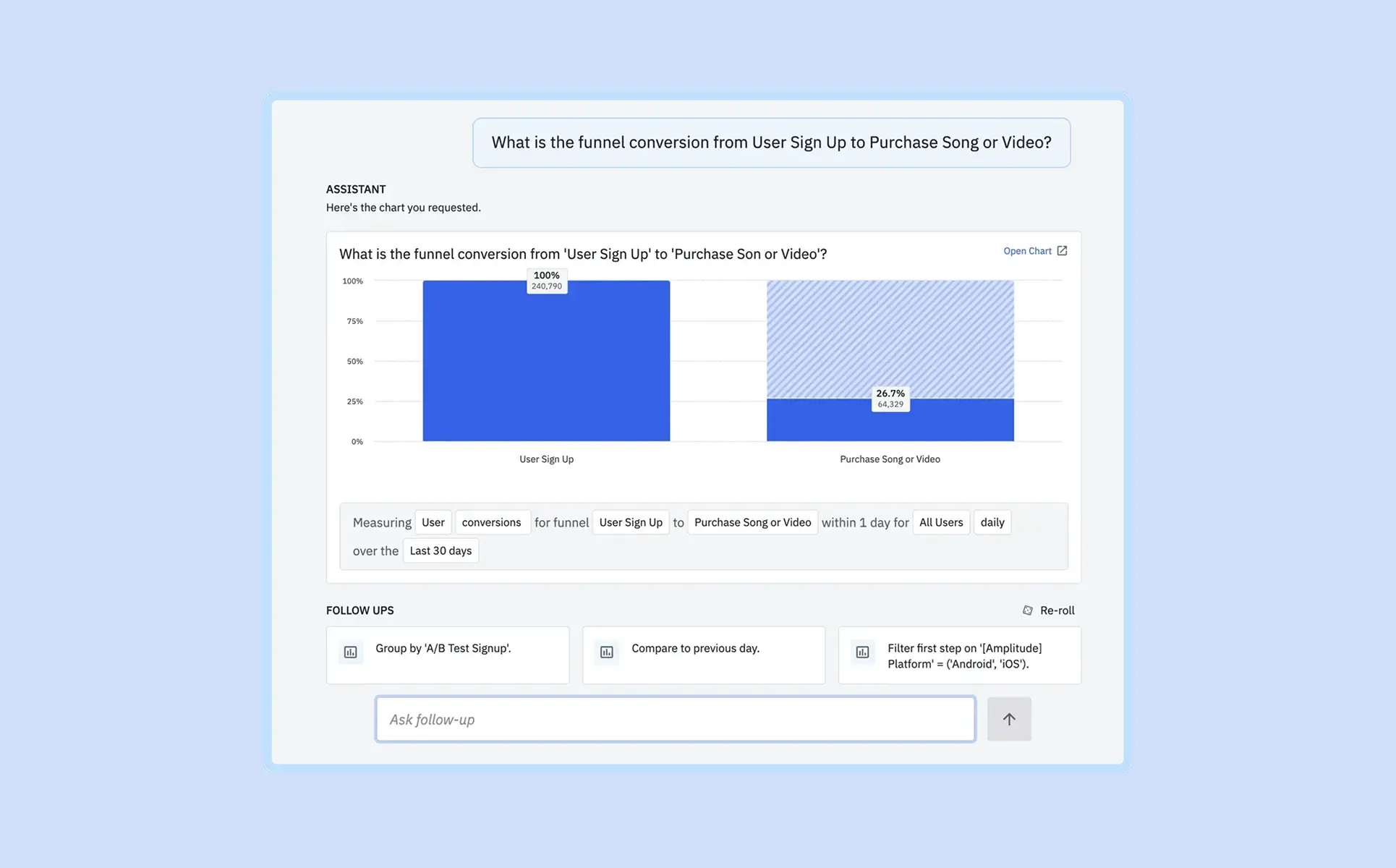
예를 들어 ‘사용자 가입부터 노래 또는 영상 구매까지의 퍼널 전환율은 어떻게 되나요?’라고 질문했다고 가정해 보겠습니다.
Ask Amplitude는 전환율 수치만 제공하는 데서 그치지 않고, A/B 테스트 가입 그룹별로 데이터를 분할하고, 전날 대비 지표를 비교하며, 첫 단계에서 안드로이드(Android)와 iOS 플랫폼만 필터링하는 방법까지 함께 보여줍니다.
또한 자연어 기반으로 데이터 분석을 구성할 수 있게 되면서, 실무자가 필요한 시점에 직접 서비스 데이터를 분석하고 인사이트를 도출할 수 있게 되었습니다. 이렇게 생성된 차트는 단순한 보고용 결과가 아니라, 실무자가 스스로 지식을 쌓고 다음 질문에 주도적으로 답할 수 있는 토대가 됩니다.
편리함만을 이유로 AI가 차트를 무분별하게 생성하게 두면 문제가 발생할 수 있습니다. 비슷한 내용의 차트가 여러 개가 있으면, 오히려 어떤 차트를 신뢰해야 할지 판단하기 어려워지기 때문입니다.
Ask Amplitude는 시맨틱 검색을 활용해 이러한 문제를 방지합니다. 새로운 차트를 만들기 전에 먼저 앰플리튜드 내에 이미 존재하는 콘텐츠를 검색하고, 동료들이 만들고 검증한 차트 중 유사한 것이 있는지부터 확인합니다.
이러한 검색 기법은 ‘스트리밍된 비디오 시간’과 ‘총 시청 시간’처럼 표현은 다르지만 같은 의미를 가진 용어까지 인식합니다. 덕분에 사용자는 대부분의 경우 새로운 차트를 추가로 생성하지 않고도 필요한 콘텐츠를 찾을 수 있으며, 앰플리튜드 내 콘텐츠의 품질과 신뢰도를 함께 유지할 수 있습니다.
마티니는 앰플리튜드를 활용해 고객사가 데이터에서 인사이트를 얻고, 더 나은 의사결정을 할 수 있도록 돕고 있습니다. 데이터 환경을 구축하고 마케팅 성과를 높이고 싶다면, 지금 바로 마티니와 만나보세요.
|
|
실무자에게 적합한
|


오늘날 수많은 AI 제품이 나왔지만, 데이터를 수집하고 해석하는 과정은 여전히 수동적이고 시간이 많이 소요됩니다. 특히 빠르게 변화하는 시장 환경에서는 데이터가 부족한 것이 아닌 데이터를 바탕으로 ‘문제’를 찾고, 이것을 ‘행동’으로 전환하는 과정에서 많은 어려움이 발생합니다.
앰플리튜드는 이러한 문제를 해결하기 위해 AI Agents를 출시했습니다. Amplitude AI Agents는 단순히 데이터를 시각화하거나 인사이트를 제공하는 도구를 넘어, 문제를 발견하고 원인을 분석하며 다음 단계를 제안하는 역할을 수행합니다.
지금부터 앰플리튜드의 새로운 기능, Amplitude AI Agents를 알아보겠습니다.

기존의 분석 도구가 '무엇이 일어났는지'를 보여주는 데 집중했다면, Amplitude AI Agents는 '무엇을 해야 하는지'까지 제안합니다.
Amplitude AI Agents는 웹사이트 전환율 향상, 온보딩 경험 개선 등 팀이 달성하고자 하는 구체적인 목표를 설정할 수 있습니다. 목표 설정이 완료되면, Agents는 24시간 행동 데이터, 세션 리플레이 등 계정 전반의 데이터를 수집하고 분석합니다.
이를 바탕으로, ‘인사이트’ 단계에서 근본 원인 분석을 실행하고 세션 리플레이를 검토하여 문제의 원인을 파악합니다. 이후 ‘액션’ 단계에서 A/B 테스트를 설계하거나 특정 코호트에 맞는 제품 내 가이드를 배포하는 등 구체적인 다음 단계를 제안합니다.
.webp)
Amplitude AI Agents는 다른 AI 도구와 명확한 차이가 있습니다.
대부분의 분석 도구는 AI 기반 인사이트와 권장 사항을 제공한 후 다음 단계를 ‘사용자’에게 맡깁니다. 실행과 의사결정 권한이 사람에게 있는 것이죠.
하지만 Amplitude AI Agents는 인사이트 도출을 넘어 실질적인 행동을 수행할 수 있도록 설계되어있습니다.
Amplitude AI Agents는 이런 차별점을 바탕으로, 팀에 대한 지식과 실제 업무 사이의 격차를 줄여줍니다.
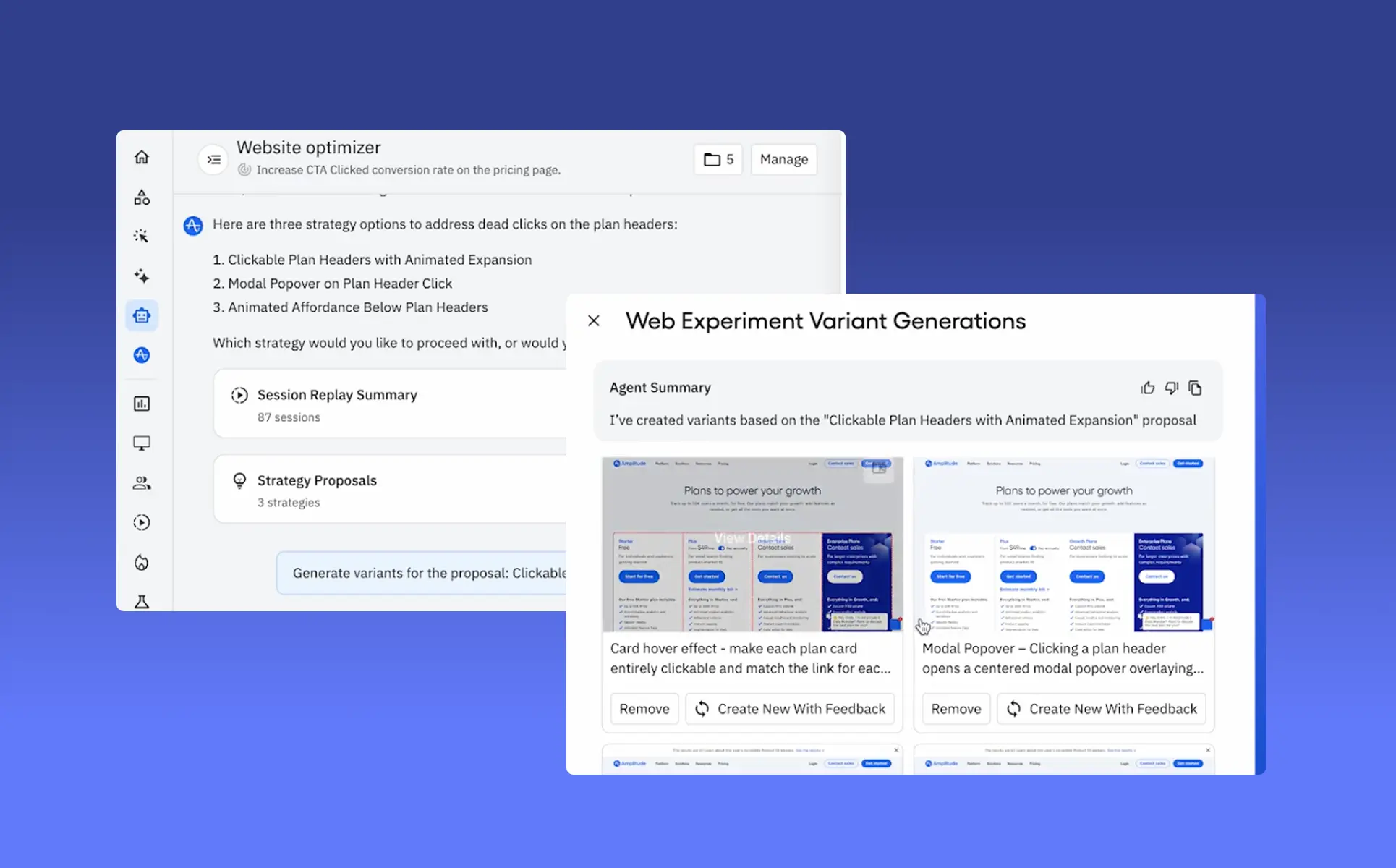
Amplitude AI Agents는 다양한 비즈니스 상황에서 실질적인 성과를 만들어냅니다.
여전히 많은 팀이 아래와 같은 고민을 안고 있습니다.
하지만 Amplitude AI Agents는 지식과 실행 사이의 격차를 줄여 이 고민들을 해결해줍니다.
"데이터는 있지만 이를 활용할 시간이 없다"
"데이터 속에 인사이트가 있다는 것을 알지만 파헤칠 여유가 없다",
"데이터 중심적인 조직이 되고 싶지만 분석 인력이 부족하다"
이를 통해 팀은 전략적 우선순위에 집중하고, AI Agents는 여러 가설을 테스트하며 비즈니스 KPI 달성에 적합한 인사이트를 도출할 수 있습니다.
마티니는 앰플리튜드의 공식 파트너로서, 고객사가 AI Agents를 포함한 앰플리튜드의 기능을 효과적으로 활용할 수 있도록 지원하고 있습니다.
지금 아래 버튼을 눌러, 마티니와 함께 ‘인사이트’에서 끝나는 것이 아닌 ‘실행’으로 이어지는 데이터 분석을 시작해보세요.
|
|
앰플리튜드 도입을 검토하고 있다면?
|


상품을 검색하고, 클릭하고, 장바구니에 담고, 결제하기까지. 고객의 쇼핑 여정은 몇 번의 클릭으로, ‘정말 단순하게’ 끝나는 것처럼 보입니다.
하지만 그 짧은 순간 안에는 수십 개의 화면 전환과 수백 개의 기능, 그리고 그보다 더 많은 데이터의 흐름이 얽혀있습니다.
아직도 많은 팀이 이 복잡함을 과소평가한 채 택소노미(Taxonomy)를 설계하거나 이벤트를 수집하기 시작합니다. 그 결과, '데이터 분석' 단계에서 어려움을 호소하시는 분들이 많습니다.
“이 이벤트는 정확히 어디서 발생한 거지?”
“정의된 경로 외에 다른 트리거 포인트가 있나?”
이런 질문은 서비스가 고도화될수록 더 자주 발생합니다. UI·UX가 개편될 때마다 예외 케이스가 생기고, 처음 정의했던 이벤트 구조는 점점 흔들립니다. 결국 데이터 정리는 계속 밀리고, 어느 순간 서비스 변화의 속도를 따라잡지 못하는 악순환에 빠지게 됩니다.
이러한 악순환을 줄이고 서비스 전체의 맥락 속에서 데이터를 이해하기 위해 필요한 첫 번째 단계가 바로 IA(Information Architecture, 정보 구조도) 설계입니다. 이번 글에서는 IA가 데이터 분석에서 왜 중요한지 알아보겠습니다.
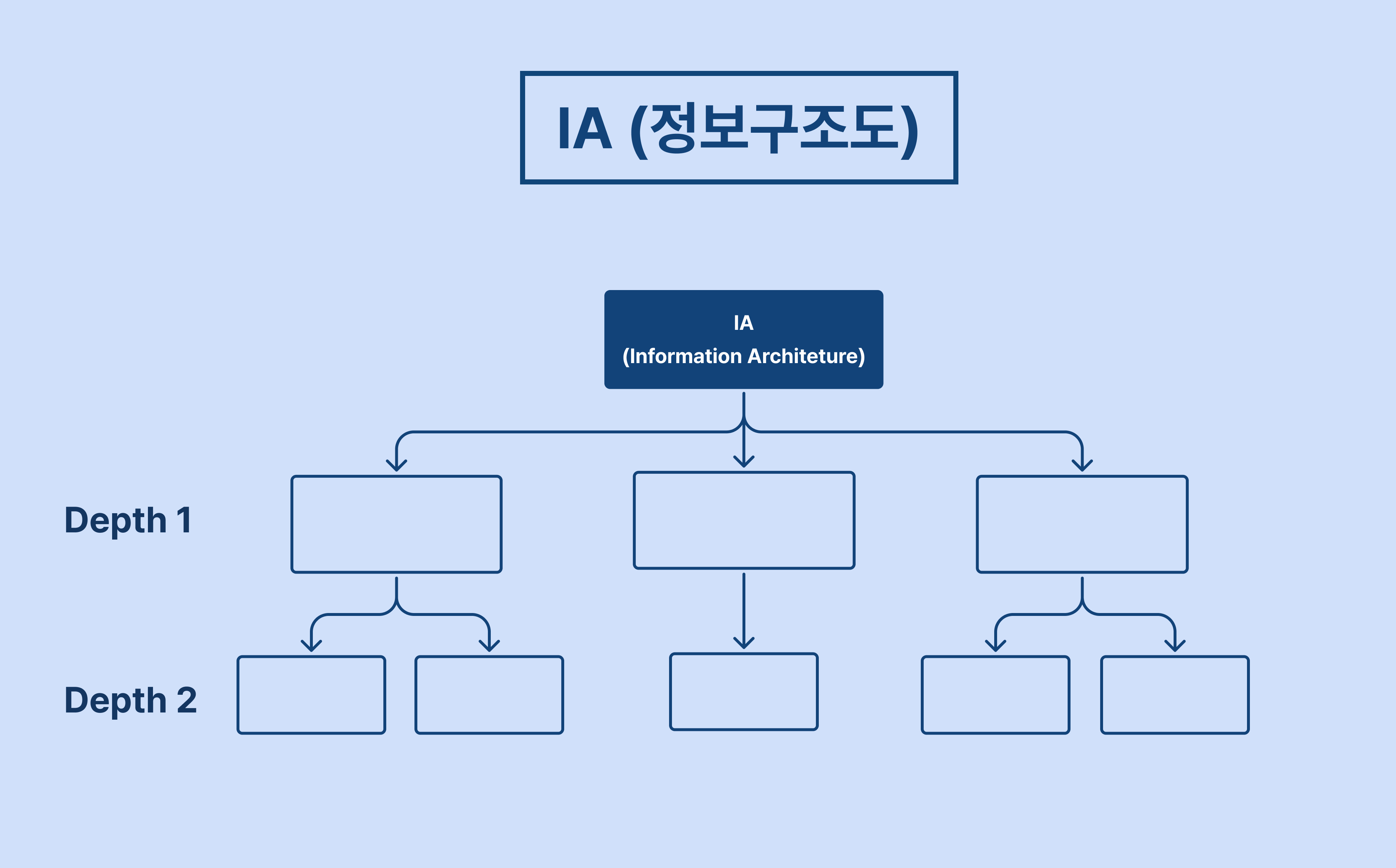
IA(Information Architecture)는 보통 서비스 개발 전 기획 단계에서 사용됩니다.
이는 웹이나 앱 안에 존재하는 수많은 화면, 버튼, 기능을 한눈에 볼 수 있도록 체계적으로 정리한 서비스의 지도이자 목차라고 볼 수 있습니다.
이 단계에서는 서비스의 전체 구조를 체계적으로 정리하고, 각 페이지와 기능을 계층적으로 정의하는 데 중점을 둡니다.
.webp)
이렇게 정의된 IA는 와이어프레임과 유저 플로우 설계와 연결되어 발전시킬 수 있는데요.
와이어프레임(Wireframe)이 실제 화면을 기준으로 사용자의 이동 경로를 보여준다면, IA는 그보다 한 단계 위에서 서비스 전체의 계층별 구조를 보여주는 설계도 역할을 합니다.
결국 서비스 구조를 먼저 이해해야만 사용자가 거치는 모든 여정과 흐름을 온전히 파악할 수 있습니다.
그렇다면, 이미 서비스가 출시된 상황에서 다시 IA를 그린다는 건 어떤 의미일까요? 단순히 구조를 정리하거나 문서를 업데이트하기 위한 작업일까요? 사실 그렇지 않습니다.
데이터 분석은 결국 '사용자가 어떤 화면에서 어떤 행동을 했는가'를 해석하는 일입니다. 서비스 구조를 파악하지 않은 채 데이터를 분석하면, 이벤트는 맥락을 잃고 분석은 반복적으로 막힙니다.
IA가 데이터 분석의 출발점인 이유는 명확합니다. 모든 분석의 기준점이 되기 때문입니다. 이제 왜 중요한지, 세 가지로 나눠 알아보겠습니다.


데이터 분석에서 가장 중요한 질문은 이것입니다.
"이 이벤트가 어디서, 어떤 맥락에서 발생했는가?"
IA를 기준으로 각 화면과 기능을 정리해두면, 어떤 페이지에서 어떤 이벤트가 발생해야 하는지를 명확히 정의할 수 있습니다. 즉, IA는 이벤트 매핑의 기준점이 됩니다.
이 기준점이 있으면 분석가는 데이터의 맥락을 잃지 않고, 이벤트가 누락되거나 중복 수집되는 지점을 빠르게 찾아낼 수 있습니다. 문제를 발견하는 시간이 줄어들고, 분석은 더 정확해집니다.
커머스 유저 여정은 단순해 보이지만 꽤 복잡합니다.
일반적인 홈 → 검색 → 상품 상세 → 장바구니 → 주문/결제라는 프로세스에 속하지 않는 예외 케이스와 변형 경로가 많기 때문입니다.
이때 IA로 전체 구조를 보면, 각 단계의 전환과 이탈 지점을 구조적으로 파악할 수 있습니다.
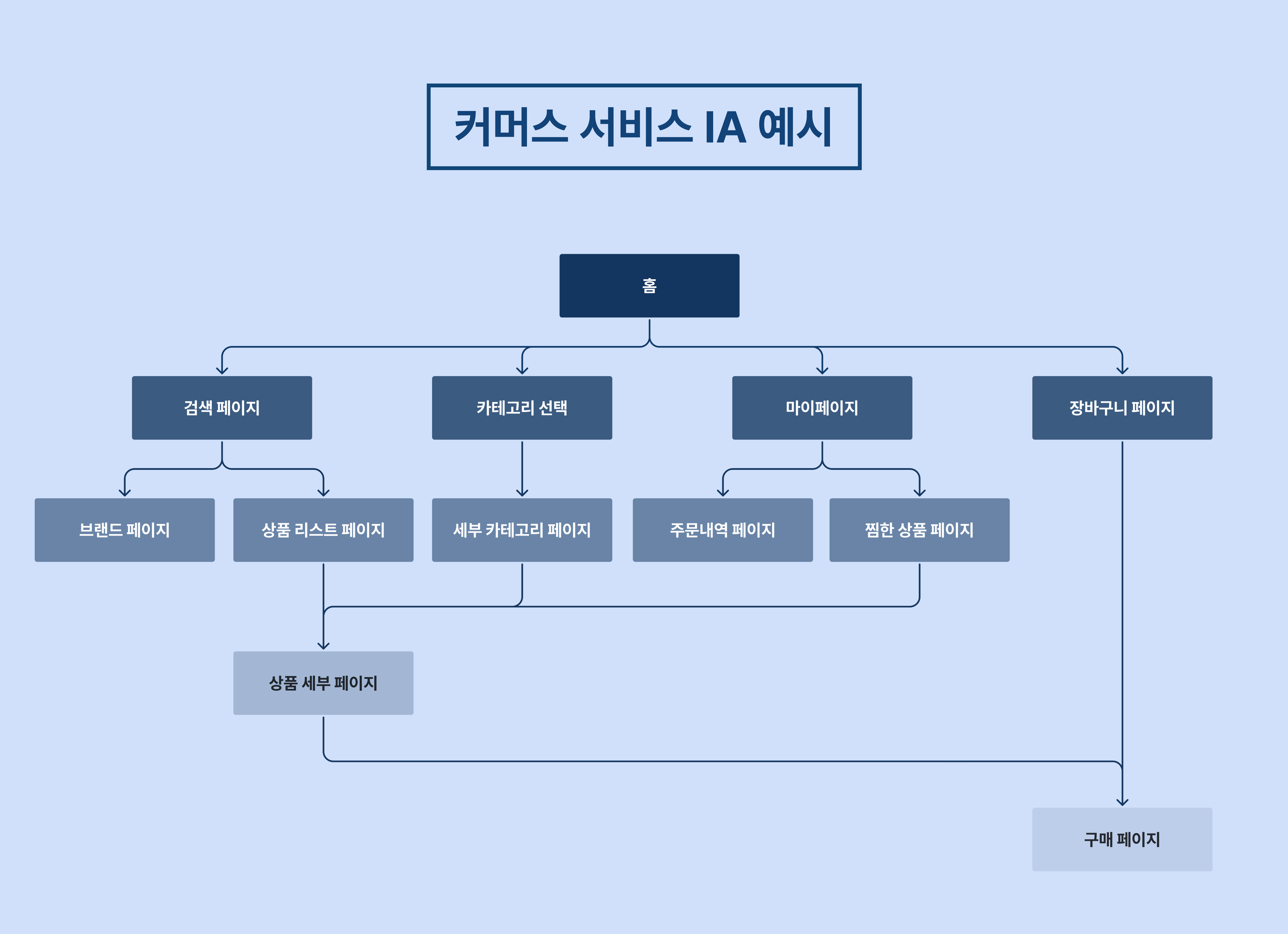
위 사진은 커머스 서비스를 시각화한 IA 예시입니다. 모든 흐름을 한눈에 파악할 수 있습니다.
이처럼 각 화면에서 발생해야 하는 이벤트를 미리 정의해두면, 실제 분석 단계에서 '이 이벤트가 어디서 왔는지' 명확히 정의할 수 있습니다. 또한 서비스가 개편되어도 IA를 기준으로 변경 사항을 추적할 수 있어, 데이터 구조의 일관성을 유지할 수 있습니다.
이처럼 복잡한 사용자 여정 과정을 수반하는 대규모 서비스일수록, IA 설계를 통해 퍼널 설계의 정확도를 높이고 전환율 최적화나 리텐션 분석의 토대를 마련할 수 있습니다.

서비스가 커질수록 이벤트와 프로퍼티는 점점 복잡해집니다.
이때 IA는 전체 서비스의 지도 역할을 합니다. 어떤 화면이 어떤 기능과 연결되는지, 새로운 기능이 추가되면 어디에서 구조가 변하는지를 IA를 통해 빠르게 파악할 수 있습니다.
이런 구조적 기준이 있으면, 이벤트 네이밍, 프로퍼티 정의, 페이지 기준 등 데이터 표준화 작업을 쉽게 검증할 수 있습니다. 결국 IA는 단순한 설계 문서를 넘어, 데이터 분석 유지보수 비용을 줄이는 강력한 도구가 됩니다.
서비스가 커질수록 '어디서 문제가 생겼는지', '이 이벤트가 정확히 어디서 발생했는지'를 빠르게 파악하는 기준이 필요합니다. IA는 바로 그 기준을 만들어주는 작업입니다.
IA를 통해 서비스 흐름을 구조적으로 정리하면, 이벤트 수집 지점을 명확히 파악할 수 있고, 퍼널 설계와 데이터 분석의 정확도를 높일 수 있습니다. 더 나아가 팀 간 커뮤니케이션 비용을 줄이고, 데이터 거버넌스 체계를 탄탄하게 만들 수 있습니다.
결국 IA 설계는 '지금 당장의 효율'을 위한 일이 아닌, 장기적으로 데이터 분석 비용을 줄이기 위한 투자입니다. ‘지속 가능한 데이터 분석 환경' 구축을 시작하고 싶다면, 지금 바로 마티니와 만나보세요.
|
|
데이터 분석환경 구축을 위한
|


북극성 프레임워크는 단일 지표인 북극성 지표를 기반으로 한 프로덕트 관리 모델로, 고객이 프로덕트에서 얻는 가치를 가장 잘 나타냅니다. 북극성 지표는 좋은 제품 전략 프레임워크지만, 오해하거나 잘못 사용하면 팀의 방향성이 틀어질 수 있습니다. 따라서 지표를 올바르게 설정하는 것이 매우 중요합니다.
모든 프로덕트에는 북극성 지표가 필요합니다. 북극성 지표는 비즈니스에 더 나은 방향성을 제시하고, 명확한 우선순위를 설정하고, 리소스를 절감하는 데 도움이 되기 때문입니다.
이번 아티클에서 북극성 지표란 무엇이며, 좋은 북극성 지표를 설정하기 위해서 어떤 것을 고려해야 하는지 알아보세요.

북극성 지표는 프로덕트의 성패를 측정하는 핵심 척도입니다. 이 지표는 프로덕트 팀이 해결하려는 고객의 문제와 이를 통해 얻고자 하는 수익의 관계를 정의합니다.
특히, 북극성 지표를 통해 다음과 같은 내용을 확인할 수 있습니다.
많은 기업에서 프로덕트 팀의 성공은 비즈니스에 미치는 영향이 아닌, 얼마나 많은 일을 하느냐에 따라 결정됩니다. 하지만 ‘임팩트’ 중심의 문화가 없다면 비즈니스의 방향에 영향을 미치기 어렵습니다. 북극성 지표가 없다면 프로덕트 중심으로 성장하는 기업이 되기 어렵습니다.

북극성 지표는 프로덕트 내 고객 행동에 대한 깊은 이해에서 비롯되어야 합니다. 고객의 ‘아하 모먼트’를 찾는 것도 비슷한 맥락입니다. 고객이 유입 초기 프로덕트에 머무는 순간을 찾았다면, 효과적인 북극성 지표를 찾았다고 할 수 있습니다.
즉, ‘DAU(Daily Active Users)’ 또는 ‘회원가입 수’와 같은 지표는 좋은 북극성 지표가 될 수 없습니다. 일회성으로는 유용할 수 있지만 고객이 프로덕트에 대해 무엇을 중요하게 생각하는지는 알 수 없기 때문입니다. 프로덕트 팀에서 느끼는 고객 가치를 북극성 지표와 연결하지 못한다면, 비즈니스는 잘못된 방향으로 흘러갈 수 있습니다.

북극성 지표를 잘 설정했다면, 그 지표만 보더라도 누구나 프로덕트가 어떤 가치를 추구하는지 쉽게 이해할 수 있어야 합니다. 북극성 지표는 단순한 숫자가 아니라 기업의 전략과 비전을 한눈에 보여주는 역할을 합니다. 조직 내부에서는 팀과 부서가 같은 목표를 바라보도록 돕고, 외부에서는 기업이 궁극적으로 어떤 문제를 해결하고자 하는지를 설명하는 공용 언어가 될 수 있습니다.
예를 들어 여행 플랫폼에서 ‘재방문 고객 비율’을 북극성 지표로 설정했다면, 플랫폼이 일회성 예약을 넘어 장기적으로 고객 경험을 개선하는 전략을 갖고 있다는 점을 확인할 수 있습니다. 이처럼 좋은 북극성 지표는 프로덕트가 만들고 있는 핵심 가치를 드러내야 합니다.

좋은 북극성 지표는 성공의 선행 지표가 됩니다. 월별 매출이나 사용자당 평균 매출(ARPU)과 같은 후행 지표는 프로덕트의 영향력을 설명하는 지표가 되기 어렵습니다. 이 지표는 매출을 예측하기보다는 과거에 무슨 일이 일어났는지를 파악하는 지표입니다.
적합한 북극성 지표를 선택하는 첫 번째 단계는, 비즈니스가 어떤 ‘게임’을 하고 있는지 파악하는 것입니다. 여기서 게임이란 ‘핵심 고객 참여 모델’을 의미합니다. Amplitude(앰플리튜드)에서 프로덕트에 대한 연구와 매달 1조 개 이상의 행동 데이터를 분석한 결과, 핵심 고객 참여 모델은 다음 중 하나로 분류될 수 있습니다.
프로덕트 팀은 위의 3가지 중 하나의 모델을 결정해야 합니다. 이는 프로덕트 전략을 수립하고, 좋은 북극성 지표를 정의하는 첫 번째 단계입니다.

위의 표는 이 위의 3가지 모델 중 하나를 채택한 기업 사례입니다. 다만, 같은 모델을 채택하고 있더라도 기업마다 고유한 프로덕트 전략을 가지고 있기 때문에 북극성 지표는 서로 다를 수 있습니다.

앰플리튜드를 활용하면 북극성 지표를 실시간으로 트래킹할 수 있습니다. 북극성 지표를 활용하면 팀 내에서 보다 가치 있는 커뮤니케이션이 가능합니다. 북극성 지표를 찾고, 구현하기 위해서는 프로덕트 팀이 단순 업무 상태 관리에서 벗어나, 보다 프로덕트에 깊이 몰입하고 아이디어를 공유하는 데 집중할 수 있습니다.


고객 여정에는 ‘아하 모먼트(Aha Moment)’라는 중요한 순간이 있습니다. 유저가 프로덕트의 핵심 가치를 이해하는 순간입니다.
아하 모먼트를 찾고, 디자인하는 것이 중요한 이유는 아하 모먼트를 통해 목표에 도달하는 데 프로덕트가 어떻게 도움이 되는지 보여주고, 결과적으로 유저가 이탈할 확률을 줄여주기 때문입니다. 아하 모먼트를 파악하기 위해서는 기능 이해, 온보딩 완료와 같은 기본적인 유저 행동을 확인해야 합니다.
이번 아티클에서 더 많은 유저를 장기 고객으로 전환할 수 있는 아하 모먼트란 무엇인지, 그리고 어떻게 아하 모먼트를 찾고, 아하 모먼트로 유저를 유도할 수 있는지 알아보세요.
아하 모먼트는 유저가 프로덕트의 핵심 가치를 파악하고 내면화하는 순간입니다. 활성화(Activation) 모먼트, 유레카 모먼트, 깨달음의 순간(Lightbulb moment)이라고도 합니다. 아하 모먼트는 단일 순간일 수도 있고, 사용자가 프로덕트의 가치를 진정으로 파악할 수 있을만큼 충분히 사용한 시점일 수도 있습니다. 이 갑작스러운 순간은 유저를 활성화시키는 데 아주 중요하며, 일반적으로 유저가 프로덕트에 투자하기로 한 의사결정과 일치합니다.

션 엘리스(Sean Ellis)는 그의 저서 ‘진화된 마케팅 그로스 해킹’에서 아하 모먼트를 ‘유저에게 프로덕트의 유용성이 인식되는 순간, 유저가 핵심 가치를 진정으로 얻을 때’라고 정의합니다. 여기서 핵심 가치란, ‘프로덕트가 무엇을 위한 것인지, 왜 필요한지, 그리고 그것을 사용함으로써 얻을 수 있는 이익은 무엇인지’에 대한 개념입니다.
프로덕트의 아하 모먼트는 만드는 것이 아니라 사용자가 느끼는 것입니다. 아하 모먼트를 만들 수는 없지만 '프로덕트에서 아하 모먼트가 발생할 수 있는 조건'을 만들 수는 있습니다. 프로덕트 팀은 아하 모먼트를 이해하고 더 많은 유저가 아하 모먼트에 도달할 수 있도록 안내해야 합니다.
프로덕트의 아하 모먼트를 알 수 있는 몇 가지 방법을 소개합니다.
유저들은 모두 같은 특성을 갖고 있지 않습니다. 유저는 각자 가지고 있는 니즈와 해결하고자 하는 문제가 다르기 때문에 서로 다른 아하 모먼트를 경험할 수 있습니다. 이러한 아하 모먼트를 알아내려면 유저가 프로덕트를 사용하는 방법과 이유에 따라 서로 다른 페르소나를 파악하고, 그룹화해야 합니다.
몇몇 기업의 경우 유저 세그먼트를 지역과 연령대로 분류합니다. 다른 기업은 유저 역할(엔지니어 vs 디자이너, PM vs 디자이너 등)을 중심으로 세그먼트를 분류하기도 합니다. 유저 세그먼트에 대한 정의를 내리면 각 세그먼트의 라이프사이클을 보다 정확하게 분석할 수 있습니다.
위 질문에 대한 답변은 유저가 프로덕트의 가치를 빠르게 파악하고, 아하 모먼트가 발생하도록 유저를 가이드하는 데 도움을 줄 수 있습니다.
아하 모먼트를 이해하고 최적화하려면 고객 여정 전체를 파악해야 합니다. 앰플리튜드의 ‘세션 리플레이’ 기능은 유저 세션 리플레이(Session Replay)와, 실시간 분석을 결합하여 보여주기 때문에 고객 여정을 쉽게 파악할 수 있습니다.
세션 리플레이를 통해 유저의 ‘돌파구’와 같은 순간을 시각적으로 확인해 보세요. 유저가 인터페이스를 어떻게 탐색하고, 어떤 기능을 주로 사용하며, 어느 시점에 프로덕트에 대한 이해가 높아지는지 관찰할 수 있습니다. 유저 행동을 분석해 아하 모먼트가 발생하는 정확한 지점을 파악하세요. 여기서 유저 경험을 세분화하면 더 많은 유저를 아하 모먼트로 안내할 수 있습니다.
유저 피드백을 사용하여 프로덕트의 아하 모먼트를 발견할 수도 있습니다. 유저의 공감을 불러일으키는 기능을 이해하여 프로덕트 경험을 개선하고, 더 많은 유저에게 이 기능을 안내할 수 있습니다.
분석 도구를 활용해 전환율, 유저 리텐션과 같은 프로덕트 지표를 분석해 보세요. 특정 기능이 선택된 이유, 특정 조건이 적용되는 위치를 통해 리텐션 데이터를 시각화할 수 있습니다. 예를 들어 소셜미디어 앱에서 고객 행동을 분석하면, 처음 며칠 이내에 특정 수의 유저와 연결되는 것이 장기적인 리텐션으로 이어지는 것과 밀접한 관련이 있음을 알 수 있습니다.
프로덕트와 유저에 대한 깊이있는 분석으로 아하 모먼트에 대한 중요한 인사이트를 얻을 수 있습니다. 그러나 ‘선택 편향’을 주의해야 합니다. 예를 들어, 특정 온보딩 플로우를 완료한 유저에게만 초점을 맞추면 그들의 리텐션을 해당 플로우에 대한 기여로만 측정하는 오류를 범할 수 있습니다. 해당 플로우를 건너뛴 유저의 아하 모먼트는 완전히 다를 수 있습니다. 따라서 분석을 할 때에는 다양한 액션과 고객 여정을 포함하여 더 많은 유저에게 리텐션을 유도할 수 있는 아하 모먼트를 정확하게 판단해야 합니다.

아하 모먼트를 정의했다면, 프로덕트에서 유저가 아하 모먼트를 효과적으로 경험하도록 안내해 보세요.
유저를 아하 모먼트로 안내하는 것도 중요하지만 강압적인 전략은 역효과를 낼 수 있습니다. 유저는 정해진 경로대로 따라가는 것을 꺼려하고, 자신의 속도에 맞춰 프로덕트의 가치를 발견하고 싶어하는 경향이 있습니다.
방해가 되는 모달과 툴팁으로 유저 여정을 방해하기보다 직관적인 유저 여정을 설계해 보세요. 잘 설계된 도시에는 명확한 표지판, 유용한 랜드마크, 탐험의 자유를 제공하면서도 목적지까지 쉽게 이동할 수 있는 길이 있습니다.
이와 마찬가지로 프로덕트는 유저가 자연스럽게 아하 모먼트를 경험할 수 있도록 주요 액션과 기능을 부드럽게 연결해야 합니다.

유저를 아하 모먼트로 안내하는 것은 단순히 기능을 보여주는 것이 아닙니다. 새로운 유저가 프로덕트의 핵심 가치를 경험할 수 있도록 명확한 경로를 설계해야 합니다. 이해와 참여를 유도하는 주요 액션과 상호 작용에 우선순위를 두는 ‘유저 저니 맵(User Journey Map)’을 만든다고 생각해 보세요.
사용자를 자연스럽게 안내하는 직관적인 워크플로우를 구축해 보세요. 예를 들어 파일 공유 앱의 아하 모먼트가 ‘어디서든 파일에 액세스 할 수 있다는 것을 인식하는 순간’이라면, 온보딩 플로우를 통해 유저가 다른 장치에서 파일을 업로드하고 액세스할 수 있도록 즉시 유도할 수 있습니다.
프로덕트에 세 가지 일반적인 아하 모먼트가 있다고 가정했을 때, 이 세 가지 순간을 모두 경험하게 하는 것은 어려운 일입니다. 유저가 모든 아하 모먼트에 도달하도록 하는 대신 유저의 의도에 집중해 보세요. 유저가 두 번째 아하 모먼트로 나아가고 있는 것을 발견했다면 그 순간으로 이동시키는 데 집중해야 합니다.
유저의 반응이 예상되는 시점이 있다면 해당 시점에 유저를 안내해야 합니다. 유저가 몇 가지 모달이나 툴팁이 표시되자마자 닫거나 삭제한 경우, 시간차를 두고 다른 내용을 보여주는 것이 효과적입니다.
성공적인 프로덕트는 여러 경험을 통해 유저에게 가치를 제공합니다. 단 하나의 아하 모먼트에만 의존하는 것이 아니라, 유저에게 가치를 제공할 수 있는 다양한 방법을 생각해 보세요.
핵심 가치를 제안하는 주요 아하 모먼트와 유저 참여를 지속할 수 있는 보조 아하 모먼트를 설계하세요. 이를 통해 프로덕트 내에서 여러 경로를 만들어 유저가 프로덕트의 잠재력을 최대한으로 경험할 수 있습니다.
세션 리플레이를 충분히 살펴보면, 프로덕트 내에서 정처 없이 떠돌아 다니는 유저를 발견할 수 있습니다. 유저가 이 지점에 도달하기 전에, 온보딩을 완료하도록 유도해야 합니다. 때로는 유저가 스스로 해낼 수 있도록 도와야 할 때도 있습니다.
‘아하 모먼트’라는 용어는 고객 여정의 다른 성과 지표와 혼동되기도 합니다. 예를 들어, 유저의 원활한 온보딩 경험은 중요하지만 아하 모먼트라고 볼 수는 없습니다. 아하 모먼트는 유저가 프로덕트의 핵심 가치를 처음으로 이해하는 순간입니다. 온보딩 프로세스는 아하 모먼트로 유저를 안내하는 역할이라고 할 수 있습니다.
마찬가지로 단순히 프로덕트 사용 방법을 이해하는 것만으로는 아하 모먼트라고 볼 수 없습니다. 예를 들어 디자인 툴에서 디자인 기능을 이해하는 것은 꼭 필요한 과정이지만, 유저의 아하 모먼트는 툴을 활용해 팀원들과 실시간 협업의 힘을 경험하는 순간일 수 있습니다. 툴팁이나 단계별 온보딩 같은 인앱 가이드도 프로덕트의 가치를 전달하는 데 도움이 될 수는 있습니다. 그러나 아하 모먼트는 이러한 팁의 전달이 아니라 팁을 따를 때 유저가 프로덕트가 왜 필요한지 이해하게 되는 순간입니다.
유저 여정을 분석하여 프로덕트의 아하 모먼트를 정확히 파악해 보세요. 앰플리튜드의 분석 기능은 사용자 경로를 시각화하고, 참여를 유도할 수 있는 주요 기능을 식별하는 데 도움이 됩니다. 퍼널 분석을 사용하여 사용자 이탈 지점을 확인하거나, 여정 분석을 통해 일반적인 액션을 파악할 수 있습니다. 이러한 인사이트를 사용자 리서치와 결합하면 사용자 여정을 최적화하고 더 많은 사용자가 아하 모먼트를 경험하도록 안내할 수 있습니다.

1장에서 이벤트 패스와 택소노미의 전반적인 구조를 다루었다면, 이제 개별 이벤트를 어떻게 설계해야 하는지에 대해 고민해볼 차례다. 택소노미는 단순히 이벤트를 나열하는 것이 아니라, 어떤 이벤트를 정의할지, 각 이벤트가 어떤 역할을 해야 하는지, 그리고 데이터 분석에 실질적으로 도움이 되는지를 고려하며 설계해야 한다.
버거킹 택소노미를 설계하면서 나는 처음에 “이벤트를 최대한 많이 수집하는 것이 좋은 것 아닌가?”라는 생각을 했다. 하지만 이는 큰 착각이었다. 불필요한 이벤트를 줄이고, 필요한 이벤트만 남기는 것이 너무나 중요했다. 너무 많은 이벤트가 있으면 데이터가 복잡해지고, 분석 과정이 오히려 더 어려워지기 때문이다.

이벤트를 정의할 때 중요한 것은 단순히 많은 데이터를 쌓는 것이 아니라, 데이터가 실제로 분석에 활용될 수 있도록 구조적으로 설계하는 것이다. 그렇다면, 실무에서 효율적인 이벤트 설계란 무엇일까?
웹 및 앱에서는 다양한 이벤트가 발생하게 된다. 누군가는 제품을 검색할 수도, 추천 제품에 호기심을 가지고 해당 제품의 상세페이지를 확인할 수도, 장바구니에 담긴 제품들을 점검할 수도 있다. 그렇다면 우리는 발생할 수 있는 모든 경우의 수의 이벤트를 수집해야만할까? 당연히 그렇지 않다. 특히 Amplitude에서는 모든 이벤트를 수집하면 고객사가 어마어마한 비용을 지불하게 된다. 그럼 어떠한 이벤트를 잡아야 할까?
해답은 간단하다. 마케터의 관점에서 생각하는 것이다.
해당 이벤트를 수집하는 것이 마케팅의 측면에서 유의미할까?
해당 이벤트에서 수집한 정보를 바탕으로 마케팅 개선을 유도할 수 있을까?
버거킹 프로젝트에서는 다음과 같은 상황이 있었다. 사이드 추천 팝업을 닫을 때 “오늘 하루 추천 받지 않음”과 “닫기”의 두 가지의 버튼이 존재하였고, 이에 따라 이벤트를 구분하는 2가지의 시나리오가 발생하였다. 어떤 방법이 나아보이는가?
🍔 버거킹 프로젝트 - 사이드 추천 팝업 닫기

stop_side_recommend_button / close_side_recommend_buttonclosed_side_recommend_popup팀장님과 상의 후 내린 결론은 "해당 이벤트는 수집하지 않는다"였다. 이유는 마케팅적 관점에서 생각해보면된다.
사이드 추천 팝업으로 발생하는 정보로 활용할 수 있는 마케팅적 분석은 “추천에 대한 고객 전환율”이다. 다시 말해 마케터가 궁금한 것은 해당 팝업의 제품을 클릭하여 구매까지 이어지는 고객의 비율이며, 해당 팝업을 닫는 유저 비율을 만약 알고 싶다면 (1 - 추천에 대한 고객 전환율)을 통해 충분히 쉽게 파악할 수 있다. 따라서 사이드 팝업을 닫는 것에 대한 이벤트는 마케팅 관점에서 낮은 효용을 가지며, 해당 이벤트를 수집한다면 이는 의미없이 과도한 이벤트를 집계하는 것이 될 수 있다.
물론, 택소노미에 정답은 없다. 고객사의 다양한 니즈에 따라, 그리고 그로스 매니저의 판단에 따라 얼마든지 변화할 수 있기 때문이다. 예를 들어 버거킹에서 UI/UX 관점에서의 개발도 요구되는 상황이었다면, 시나리오 1번처럼 두 가지 이벤트를 별개로 수집하는 것이 필요했을지도 모른다. 택소노미의 본질은 데이터 분석을 위한 구조를 설계하는 데 있다. 즉, 수집되는 이벤트는 항상 분석 목적이 명확해야 한다. 단순히 “이벤트를 기록하면 좋을 것 같아서”라는 이유로 데이터를 쌓는 것이 아니라, 이벤트를 어떻게 활용할 것인지 먼저 정의한 후 수집해야 한다.
예를 들어, 설문조사를 설계할 때도 어떤 분석을 수행할 것인지 먼저 고려하고, 그에 필요한 질문을 구성한다. 마찬가지로, 택소노미 설계에서도 최종적으로 어떤 인사이트를 얻을 것인지 미리 정의한 후, 이를 달성하는 데 꼭 필요한 이벤트만을 수집하는 것이 중요하다. 이를 통해 불필요한 이벤트를 배제하고, 최적화된 구조를 설계할 수 있다. 다시 말해, “데이터를 수집하는 것”이 목표가 아니라, “데이터를 활용할 수 있도록 설계하는 것”이 목표가 되어야 한다.
버거킹 주문에는 “킹오더”와 “딜리버리오더”의 두 가지 타입이 존재한다. 킹오더는 직접 매장에서 식사하거나, 포장하는 등 대면을 통해 제품을 수령받아야하는 방식이며 딜리버리 오더는 제품을 지정된 주소로 배달받는 방식의 주문이다. 그리고 2023년도 택소노미에서는 두 가지 오더를 각각 k와 d로 구분하여 모든 이벤트를 분리 하였다.
예를 들어 제품의 상세페이지를 조회하는 이벤트인 item_detail_viewed를 킹오더 채널을 통한 경우라면 k_item_detail_viewed로, 딜리버리오더 채널을 통한 경우라면 d_item_detail_viewed로 구분하는 식이다. 그런데 해당 이벤트들을 처음 보자마자 가진 의문점이 하나 있었다.
이벤트 종류를 왜 이렇게 과도하게 많이 잡았을까?동일한 이벤트인데 굳이 왜 k와 d로 나누어 수집해야만 하는거지?
이벤트를 과도하게 세분화하는 것은 관리의 복잡성을 증가시키고, 데이터 분석의 일관성을 해칠 수 있다. 따라서 주문 유형을 구분해야 한다면, order_type을 이벤트 프로퍼티로 추가하는 것이 더 효율적이라고 생각했다. 이에 대한 해답을 찾기 위해 또다시, 팀장님을 찾아갔다.🥺
이유는 간단했다. 고객사가 생각하는 해당 이벤트의 중요도, 그리고 분석의 용이성 때문이었다. 택소노미는 그 자체가 목적이 아니라 후에 앰플리튜드를 활용한 데이터 분석 및 시각화에 사용되는 입력값이라는 것을 기억할 것이다. 따라서 택소노미는 고객사가 데이터를 쉽고 유용하게 활용할 수 있도록 작성되어야 한다.
예시를 들어보자. 다음은 버거킹 앰플리튜드 내 퍼널 차트 영역이다.


첫번째 사진의 차트는 k_item_list_viewed 이벤트를 실행한 유저 중 k_order_clicked 이벤트를 실행한 유저의 비율을 시각화하고 있다. 즉, [킹오더] 중에서 [아이템 목록을 조회한] 유저의 [주문하기 버튼 클릭] 전환율을 나타내고 있다.
현재는 오더의 종류를 k와 d 로 이벤트 상에서 구분해 놓았기 때문에 해당 차트를 제작하기 위해서는 [Events] 영역 내에서 이벤트를 클릭한 후 k_item_list_viewed, k_order_clicked 의 두 이벤트를 순차적으로 선택하면 된다. 만약 두 오더를 이벤트 상에서 구분하지 않고, 프로퍼티로 구분한다면 동일한 차트를 나타내기 위해서 어떻게 해야할까?

기존에는 두 번의 클릭으로 해당 차트를 만들어 낼 수 있었지만, 두 오더를 통합한다면 이벤트를 선택하고, 각 이벤트의 프로퍼티를 선택하고, 프로퍼티의 값을 선택하면서 총 6번의 클릭이 요구된다.
엥? 이게 왜 복잡하지. 그냥 클릭 좀 하면 되는거 아닌가?
위와 같이 생각할 수 있지만 고객사의 입장은 매우 다르다.
요식업에서 고객의 방문과 배달은 완벽히 분리되어있는 두 주요 구매 퍼널이고, 이에 따라 분석 시 통합된 하나의 분석보다 별개의 분석으로 나누어 보는 것이 더 유용한 인사이트를 제공한다.
마찬가지로 버거킹 입장에서 킹오더와 딜리버리 오더는 완벽히 구분하여 분석되어야 하는 두 가지의 구매 퍼널이다. 즉, 모든 분석에 기본적으로 두 오더가 구분되어야 하는데 모든 이벤트에 [+ Filter by]를 추가적으로 걸어주어야하는 구조라면 고객사의 마케터 입장에서 피로도는 매우 상승할 것이다. 또한 고객사의 모두가 택소노미와 앰플리튜드에 숙달되는 것은 매우 힘든 일이다. 만일 초보자가 이를 사용한다면 계속해서 가이드를 확인해야만 하며 이는 고객사 데이터 문해력을 저해하는 행위일 것이다.
쪼갰을 때 장점은 알겠어. 근데 합쳐서 보고싶다면? 전체 주문에 대한 전환율이 보고 싶을 때도 많잖아.
혹시 이런 생각을 했다면 당신은 나와 아주 그냥 똑같은 사람이다! 해당 질문에 대한 해답은 커스텀 이벤트(Custom Event)이다.
✅ 커스텀 이벤트(Custom Event) 생성법
: Amplitude에서는 두 가지 이상의 이벤트를 묶어서 볼 수 있는 커스텀 이벤트가 존재한다. 해당 커스텀 이벤트를 정의하면 이후에도 쉽게 이벤트를 불러올 수 있다.
1. [Combine events inline]을 통해 두 가지 이벤트를 삽입하기

2.[Save Custom Event]를 통해 두 이벤트를 하나의 이벤트로 묶기

3. 커스텀 이벤트를 생성할 수 있는 마케터가 되어보자!

계속해서 말했지만 택소노미에 정답은 없다. 그러나 왜 그렇게 택소노미를 구현했는지에 대하여 다른 사람을 설득할 수 있는 논리가 필요하다. 그리고 그 논리가 이번엔 고객사의 편의성이다.
이벤트 트리거에는 몇 가지 방식이 존재하지만, 주로 click과 view 가 활용된다. 버거킹 택소노미에서도 소수의 complete 트리거를 제외하고는 대부분의 이벤트가 click 혹은 view 로 트리거되었다.
신기한 점은 2023 버전 버거킹의 택소노미에는 유독 view 이벤트가 많았다는 것이다. view 이벤트는 어떨 때 활용하면 좋을까?
그러나 View 이벤트를 과도하게 사용하면 데이터 최적화에 문제가 생길 수 있다. 페이지를 로드할 때마다 트리거가 된다면 불필요한 이벤트가 대량으로 수집될 위험이 있기 때문이다.
따라서 특정 이벤트의 트리거를 view 로 잡는 것은 정보 수집 측면에서 하이 리스크, 하이 리턴 (High Risk, High Return)이 될 수 있으므로 우리는 이벤트 트리거를 설정할 때 view 의 효용성을 항상 생각해야 한다. 이에 따라 버거킹 택소노미의 일부 이벤트에도 변경점이 발생하였다.
이 과정을 통해서 무의미해진 기존의 6개의 이벤트는 삭제, 2개의 이벤트가 추가되면서 이벤트 패스의 최적화가 이루어졌다. 이처럼 트리거 방식 하나를 선택하는 것만으로도 데이터의 질과 분석의 신뢰도가 달라질 수 있다. 이벤트 설계에서 view 이벤트는 사용 목적이 명확할 때 신중하게 활용하는 것이 바람직하다.
관련 블로그글 링크
1부 : MZ 그로스 매니저의 택소노미 설계 꿀팁 대방출(1) (ft. 버거킹)
3부 : MZ 그로스 매니저의 택소노미 설계 꿀팁 대방출(3) (ft. 버거킹)

“택소노미요? 쭉 훑어봤는데 막 어렵지는 않더라고요. 빨리 끝내고 앰플리튜드 배우고 싶어요.”
입사 1주일 차, 입사 동기에게 실제로 했던 말이다. 택소노미의 개념적 이해는 어렵지 않았다. 평소 Python 코딩을 해왔기에 익숙한 개념들이 많았기 때문이다. 이벤트는 Class, 프로퍼티는 매개변수와 유사했다. 예를 들어, 아래는 brand, model, year를 매개변수로 받아오는 Car 클래스를 정의한 코드다.
class Car: # Car라는 클래스를 정의
def __init__(self, brand: str, model: str, year: int):
self.brand = brand
self.model = model
self.year = year
# Car 클래스에는 brand, model, year의 3가지 매개변수가 필요하다
택소노미 스키마 역시 이와 매우 유사한 형태를 띤다. 하나의 이벤트를 정의할 때 여러 프로퍼티를 필요로 하고, 이는 데이터 분석의 기본 단위가 된다. "택소노미, 쉽네?"라고 생각했다.
그러나 그건 내가 택소노미의 표면만을 보았기 때문이었다. 실제로 설계를 시작하자 복잡한 이벤트 간의 관계, 속성 간의 상호 의존성, 퍼널의 다양성, 그리고 각기 다른 상황에서 어떤 이벤트를 발생시켜야 하는지에 대한 고민들이 쏟아져 나왔다. 택소노미는 단순한 데이터 구조 설계가 아니라 비즈니스 로직과 사용자 행동을 체계적으로 모델링하는 과정이었다.
사실, 버거킹은 마티니에서 이미 2023년에 한 차례 앰플리튜드 택소노미를 구축한 경험이 있었다. 하지만 이후 앱이 계속해서 리뉴얼되면서 기존 택소노미와 실제 어플 사용경험이 점점 맞지 않게 되었다. 그 결과, 2025년을 맞아 새롭게 택소노미를 리뉴얼할 필요가 생겼다. 버거킹 측에서는 원하는 이벤트 목록을 추가하여 약식의 택소노미를 제공해 주었고, 이를 바탕으로 2025년 버전의 이벤트 패스와 택소노미를 새롭게 설계해야 했다. 그러나 이 과정에서 가장 큰 난관이 있었다. 버거킹과의 직접적인 인터뷰가 불가능했다. 즉, 내가 가진 정보는 제한적이었고, 단순히 제공된 문서만으로는 버거킹의 데이터 분석 및 비즈니스 로직 니즈를 100% 이해하는 것이 어려운 상황이었다. 그 결과, 작은 결정 하나를 내릴 때마다 "이게 정말 맞는 방식일까?"라는 고민을 끊임없이 해야 했다.
그렇게 머리가 터질 것 같은 열흘간의 '버거킹 택소노미' 설계를 거치고, 팀장님을 붙들고 질문 폭격을 쏟아낸 끝에, 나는 택소노미 설계를 위한 몇 가지 실무적인 팁을 정리할 수 있었다. 나처럼 처음 택소노미를 구축하려는 사람들에게 작은 도움이 되길 바라며, 내가 직접 부딪히며 배운 교훈들을 재미있게 공유하려 한다.
우선적으로 해야 할 일은 이벤트 + 이벤트 프로퍼티를 고려한 이벤트 패스 및 이벤트 택소노미를 작성하는 것이다.
이벤트 패스는 고객사의 웹사이트나 앱을 직접 사용해보면서 분석에 유용한 정보를 담고 있을 이벤트를 찾아 마인드맵 형태로 작성하는 과정이다. 이는 고객이 경험하는 유저 여정을 체험하며 퍼널의 연결성을 파악하는 행위이며, 각 페이지에서 어떤 이벤트가 발생하고, 어떤 정보를 수집해야 할지를 개괄적으로 이해하는 데 도움을 준다.

이벤트 택소노미는 이벤트 스키마 설계서와 동일한 의미를 갖는다. 즉, 이벤트를 어떤 기준으로 쌓아서 볼 것인지 정의하는 문서이다.
문제는 날이 갈수록 구매 퍼널이 다양해지고 유저 여정이 복잡해지는 등 앱의 절차가 점점 더 복잡하고 무거워지고 있다는 점이다. 그러나 이 모든 퍼널에 대하여 이벤트를 계속해서 추가할 수는 없다. 새로운 이벤트가 지나치게 많아지면 데이터 분석이 어려워지고, 이벤트 프로퍼티가 불필요하게 늘어나면서 데이터의 일관성이 깨질 수 있기 때문이다. 또한 이벤트 패스와 택소노미를 작성할 때 고려해야 할 부분이 너무 많다. 예를 들어
이 모든 요소를 고려하면서 설계를 진행하다 보면, 무엇이 우선순위인지, 어디까지 초기에 디테일하게 구상해야 하는지 갈피를 잡기가 어려워진다. 그렇다면, 효율적인 택소노미 설계를 위해서는 어떻게 해야 할까?
처음 이벤트 패스를 작성할 때 나는 처음부터 완벽하게 정리하고 싶었다. 오류나 빈 곳을 발견하고 나중에 고치는 것이 더 피곤한 일이라고 생각했기 때문이다. 그래서 처음부터 모든 화면을 다 들어가 보고, 설정, 멤버십, 쿠폰, 프로모션 등 버거킹 앱 내의 모든 이벤트를 고려하려 했다.
하지만 이렇게 모든 요소를 한 번에 설계하려고 하면 일이 지나치게 복잡해지고 진행 속도가 늦어진다. 중요한 것은 우선 고객의 유저 경험에서 굵직한 이벤트만 먼저 파악하는 것이다.
이 당연한 흐름을 먼저 기억했다면, 해당 전환이 일어나는 주요 화면을 중심으로 캡처하고 뼈대를 만들었을 것이다. 이후에 디테일을 보완하면 충분했다.
주요 이벤트 패스를 작성하는 것은 글을 쓸 때 개요를 먼저 정하는 것과 같다. 개요 없이 글을 쓰면 무조건 중구난방으로 튀게 되어있다. 이벤트 패스와 택소노미 역시 마찬가지다. 전체 그림을 볼 수 있어야 다른 곳으로 빠지지 않고 효율적인 설계를 할 수 있다. 만약 처음부터 세부 이벤트와 각 이벤트에서 수집하는 모든 프로퍼티를 고려한다면, 눈 앞에 거대한 나무에 가로막혀 전체 숲을 보지 못하고 길을 헤매게 될 것이다. 세부적인 이벤트에 매몰되지 말고 전체 흐름을 봐야 한다!
사실 이 장은 1.1과 연결된 내용이다. 앞서 이야기했듯이, 이벤트 패스를 작성할 때 가장 먼저 해야 할 일은 메인 퍼널을 정의하고 그리는 것이다.
버거킹의 경우, 주문으로 이어지는 퍼널이 정말 많았다.
각 퍼널별로 유입할 수 있는 경로도 다양했다. 예를 들어, 배너 클릭만 해도 5군데 이상에서 유입 가능했고, 무한 반복의 사이드 제품 추천시스템도 있었다. 이 모든 퍼널을 하나의 이벤트 패스 안에 그려 넣는다면? 패스가 지나치게 복잡해지고 직관성이 떨어질 것이다. 처음에 내가 작성한 1차 버전의 이벤트 패스는 정말 끔찍했다. 선들이 얽히고설켜 있고, 순환구조까지 포함되어 혼돈 그 자체였다. 그래서 내린 결론은 퍼널을 분리하고, 연결 지점만 정의하는 것이었다.
🍔 버거킹 프로젝트 - 메인퍼널과 서브퍼널의 분리
1. 우선 메인 퍼널을 정의한다: 홈화면 → 매장 선택 → 버거 선택 → 장바구니 → 결제

2. 다른 구매 퍼널을 별도의 페이지에 따로 정의하고, 메인 퍼널로 합류하는 지점을 설정한다.
- 예시: banner_clicked → event_detail_viewed → 주문하기 버튼 클릭 시 메인퍼널로 합류

3. 반복해서 퍼널별로 개별 페이지를 제작하고, 메인 퍼널과의 연결성을 시각적으로 정리한다.

이렇게 구매 전환 퍼널들을 분리하니 복잡했던 경로도 훨씬 단순화되었다.
또한, 지나치게 세세하게 이벤트 패스를 만들 필요는 없다. 사이트 내 모든 페이지를 캡처할 필요는 없으며, 유의미한 이벤트가 발생하는 화면만 정리하는 것이 훨씬 효과적이다. 예를 들어, 버거킹의 제품 추천 시스템은 무한 루프(?)를 형성한다. 고객이 장바구니에 제품을 담으면, 사이드 제품을 팝업으로 추천하고 이를 장바구니에 담으면 또다시 사이드를 추천하는 형식이다.

이러한 사이드 추천 페이지를 다 표현할 것인가? 언제까지, 몇 번째 추천까지 표현할 것인가. 반복되거나 무의미한 화면은 무시하는 것이 효율적인 이벤트 패스이다!
앞서 내가 이벤트 패스가 글의 개요 역할을 한다고 했으니, “이벤트 패스를 먼저 완성하고 나서 택소노미 시트를 작성하면 되겠다”고 생각했을 것이다. 나 역시도 그렇게 생각하였고, 서둘러서 이벤트 패스를 완성하고자 했다. 그러나 얼마 가지않아 또다시 문제에 직면하게 되었다.
예를 들어, 버거킹의 Main 퍼널에서는 후기 이벤트가 앞선 이벤트의 거의 모든 프로퍼티를 상속한다. 즉, order_completed 이벤트 하나만 해도 40개가 넘는 프로퍼티를 포함해야 했다.
“대체 어떤 프로퍼티들이 상속되고, 새로 추가되는거지?”
이 질문은 계속해서 반복되었고, 이벤트 패스만 보고는 도무지 답을 내릴 수 없었다. 특정 이벤트에서 어떤 프로퍼티를 유지하고, 어디서 새로운 프로퍼티를 추가해야 하는지 등이 정리되지 않으니 택소노미가 구체화되는 느낌을 받을 수가 없었다. 그래서 내린 결론은 이벤트 패스와 택소노미 시트를 병행하며 작업하는 것이었다.

이벤트 패스를 작성하면 전체적인 사용자 플로우를 한눈에 볼 수 있지만, 개별 이벤트가 수집해야 하는 데이터까지 파악하기는 어렵다. 반면, 택소노미 시트를 작업하면 각 이벤트별 데이터 정의를 체계적으로 정리할 수 있지만, 전체적인 흐름 속에서 프로퍼티의 연결성을 파악하기 어렵다. 결국, 두 작업은 병행되어야만 했다.
1. 이벤트패스를 통해 주요 이벤트를 퍼널 순서대로 정의
2. 도출된 이벤트들을 우선적으로 시트에 정리 - [Event List] 시트

3. 시각적인 이벤트 패스를 확인하며, 이벤트 별 프로퍼티 정의 - [Event별 Property] 시트
: 프로퍼티의 상속을 고려하며, 이벤트의 순서대로 프로퍼티 추가

4. 프로퍼티가 정의될 때 프로퍼티 상세 내용 고려 - [Event Property 상세] 시트
: 프로퍼티의 타입, 예시 값 추가

5. 택소노미 시트 보완: 프로퍼티 간 중복/누락 여부 점검 및 일관성 유지
6. 업데이트된 정보를 반영하여 이벤트 패스 조정 : 변경된 이벤트를 반영, 불필요한 프로퍼티 제거
물론, 택소노미 시트가 최종적으로 완성해야 할 결과물이지만, 두 과정이 결코 따로 분리된 것이 아니라는 것을 상기했으면 좋겠다. 이벤트 패스는 택소노미 시트 제작에 도움을 주고, 또 다시 택소노미 시트는 이벤트 패스의 완성 및 구조화를 도와준다.
관련 블로그글 링크
2부 : MZ 그로스 매니저의 택소노미 설계 꿀팁 대방출(2) (ft. 버거킹)
3부 : MZ 그로스 매니저의 택소노미 설계 꿀팁 대방출(3) (ft. 버거킹)


엑셀과 스프레드시트를 어느정도 다루시던 분들은 조건부 서식에 어느정도 익숙하실 겁니다.
조건부 서식은 데이터를 보다 효과적으로 표현하고 분석하는 강력한 기능입니다. 이는 특정 조건에 따라 셀의 모양(글자 색상, 셀 색상)을 자동으로 변경하여 중요한 정보를 시각적으로 돋보이게 만드는 기능입니다.

위의 이미지 예시를 보면 더 쉽게 이해할 수 있습니다. 왼쪽은 아무런 설정을 하지 않은 차트라면 오른쪽은 숫자의 백분위수를 기준으로 색상을 표현하였습니다. 오른쪽의 표가 일자별 노출수의 차이를 훨씬 쉽게 이해할 수 있습니다.
조건부 서식의 가장 큰 특징은 데이터에 기반한 동적인 시각화입니다. 사용자가 정의한 규칙에 따라 데이터가 변경될 때마다 서식도 자동으로 업데이트됩니다. 이는 단순히 정적인 색상이나 서식을 적용하는 것과는 다르게, 항상 최신 데이터를 반영한 시각적 표현을 제공합니다.
루커스튜디오와 같이 실시간으로 변하는 데이터 시각화 솔루션에서는 필수적으로 활용하면 좋을 기능입니다.
루커스튜디오에도 이러한 조건부 서식이 있으며 다른 엑셀과 Tableau와 같은 BI와 유사한 기능을 사용할 수 있습니다.
기본적으로 'Tablea' 차트와 'Score' 차트에서 활용가능합니다.

단색과 색상스케일에 따라 구분할 수 있습니다. KPI 달성이나 임계값 달성에 대한 강조를 원한다면 단색 유형이 유용합니다. 반면에 데이터의 양이 많고 데이터간 상대적 차이가 중요하다면 색상 스케일이 유용합니다.

규칙별로 하나의 조건만 가능하며 조건 형식은 셀 또는 전체 행에 적용할 수 있습니다.






대부분의 비즈니스 문제는 두 가지 이상의 데이터 소스들을 결합하여 바라봐야 의미 있는 인사이트를 도출 할 수 있습니다. 광고데이터와 성과데이터, 매출데이터와 쿠폰데이터, 사용자데이터와 행동데이터 등과 같은 여러 데이터 조합들이 존재합니다.
루커 스튜디오의 기능 중 하나인 데이터 혼합은 두 가지 이상의 데이터간 결합을 제공하는 기능으로 데이터 시각화 및 분석을 더욱 풍부하게 만들어줍니다.
이러한 데이터 혼합 방식은 루커 스튜디오만의 방식은 아닙니다. 이미 데이터를 처리하는 데이터베이스 분야에서는 널리 사용 되고 있습니다.

이번 시간에는 루커 스튜디오 데이터 혼합 기능에 대해 배워보고 루커 스튜디오의 대시보드를 더 깊이 있게 만들어봅시다.
데이터 혼합 방식을 처음 접한 분들은 개념이 생소할 수 있습니다. 뿐만 아니라 이미 SQL 등을 공부하면서 혼합 방식을 알고 계셨던 분들도 혼합은 헷갈리는 개념입니다. 먼저 루커 대시보드를 가지고 혼합에 대한 개념을 가볍게 살펴보도록 하겠습니다.
루커 스튜디오가 제공하는 5가지 조인방식을 동일한 데이터를 가지고 혼합하였을 경우 혼합된 최종 결과 데이터가 어떻게 구성되는지 시각적으로 본다면 이해가 좀 더 편할 것입니다. 아래의 이미지에 각 혼합 방식에 따른 결과 테이블을 살펴보실 수 있습니다.

먼저, 루커 스튜디오 데이터 혼합에 대한 기본적인 내용을 알아보겠습니다. 데이터 혼합은 최대 5개의 데이터 소스를 조합하여 차트를 생성하는 기능을 제공합니다. 이를 통해 서로 다른 데이터 소스 간 측정항목과 측정기준을 조합한 새로운 차트를 만들 수 있습니다. 데이터 혼합을 통해 다양한 데이터 소스의 구성을 효과적으로 활용할 수 있습니다.
1) 기본 : 리소스 → 혼합 소스 관리 클릭 후 데이터 혼합

2) 설정탭 이용 : 설정탭 내 데이터 소스 → 데이터 혼합 클릭

3) 차트 이용 : 두 개 이상의 차트를 선택하고 데이터 혼합 생성

혼합 데이터는 루커 스튜디오의 데이터 혼합 부분에서 새롭게 만들거나 업데이트를 합니다. 해당 화면과 데이터 혼합에 대한 기본적인 구성을 살펴봅시다.




왼쪽 조인 유형은 가장 기본적인 조인 유형입니다. 왼쪽 테이블을 기준으로 모든 행을 반환하고 오른쪽 테이블은 왼쪽 테이블 조인 키값과 일치하는 행만 반환합니다.
ㅤ
오른쪽 테이블에 존재하지 않거나 누락된 값은 최종 혼합 데이터에서 빈칸 혹은 null 값으로 표현됩니다.


라이트 아우터 조인 유형은 왼쪽 조인과 반대로 오른쪽 테이블을 기준으로 왼쪽 테이블을 모두 반환합니다. 테이블이 반대일 뿐 왼쪽 조인과 동일한 원리 입니다.
활용
2개의 보완적인 데이터 소스로 하나의 데이터 소스를 만드는 경우에 활용 가능합니다. 예를 들어 아래와 같이 매출 데이터 소스를 확장하기 위해 한쪽에는 유저 소스를 레프트 조인으로(키값은 유저 ID), 다른 한쪽에는 제품 정보 소스(키값은 판매 상품)를 넣어서 매출 데이터 분석을 더욱 풍부하게 만들 수 있습니다.


ㅤ
ㅤ

내부 조인은 두 테이블 조인 조건 모두에서 일치하는 행만 반환합니다. 각 데이터 세트의 다른 모든 행은 제거됩니다.
두 데이터 소스 간 중복에 관련한 분석을 하는 경우 많이 사용합니다. 또한 동적 데이터로 데이터 세트를 필터링하는 쉬운 방법입니다.
ㅤ
활용

ㅤ
ㅤ

외부 조인은 조인 조건이 충족되지 않더라도 두 테이블의 모든 행을 반환합니다.
활용
데이터베이스(1st party data)와 GA4(3rd party data)를 연결하며 데이터베이스에서 삭제된 데이터가 GA4에서 확인 가능하며 GA4에서 추적되지 않은 값이 데이터베이스에서 확인 가능합니다. 이처럼 양쪽의 환경을 모두 고려해야 하면서 서로의 데이터가 모두 필요한 경우 사용합니다.

ㅤ
ㅤ

교차 조인은 모든 테이블 행의 데카르트 곱(두 소스의 모든 구성요소의 순서 쌍)을 반환합니다.
즉, 왼쪽 데이터 세트의 모든 행은 반복을 통해 오른쪽 데이터 세트의 모든 행과 곱해져서 데이터를 반환합니다.
이는 조인 키가 필요하지 않은 유일한 조인 유형입니다.
ㅤ
활용
데이터의 각 행 별 조인이 필요한 경우에 사용합니다.

데이터 혼합의 조인 조건을 잘 활용한다면 분석을 더욱 풍부하게 만들어주는 게임 체인저가 될 수 있습니다.
이러한 기능을 활용하기 위해서는 처음에는 까다로울 수 있지만 연습해서 여러분들 것으로 만든다면 멋진 대시보드를 만드시는데 도움이 되실 겁니다.

데이터마케팅이란 [데이터]를 활용하여 마케팅한다는 뜻으로 데이터드리븐마케팅(Data-driven Marketing)으로도 불릴 수 있습니다.
데이터마케팅과 데이터드리븐마케팅의 차이는 미미하나, 데이터마케팅은 데이터를 [활용] 하나 데이터 드리븐 마케팅은 데이터를 [기반]으로 하기에 후자에서 데이터의 중요성이 좀 더 강조된다고 볼 수 있습니다.
데이터마케팅을 위해서 필수 조건은 (당연하게도) 데이터 분석입니다. 결괏값을 측정하여 데이터를 잘 쌓아두고, 보유한 데이터를 가공하여 상황을 해석하고 문제나 개선점에 대한 인사이트를 도출하는 것이 기본적인 데이터 마케팅의 프로세스라고 할 수 있습니다.
그로스 조직(=그로스팀)은 기본적으로 데이터 드리븐 마케팅을 하기에, 프로세스가 같습니다.
데이터를 기반으로 가설을 세우고, 실험을 바탕으로 검증하고, 배움을 축적하는 과정을 빠르게 반복합니다. (*출처: 양승화 님의 그로스해킹)
![양승화 님의 [그로스해킹] 책을 기반한 이미지 | 그로스 조직이 일하는 방식](https://cdn.prod.website-files.com/656d3c53a795ed37cbbc9e32/66ceb8add44db997abca7b19_66ceb78b6a2e8955782324a8_%25EB%258D%25B0%25EC%259D%25B4%25ED%2584%25B0%25EB%25A7%2588%25EC%25BC%2580%25ED%258C%25851.jpeg)
마티니에서 진행한 컨설팅 프로젝트였던, 패션 커머스를 기준으로 데이터마케팅의 사례를 보겠습니다.
커머스 내에서도 여러 안건의 데이터 분석이 있는데요. 1. 에디토리얼(=콘텐츠), 2. 프로모션 간의 비교 (미드세일 vs 시즌오프세일), 3. 주요 대시보드 (KPI, AARRR) 4. 특정 프로모션 (블랙프라이데이) 등입니다.

블랙프라이데이 프로모션을 세부 사례로 앰플리튜드(Amplitude)를 활용했던 분석을 예시로 들어보겠습니다.
*앰플리튜드는 SaaS(Software as a Service: 클라우드 기반의 소프트웨어 제공 모델) 솔루션으로 웹/앱 서비스 내의 사용자 행동 분석을 할 수 있는 프로덕트 애널리틱스(Product Analytics)입니다.

왜 프로모션 데이터 분석을 해야 할까요? 그 배경부터 먼저 짚고 넘어갑시다.
다양한 형태로 스스로에게 질문을 해봅니다.
Q. 프로모션을 기획하고 운영한 후 가장 궁금한 것은?
Q. 프로모션을 운영한 이유는 무엇일까요?
여러 가설을 세워봅니다.
이렇게 물어보면, 보통은 '셋 다'라고 대답하는 경우가 많은데요. 충분히 이해는 하지만(^^...!) 우선순위는 정해야 합니다. 대개 우선순위는 [매출]이기에, 매출 관련 분석을 먼저 진행합니다.
매출의 기본적인 구성 요소를 먼저 파악합니다.
*건단가와 객단가
건단가와 객단가는 혼용되어 쓰이기도 하는데요. 주문[건]의 건, 고[객]의 [객]을 생각하시면 됩니다.
즉 어제 제가 배민에서 점심 주문 건으로 1.5만 원을 쓰고 저녁 주문 건으로 2.5만 원을 썼다면 일 기준 제 건단가는 [1.5만 원] / [2.5만 원] 두 건일 것이고 제 객단가는 [1.5만 원]+[2.5만 원]의 4만 원이 될 수도 있습니다.
*물론 건단가와 객단가는 내부적으로 정의하기 마련입니다! 일간 건단가를 평균으로 낼 수도 있으니까요.
이에 따라 앰플리튜드(Amplitude)에서 매출, 주문수/건단가, 구매자수/객단가로 그래프를 구성합니다. 우선 매출로 전체적인 추이를 보고 주문수/건단가, 구매자수/객단가를 개별로 쪼개보는 것이죠.

해당 프로모션에서는 객단가와 건단가가 유사한 추이를 보이기에 특이 사항이 없다고 판단되었지만, 가끔 특정 프로모션에서 객단가와 건단가의 차이가 크게 발생하는 경우도 있습니다. (리셀러의 등장?!)
이외 위 그래프에서 두 개의 선이 있는데요. 데이터를 볼 때의 꼭 필요한 [비교 기준]입니다. 비교 기준은 사용자 특성이 될 수도, 행동이 될 수도 있지만 [기간]을 가장 기본적으로 고려합니다.
*비교 기준: 기간(일간, 주간, 월간, 분기, 반기, 연간… 시즌성 고려!
블랙프라이데이 프로모션의 분석이라면 전년도 11월과 비교하는 것 vs 전월인 10월과 비교하는 것 - 어떤 것이 더 합리적일까요? 당연히 전년도일 것입니다.
전월 10월과 당월 11월의 할인율, 마케팅 수준 등이 다를 테니까요. 물론 전년 대비 회원수도 브랜드수도 많아졌고 등의 변동 요인들이 많아 YoY만 비교하는 것이 의미가 없다고 판단된다면 결국 전년도(YoY)/전월(MoM)/전주(WoW) 등 비교 대상들이 많아질 수 있습니다.
현대의 직장인이라면 대개 모든 업무의 결과를 [숫자]로 보긴 합니다. 그렇다면 그냥 숫자를 확인하는 것과 데이터 분석의 가장 큰 차이점은 무엇일까요?

예를 들어 2024년 7월 A 커머스의 구매 전환율 (메인 페이지 조회 > 결제 완료)이 10%라고 했을 때, 어떤 해석을 할 수 있을까요?
전월 대비 높아졌다/낮아졌다, 전년 대비 높아졌다/낮아졌다의 판단을 위해서는 전월 데이터, 전년도 데이터가 필요합니다.
전년, 전월, 전주의 데이터를 보며 추이를 확인했을 때 눈에 띄게 높거나/낮은, 혹은 변동이 생기는 시점을 찾아내어 그 배경이 무엇이었는지 파악하는 것이 필요합니다.
혹은 유사한 프로모션이 진행되었던 시기와 비교하여 구매전환율이나, 구매수, 유입수, 가입수 등의 주요 지표에서 차이가 있었는지를 파악해 보는 것도 좋습니다.
프로모션 vs 프로모션 간의 비교 외에도 uiux를 개선하거나 특정 기능을 배포했을 때 그 시점 이후의 변화가 있는지를 확인할 수 있습니다.

매출을 구매수와 건단가, 구매자수와 객단가로 나눠 전반적인 추이를 파악한 후 세부 분석을 진행합니다.
매출은 결국 [사용자]가 [상품]을 [구매]하여 발생하는 결괏값입니다. 이에 따라 [사용자]와 [상품]의 측면에서도 분석을 진행합니다.

: 카테고리별, 브랜드별, 상품별 매출 추이

프로모션의 매출을 브랜드, 카테고리 등으로 나눠서 확인해 봅니다.

더 개별적으로는 브랜드를 기준으로 매출과 월별 성장률 등을 확인하며 주요 브랜드를 도출하기도 합니다.
프로모션을 진행하고 쌓인 데이터를 분석하고 회고하고 다음 프로모션에 적용하는 것. 그것이 프로모션 측면에서 데이터를 활용한 데이터 마케팅이라고 볼 수 있습니다.
이외 데이터마케팅은 어떤 부문에도 동일하게 적용됩니다. 정량적인 수치로 표현되는 데이터를 쌓고, 데이터를 여러 측면에서 분석하고, 다음 유사 업무 시 배운 점을 적용하고 또 실험하는 것입니다.


MRR 이란?
Monthly Recurring Revenue로 월간 반복 매출 구독형 서비스의 경우 핵심 지표로 활용됩니다.
요즘은 누구나 한 번 쯤은 구독형 서비스를 결제해본 경험이 있을텐데 구독 비즈니스는 사용자가 카드를 등록하면 자동으로 월마다 반복적으로 자동결제가 됩니다. (유튜브 프리미엄 구독, 넷플릭스 등)
MRR 산출 공식은 다음과 같습니다.
예를 들면, 유튜브 프리미엄 월 구독 비용이 10,000원이고 이용자가 10명이라면 MRR 은 100,000원이 되는 겁니다.
그런데 MRR이 100,000원 입니다. 에서 끝나면 안되겠죠?
MRR이 어떻게 변화했는지를 분석하는 것도 굉장히 중요합니다.
MRR 지표를 쪼개보면 아래와 같습니다.
그러면 이 지표를 가지고 우리는 New MRR을 구할 수 있습니다.
실무하면서 MRR calculation 하는데 고생 고생을 했는데 이 방법으로 도움을 받을 수 있는 누군가를 위해 공유합니다.
우선 방법은 DB에 적재된 결제 데이터와 구글 스프레드 시트에서 세금계산서로 처리되는 고객 결제 내역을 바탕으로 Rawdata를 준비하고 파이썬을 활용해서 frequency(월결제, 연결제)를 flatten 해주고 이를 Looker Studio로 시각화해줍니다.
1. DB에서 데이터 불러오기
2. 구글 스프레드시트에서 데이터 불러오기
3. 파이썬으로 데이터 클렌징하기
4. 클렌징한 DB, 스프레드시트 데이터 합치기
5. 클렌징 결과 시각화를 위해 구글 스프레드시트로 보내기
6. Looker Studio로 시각화 하기
아래는 실제 활용했던 MRR 대시보드 입니다.
첫 번째 대시보드는 월매출과, MRR 지표 현황을 살펴보고 고객사별 월간 구독 현황을 확인 해볼 수 있고 ARR, 이번달 예상 매출도 확인 할 수 있게 구성했었습니다.

두 번째 대시보드는 위에서 언급한 대로 MRR 지표를 쪼개서 모니터링하는 대시보드입니다.
이를 통해 MRR 상승하는데 어떤 지표 때문에 상승했는지 한눈에 볼 수 있습니다. 또한 MRR 성장추이도 함께 볼 수 있도록 구성되었습니다. 이제 이 대시보드를 통해서 전사가 우리 서비스의 MRR 현황을 볼 수 있고 이탈한 유저수가 특히 많았던 월에는 고객 인터뷰를 진행해보거나 해당 유저들의 특징을 파악해보면 어떤 지점에서 불편함을 느꼈는지 페인 포인트는 무엇이었는지 원인을 파악하고 제품 개선에 반영해볼 수 있겠죠?

DB에서 결제 데이터를 위의 컬럼만 파이썬 SQLAlchemy 를 활용해서 데이터를 불러옵니다.
SELECT
user_id,
company_name,
sales,
pay_datetime_id,
freq,
user_status
FROM
(SELECT tmp2.user_id,
tmp2.company_name,
tmp2.id,
tmp1.sales,
date_format(tmp1.auth_date, '%Y-%m-01') auth_date,
tmp1.subscription_id,
tmp1.user_status,
tmp1.card_updated_at
FROM
(SELECT B.user_id,
A.sales,
A.auth_date,
A.subscription_id,
A.user_status,
A.card_updated_at
FROM
(SELECT st0.*,
st1.user_status,
st1.card_updated_at
FROM
-- billing_payment_history 테이블에서 조건에 맞는 데이터 가져오기
(SELECT billing_id,
subscription_id,
auth_date,
IF(cancelled_at IS NULL ,amount, IF (amount <= cancellation_cancel_amount,0,cancellation_remain_amt)) AS sales
FROM nicepay_billing_payment_history
) st0
left join
-- nicepay_card_info 테이블에서 가장 최근의 카드 정보(created_at이 최대인)를 가져오며, user_status를 is_deleted와 is_active 값에 따라 ‘churned_user’ 또는 ‘active_user’로 설정
(select t1.billing_id,
t1.created_at,
t1.is_deleted,
t1.is_active,
t1.created_at card_updated_at,
(case when t1.is_deleted = 1 and t1.is_active = 0 then 'churned_user' else 'active_user' END) user_status
from nicepay_card_info t1
inner join (select billing_id,
max(created_at) max_date
from nicepay_card_info
group by 1) t2
on t1.billing_id = t2.billing_id and t1.created_at = t2.max_date) st1
ON (st0.billing_id = st1.billing_id)) A
LEFT OUTER JOIN
(SELECT billing_id,
user_id
FROM nicepay_billing_info) B
ON (A.billing_id = B.billing_id)) tmp1
INNER JOIN (SELECT user_id,
company_name,
id
FROM user
) tmp2
ON (tmp1.user_id = tmp2.user_id)) tmp3
inner join
(select seq,
freq,
date_format(plan_start_datetime_id, '%Y-%m-01') subscription_plan_start_datetime_id
from subscription) tmp4
ON (tmp3.subscription_id = tmp4.seq)
where sales > 0;
먼저 계산을 위해 필요한 데이터를 DB에서 추출해주고 flatten을 해줄껍니다.
flatten이 뭐냐 뜻 그대로 평탄화한다는 의미입니다. 예를들어 고객이 연간 결제를 1,200,000원을 했다고 하면 월별 결제액은 12개월로 나눠서 월별로 데이터를 평탄화 해주는 과정이라고 보시면 됩니다.
#expand the yearly records
mrr_base = mrr_df.loc[np.repeat(mrr_df.index, mrr_df['freq'].map({"years":12,"months": 1}))]
mrr_base.loc[mrr_base["freq"] == "years", "sales"] /= 12
mrr_base.loc[mrr_base["freq"] == "years", "pay_datetime_id"] += \
mrr_base.groupby(["user_id", "freq"]).cumcount().loc[mrr_base["freq"] == "years"]\
.map(lambda i: pd.DateOffset(months=i))
저의 경우 DB에 기록되지 않은 세금계산서 데이터를 가지고 있었는데
해당 데이터는 구글 스프레드시트에 기록하고 있으므로 구글 스프레드시트에서 데이터를 불러옵니다.
#구글 스프레드시트에서 data load하기
scope = ['https://spreadsheets.google.com/feeds',
'https://www.googleapis.com/auth/drive']
credentials = ServiceAccountCredentials.from_json_keyfile_name(
'credential 파일 경로(json파일)', scope)
gc = gspread.authorize(credentials)
spreadsheet_url = "가져올 스프레드시트 주소"
gc1 = gc.open_by_url(spreadsheet_url).worksheet('시트 이름')
#기존에 기록된 데이터 가져와서 리스트 형태로 리턴
gc2 = gc1.get_all_values()
#데이터프레임으로 판다스로 가져오기
gc2 = pd.DataFrame(gc2, columns=gc2[0])
gc2 = gc2.reindex(gc2.index.drop(0))
#날짜 형식으로 변경
gc2['pay_datetime_id'] = pd.to_datetime(gc2['pay_datetime_id'])
#sales 컬럼 숫자로 변경
gc2['sales'] = gc2['sales'].astype(str).astype(int)
#expand the yearly records
gc2_base = gc2.loc[np.repeat(gc2.index, gc2['freq'].map({"years":12, "months": 1, "2years":24}))]
# compute monthly fee and join date
#years 12개월로 나누기
gc2_base.loc[gc2_base["freq"] == "years", "sales"] /= 12
gc2_base.loc[gc2_base["freq"] == "years", "pay_datetime_id"] += \
gc2_base.groupby(["user_id", "freq"]).cumcount().loc[gc2_base["freq"] == "years"] \
.map(lambda i: pd.DateOffset(months=i))
#2years 24개월로 나누기 / years 12개월로 나누기
gc2_base.loc[gc2_base["freq"] == "2years", "sales"] /= 24
gc2_base.loc[gc2_base["freq"] == "2years", "pay_datetime_id"] += \
gc2_base.groupby(["user_id", "freq"]).cumcount().loc[gc2_base["freq"] == "2years"] \
.map(lambda i: pd.DateOffset(months=i))
gc2_base_result = gc2_base[['user_id', 'company_name', 'sales', 'pay_datetime_id', 'freq']]
출처: https://botongsaram.tistory.com/entry/B2B-SaaS-MRR-계산하기 [알랭드보통사람:티스토리]
위의 과정에서 DB에서 불러온 데이터와 구글 스프레드시트의 데이터 형태를 통일 시켰습니다.
이제 Raw Data를 만들기 위해서 합쳐줍니다.
#구글시트rawdata와 DB에서 불러온 데이터의 결합
df_union= pd.concat([mrr_result, gc2_base_result])
데이터를 통합한 다음에 데이터 시각화를 위해 데이터 시각화를 위해 스프레드시트에 최종 정리된 데이터를 다시 구글 스프레드시트로 전달합니다.
# union 된 결과를 다시 구글 스프레드시트로
scope = ['https://spreadsheets.google.com/feeds',
'https://www.googleapis.com/auth/drive']
credentials = ServiceAccountCredentials.from_json_keyfile_name(
'credential 파일 경로(json)', scope)
gc = gspread.authorize(credentials)
spreadsheet_url = '스프레드시트주소
gc_mrr = gc.open_by_url(spreadsheet_url).worksheet('새로 데이터를 업로드할 시트명')
#기존에 기록되어 있던 데이터 삭제(처음 업로드할 때는 필요 없음)
gc_mrr.clear()
# 오늘 가져온 데이터 업로드
gd.set_with_dataframe(gc_mrr,merge)
위의 결과는 MRR 대시보드 예시(1)에서 활용했던 과정입니다.
다음으로 MRR detail view 에 사용될 지표를 만들 차례입니다.
# pay_datetime_id 열에서 월과 연도를 추출하여 새로운 열 생성
mrr_detail_result['month_year'] = mrr_detail_result['pay_datetime_id'].dt.to_period("M")
# max_date 컬럼 만들기
mrr_detail_result['max_date'] = pd.NaT
mrr_detail_result.head()
# user_id를 기준으로 그룹화
grouped = mrr_detail_result.groupby('user_id')
# 각 그룹에서 최대 결제일을 찾고 max_date 열에 할당
for name, group in grouped:
max_date = group['pay_datetime_id'].max()
max_index = group['pay_datetime_id'].idxmax()
mrr_detail_result.loc[group.index, 'max_date'] = max_date
# 데이터프레임을 corporate_id와 pay_datetime_id 기준으로 정렬
transactions_ver2 = mrr_detail_result.sort_values(by=['corporate_id', 'pay_datetime_id'])
# 이전 거래 금액을 저장할 새로운 열 prev_amount 추가
transactions_ver2['prev_amount'] = transactions_ver2.groupby('corporate_id')['sales'].shift(1)
# 사용자 상태를 저장할 새로운 열 user_status 추가
transactions_ver2['mrr_status'] = 'new'
# 이전 거래 금액과 동일한 금액을 가진 사용자에게 'existing' 할당
transactions_ver2.loc[transactions_ver2['sales'] == transactions_ver2['prev_amount'], 'mrr_status'] = 'existing'
# 이전 거래 금액보다 높은 금액을 가진 사용자에게 'upgrade' 할당
transactions_ver2.loc[transactions_ver2['sales'] > transactions_ver2['prev_amount'], 'mrr_status'] = 'upgrade'
# 이전 거래 금액보다 낮은 금액을 가진 사용자에게 'downgrade' 할당
transactions_ver2.loc[transactions_ver2['sales'] < transactions_ver2['prev_amount'], 'mrr_status'] = 'downgrade'
# 이전에 'churned' 상태였고 이제 새로운 거래가 있는 사용자에게 'reactivation' 할당
# 모든 고유한 corporate_id 값을 포함하는 리스트 생성
corporate_ids = transactions_ver2['corporate_id'].unique()
# 각 corporate_id에 대해 루프를 돌며 각 거래의 상태를 업데이트
for corporate_id in corporate_ids:
user_data = transactions_ver2[transactions_ver2['corporate_id'] == corporate_id]
for i in range(1, len(user_data)):
prev_month = user_data.iloc[i-1]['month_year']
curr_month = user_data.iloc[i]['month_year']
if (curr_month - prev_month).n > 1:
transactions_ver2.loc[(transactions_ver2['corporate_id'] == corporate_id) & (transactions_ver2['month_year'] == curr_month), 'mrr_status'] = 'reactivation'
# user_status가 churn_user인 사용자의 마지막 결제일에 'churn' 상태 할당
transactions_ver2.loc[(transactions_ver2['user_status'] == 'churned_user') & (transactions_ver2['pay_datetime_id'] == transactions_ver2['max_date']), 'mrr_status'] = 'churned'
transactions_ver2.head()
이제 MRR 대시보드 예시(2)에 활용된 데이터가 전처리되었고 구글 스프레드시트로 데이터를 적재해주면 됩니다.
이걸 매일 하기는 귀찮으니 Airflow DAG를 활용해서 자동화해주면 됩니다.
여기까지 MRR계산을 위해 SQL, 구글 스프레드시트, python을 활용한 과정을 소개해봤습니다.
누군가 B2B SaaS에서 MRR 계산을 위해 고군분투하고 계시다면 이 코드가 도움이 되시면 좋겠네요
추가로 초기에 대시보드 기획에 많은 참고가 되었던 Baremetrics라는 MRR 대시보드 외산 툴이 있는데 상당히 잘만들었다고 생각되는 서비스입니다.
SaaS 비즈니스를 운영하신다면 참고해보시면 좋을 서비스네요!

분석 데이터의 하위 집합입니다.
사용자, 세션, 이벤트 데이터를 분리해서 세그먼트를 정의하면 분석하고자 하는 대상을 쉽게 정의할 수 있게 만드는 기능입니다.
세그먼트를 정의하게 되면 특정 유저의 그룹 vs 나머지 유저의 특징을 비교 분석해 볼 수 있습니다.
GA4에서 세그먼트 기능을 통해 웬만한 유저들의 특징을 잡아낼 수 있습니다.
그런데 GA4가 어떻게 유저들의 행동 데이터를 수집하고 활용하는지 제대로 알지 못하면 활용하기 힘들겠죠?
이번 글에서는 큰 틀에서 GA4가 어떤 원리로 조건이 설정되는지 알아보려고 합니다.
세그먼트 생성화면을 들여다보면 꽤 많은 조건들을 설정할 수 있는 기능들이 많습니다.
일단 크게 3가지 유형의 세그먼트가 있습니다. (아래 유형에 대한 이해를 잘하셔야 합니다.)
세그먼트 유형 선택은 세그먼트를 조건에 해당하는 결과와 관련이 있는 거라고 생각하시면 이해하시기 쉬울 겁니다.
특히! 각 유형별로 소스 / 매체 선택할 때 주의할 점을 꼭! 숙지하시길 바랍니다!




이렇게 정의는 그럭저럭 이해는 할 수 있지만 역시 예시를 통해 어떻게 데이터가 선택되는지 알아보겠습니다.
특정 유저가 2개의 세션 안에서 몇 가지 이벤트를 발생시켰다고 가정해 보겠습니다.

1. 사용자 세그먼트 예시
사용자 세그먼트 기준으로 구매한 유저를 세그먼트를 만들면 어떻게 데이터가 선택될까요?
총 7개의 이벤트가 모두 선택됩니다. 사용자 기준이니까 조회한 날짜에 있는 이벤트가 모두 포함되기 때문입니다.

2. 세션 세그먼트 예시
최소 한 개의 구매 이벤트가 발생한 모든 세션의 데이터기 때문에 이 기준으로 충족되는 데이터는 purchase(구매) 이벤트가 발생한 session - 2 만 선택됩니다( session - 1 에는 구매 이벤트가 없음)

3. 이벤트 세그먼트 예시
이벤트 기준이면 기준에 맞는 이벤트만 선택한다는 말이기 때문에 session - 2에서 발생한 purchase 이벤트만!! 선택됩니다. 다른 이벤트는 선택 안됩니다!

여기서는 어떤 조건의 유저를 선택할지 셋팅하는 옵션을 선택할 수 있습니다.

여기서 AND, OR 조건을 선택할 수 있는데 회원가입과 구매 이벤트를 발생시킨 유저 선택해 보겠습니다.

그런데 하단에 보면 포함할 조건 그룹 추가라는 버튼이 있습니다.

동일한 방식으로 회원가입과 구매를 한 조건을 설정하면 이렇게 할 수 있죠

즉 하나의 조건 그룹에 회원가입 이벤트와 구매 이벤트를 선택한 것이고 나머지 하나는 두 개의 조건 그룹에 회원가입 이벤트와 구매 이벤트가 각각 설정을 했습니다.
첫 번째 방식과 차이점은 뭘까요? 동일한 결과가 나올까요? 결과는 동일합니다.
???
이게 무슨 말이냐면 그룹 간 영역에서 오른쪽 상단에 보면 사람모양의 드롭다운 버튼이 있습니다.

이걸 클릭하면 조건 범위를 지정할 수 있습니다.
세그먼트 설정할 때랑 동일한 방식이죠? 사용자, 세션, 이벤트 단위로 조건설정이 가능합니다.

세션 및 이벤트 세그먼트에는 조건 지정 범위에 대한 옵션이 더 적습니다. 아래 표는 사용할 수 있는 세그먼트 유형별 조건 범위 간 조합입니다.

다시 예시를 들어볼게요
GA4에서 첫 구매 유저를 따로 이벤트를 개발하지 않으면 특정하기 힘든데 회원가입 후 첫 구매 유저를 세그먼트로 한 번 만들어 보겠습니다.
해당 유저들을 특정하기 위한 필요한 이벤트는 first_visit(첫 방문)과 purchase 이벤트겠죠?
첫 구매 유저를 특정한다고 해도 이를 어떻게 정의하느냐에 따라 결과는 달라집니다! (주의!!)
유저의 행동은 정말 엄청나게 많은 경우의 수로 발생을 하죠.
A유저 : 구매 의사 결정이 빠른 A유저는 동일한 세션 시간 내에서 구매
B유저 : 구매 의사 결정이 느린 B유저는 어제 상품을 처음 둘러보고 내일 구매
이 예시처럼 첫 구매를 동일한 세션 시간내 첫 구매를 한 유저를 특정할 것인지, 세션에 상관없이 첫 구매 유저를 식별한 것인지 정의하기 나름입니다.
첫 구매 유저 세그먼트를 만든다면 어떤 조건을 설정해야 될까요?
사용자 세그먼트를 기준으로 세그먼트를 설정하면 유저의 조건에 해당하지 않는 방문데이터도 포함되게 됩니다.
그러니까 첫 방문 이후 첫 세션에 구매를 하지 않아도 구매를 특정시킨 뒤에 제외 조건을 구매 조건을 2번 이상으로 설정하여 첫 구매한 유저를 식별할 수 있습니다.

그런데 first_visit, 첫 구매 사용자의 방문 데이터만 확인하고자 한다면 사용자 세그먼트가 아닌 세션 세그먼트를 기준으로 동일 세션 내의 조건 범위를 선택하여 세그먼트를 생성해야 합니다.

첫 구매 유저를 모든 세션 범위 조건으로 하여 세그먼트를 생성하고 재구매자(purchase 이벤트가 2번 이상)와 겹치는 부분이 없는지 세그먼트 중복 기능을 활용해 벤다이어그램으로 확인해 보겠습니다.

중복 없이 잘 나뉘었습니다. 이런 식으로 내가 가진 유저의 특징을 세그먼트로 만들어서 비교해 보는 과정이 굉장히 중요한 것 같습니다.
이 개념을 토대로 한 번 만들어 보시면 좋을 것 같습니다.
GA의 세그먼트는 생각보다 할 수 있는 게 많긴 합니다.
하지만 제대로 활용하기 위해서는 위에 설명한 개념들이 잘 정리가 되어 있어야 됩니다.
이번 글을 쓰면서 느낀 건 솔직히 GA4는 사실 Amplitude를 사용해 봤다면 이런게 다 있나 싶을 정도로 불편하고... 뭔가 찜찜한 느낌을 지울 수 없었습니다.
이번 글에서 첫 구매 유저 세그먼트를 예시로 들었는데 GA4에서 First time purchases라는 측정항목이 존재하긴 하지만
이를 세그먼트로 활용은 못합니다... 약간 독립적인 측정항목 같은 느낌입니다.
Amplitude에서는 사실 아주 간단하게 첫 구매 유저를 특정할 수 있는 Historical Count 기능이 있어서.. 아쉬웠습니다.
(물론 제약 조건은 있습니다. 날짜 범위가 시작되기 전 최대 1년까지 기간만 포함됩니다. 그래도 이건 혁명적인 기능!)

본질적으로 GA의 목적은 유저 획득에 초점을 맞춰져 있다면 Amplitude는 Product Analytics 툴로 사용자 행동 분석에 초점이 맞춰져 있긴 합니다. 그래서 목적에 맞지 않아서 해당 기능 개발을 하지 않은 건가 싶기도 합니다.
당장 앰플리튜드를 도입하지 않을 거라면 속 편하게 GA4에서 First Purchase 이벤트 개발을 요청하거나 혹은 일단 소개드린 방식대로 우선 트렌드만 확인하는 용도로 세그먼트를 생성해서 데이터를 분석하시는 걸 권장드립니다.

전 보통 평일 아침에 운동을 하는데, 끝나고 나면 다른 멤버분들과 이야기를 나누게 됩니다. 아무래도 출근 시간이다보니 스몰톡이 직업 쪽으로 흘러갔습니다. [마케팅]을 하고 계신다고 하시더라고요.
반가운 마음에 전 그로스마케팅을 한다 말해더니 모르는 눈치십니다. [퍼포먼스마케팅]을 하시는 거냐 물었더니 그렇다고 합니다. 어떤 매체를 주로 운영하시냐 했더니 말끝을 흐리십니다.
얘기해보니 그 분의 업무는 <인스타그램 계정 육성> 이었습니다. 특정 부문의 콘텐츠만 게재하는 다수의 계정을 생성해서 ~N만의 팔로워를 가진 계정으로 키우고 광고를 받으며 수익화를 하는죠. 즉 [SNS마케팅]이자 [콘텐츠마케팅]이자 [인플루언서 마케팅]입니다. 저 또한 헷갈렸습니다. 이 또한 퍼포먼스 마케팅일까...?
퍼포먼스는 마케팅은 퍼포먼스(Performance)의 실적, 성과라는 뜻에서 파생됩니다. 즉 퍼포먼스 마케팅이란 성과를 확인할 수 있는 마케팅입니다. 성과란 일의 결과를 뜻하고요.
시험을 보고 성적표를 받듯, 마케팅을 하고 이 일에 대한 성적표를 만들 수 있는 것이 퍼포먼스 마케팅입니다. 어떤 요소에서 얼마나 잘했는지에 대해서 수치 기반의 정량적인 기준으로 평가할 수 있는 거죠.

전통적인 마케팅은 주로 ATL (Above The Line)에 속하는 전통적인 매체를 통한 것을 말합니다. TV, 라디오, 옥외 광고, 신문 등이 있겠죠.
이러한 매체들은 몇 명에게 노출되었는지까지는 대략 추산할 수 있지만 실제로 그 중에 몇 명이 어느 정도로 관심을 보였는지를 알 수 없습니다.

즉 TV가 틀어져있는 가구수는 셀 수 있겠지만, 그 가구 내에서 몇 명의 인원이 영상을 보고 있었는지, 다른 일을 하면서 보고 있었는지 아니면 TV 영상에만 집중하고 있었는지, 그래서 TV 광고에 나온 상품을 인지하게 되었는지 상호 작용이 불가능하므로 알기 어렵습니다.
라디오나 옥외광고도 마찬가지로, 라디오가 청취수는 알겠으나 청취수는 청취자수와 일치하지 않고 옥외광고의 경우 그 앞을 지나간 사람들을 추산할 수 있을 뿐입니다. 그러므로 전통적인 마케팅에서의 ATL 매체는 성과를 정확하게 측정하기가 어렵습니다.
그래서 비즈니스에서는 ROI를 묻습니다. 투자금 대비 이익률이죠. (이익-마케팅 비용)/(마케팅 비용)의 수식으로 비용 대비 매출이 아닌 [이익]의 수준을 봅니다.
마케팅에서는 주로 ROAS를 봅니다. (마케팅에 의한 매출)/(마케팅 비용)의 수식입니다. 여기서 주목할 점은 <마케팅에 의한 매출>입니다.
마케팅에 의한 매출 = 마케팅에 의한 성과, 이를 알고 싶었기 때문에 성과(매출)을 측정할 수 있는 퍼포먼스 마케팅이 중요해졌다고 볼 수 있습니다.

특정 브랜드에서 마케팅을 운영한다고 할 때, 사용자는 신규와 기존으로 나눌 수 있습니다. 신규는 우리를 모르는 사람들, 기존은 우리를 아는 사람들로 정의할 수 있겠으나 [안다/모른다]의 상태를 명확하게 구별해줄 수 있는 변인이 필요합니다.
대개 이 상태를 [가입] 행동으로 구분합니다. 즉 이미 우리 브랜드의 회원인 사용자는 기존, 비회원인 사용자는 신규가 되는 것이죠. 이와 같이 신규 사용자를 대상으로 하는 마케팅을 사용자 획득: UA (User Acquisition) 이라고 합니다.


인지도 증대 및 관심 유도에 유효한 [배너 광고]
배너 광고 매체들은 마케터가 아니어도 익숙한 이름들입니다. 말 그대로 '배너'가 노출되어야 하기 때문에 많은 수의 사용자를 확보하고 있는 플랫폼이어야 경쟁력이 있기 때문이죠.
의사결정 및 구매 전환에 유효한 [검색 광고]


A/B 테스트는 원칙적으로 대조군(Control Group)과 실험군(Experimental Group)을 나누어 다른 모든 환경이 동일하다고 할 때, 한 가지의 변인을 다르게 하여 그 변인의 영향도를 실험하는 것입니다.
광고 집행 시, 모든 외부 요인을 통제할 수 없기 때문에 그 부분을 감안하고 광고 셋팅(타겟팅 등)이나 소재를 A/B 테스트 해볼 수 있습니다. 특정 상품의 경우 소재에서 어떤 내용을 강조할지가 주요 테스트 내용이 됩니다. 1. 개발스토리 2. 리뷰 3. USP 4. 가격 등 강조할 수 있을만한 것들을 제일 메인 요소로 활용해보는 것입니다. A/B 테스트는 매우 큰 개념으로 마케팅에서도 매체, 세팅/타겟팅, 소재 기획/제작 등에서 다양하게 적용될 수 있습니다.

1. 인지도 증대 (Awareness)
'트래픽' 캠페인으로도 불립니다. 불특정 다수(오픈타겟, 논타겟)에게 최대한 많은 도달/노출을 이루어 제품의 인지도 향상과 클릭에 의한 유입, 트래픽을 의도합니다.
2. 관심 유도 (Interest)
타겟 세팅 시 관심사를 설정하여, 다른 행동으로 특정 관심사를 가진 것으로 추론되는 사용자들에게 소재를 노출할 수 있습니다. 혹은 관련도가 높은 웹사이트로 노출 위치를 설정할 수 있습니다.
3. 의사 결정 및 구매 전환 (Decision & Action)
구매 의도 있는 상태에서 특정 키워드를 검색했을 시 광고가 노출되거나, 이전에 방문했던 사용자를 대상으로 재방문 등을 유도할 수 있습니다.


배너 광고든 검색 광고든 각 매체를 통해서 광고가 운영이 되면 관심을 가진 사람들이 클릭하여 설정해둔 페이지로 유입됩니다.
이 때, 페이지에 유입된 사용자가 100명이라고 할 때 (이 100명을 정확하게 구분하는 것도 꽤 어려운 일입니다...) 100명이 [배너 광고]를 보고 왔을지 [검색 광고]를 보고 왔을지 [배너 광고]도 보고 [검색 광고]도 보고 왔을지, [배너 광고]만 보고 10일 후에 페이지 주소를 입력해서 들어왔을지...
어떤 채널, 어떤 매체로 들어왔을지 유입 경로를 알고 싶다면 매체에 광고를 세팅할 때 URL에 UTM이라는 변수를 붙여준 후 이를 Google Analytics로 측정해야 합니다.


유상 광고의 경우 모든 광고 매체에서 관리자(Admin) 페이지를 지원하며 성과를 측정하여 보여주는데 굳이 구글 애널리틱스를 봐야하는 이유가 뭘까요?
자사몰에서의 단 한 건의 성과가 메타에서도 성과로 집계하고, 네이버에서도 성과로 집계하고, 구글에서도 성과로 집계될 수 있습니다. 자사몰 데이터 기준 전환 1건이, 광고 관리자 기준 전환 3건이 될 수 있는 것이죠. 그렇기에 매체 별 광고관리자만을 사용해서 성과를 측정하지 않고 웹으로 랜딩되는 경우 구글 애널리틱스(Google Analytics)를 주로 사용하는 것입니다.

광고 매체가 전환에 기여한 기준은 기간과 방식에 따라 달라질 수 있습니다. 기여 기간을 1일로 설정한다면 3일 전 클릭한 성과는 인정되지 않을 수 있습니다. 기여 모델은 라스트 터치, 퍼스트 터치, 멀티 터치 등으로 구분되고 약 일주일 간 광고를 운영했을 때 (메타, 네이버, 구글 등)
- 사용자가 구매하기 전 마지막으로 누른 광고 매체가 가장 크게 기여했다고 한다면 > 라스트 터치 (Last touch) 모델,
- 사용자가 구매하기 전 처음으로 누른 광고 매체가 가장 크게 기여했다고 한다면 > 퍼스트 터치 (First touch) 모델입니다.
그에 따라 MMP(Mobile Measurement Partner)로 통칭되는 Appsflyer, Airbridge, Adjust와 같은 SDK를 붙이는 등의 추가 tracker가 필요합니다.

보통은 이 부분에서 가장 많은 어려움을 겪습니다. GA와 MMP, 여기서 CRM 솔루션(Braze, Insider 등) 이나 PA(Product Analytics: Amplitude, Mixpanel 등) 솔루션까지 쓴다면 솔루션 내의 데이터 정합성을 맞추는 것 등의 관리가 복잡해지기 때문입니다.
마케팅 웹(Web) 캠페인의 성과는 웹페이지로 랜딩되기에 GA만으로도 측정이 수월합니다. 문제는 앱설치를 목표로 앱스토어로 랜딩시키면서 시작됩니다. 그래서 보통 앱 성과 데이터를 측정하기 위핸 MMP (앱스플라이어/Appsflyer, 에어브릿지/Airbridge, 애드저스트/Adjust 등)을 도입하는데요.

위의 데이터파이프라인 예시처럼, 구글 애널리틱스의 웹 데이터 앱스플라이어의 앱 데이터, 기타 광고 매체들의 광고 데이터를 모아 구글 빅쿼리에 적재하고 이를 태블로를 통해서 대시보드로 제작합니다.

다양한 시각적 형태로, 다양한 성과를, 다양한 차원으로 볼 수 있습니다. 커머스의 배너 성과를 볼 수도 있고, 상품/카테고리/브랜드의 매출 성과를 볼 수 도 있고, 광고 성과를 볼 수도 있습니다. 유입된 광고 매체에 따라 유저들의 LTV로 대변되는 충성도가 다른지도 확인할 수 있고요.
처음의 의문으로 돌아가자면, 인스타그램 계정 키우기도 어떤 측면에서는 퍼포먼스 마케팅으로 볼 수 있겠습니다. '측정'이 가능하기 때문입니다. 콘텐츠를 올리면서 올라가는 팔로워수, 피드의 좋아요수 및 댓글수 그리고 릴스의 조회수 등으로 계정의 성장을 숫자로 '측정'할 수 있습니다.
최근 읽은 '순서 파괴'라는 책에서 인상 깊게 읽은 부분이 있습니다. 아마존의 주요 구성원들이 아마존의 일하기 방식에 대해서 쓴 책입니다.
아마존에서는 목표를 설정할 때 아래 다섯 개 요소를 반영한다고 합니다.
이 중 저에게 가장 와닿았던 것은 측정에 관한 것이었습니다.
.png)

데이터를 다루면서 고객의 업무 효율을 높이는 것을 도와드리고 있지만, 정작 저의 일에서는 데이터 정리와 효율화는 잘 못하고 있더라고요. 그래서 요즘은 Make와 Zapier를 통해 최대한 많은 일들을 자동화 하면서 좀 더 저의 자유(?) 시간을 만들어가고 있습니다.
👉 Make 자동화 : https://www.make.com/en
그런데 어느순간 Make 자동화가 많아지면서 제가 만들고 운영중인 자동화가 뭔지 헷갈리기 시작했습니다. Make 자동화로 업무효율화를 만들었지만 그럴수록 자동화 솔루션이 정리가 되지 않는 아이러니...
Make에서는 하나의 자동화 과정을 시나리오라고 해서 각 시나리오를 Json 형식으로 저장해서 관리할 수 있습니다. 이러한 Make의 특징을 활용해서 Make에서 시나리오가 새롭게 만들어지거나 업데이트가 되면 각각 구글 드라이브와 노션에 저장 & 업데이트 되는 자동화를 만들어봤습니다.
- 자동화 솔루션 : Make
- DB : Notion, Make DB
- 자료 정리 : 구글 드라이브



1️. Make 어드민의 다양한 시나리오들입니다. 카테고리를 만들 수 있긴하지만 그것만으로는 한번에 어떤게 있는지 확인이 쉽지 않습니다.
2️. Make 자동화 설계 화면 입니다.
3️. Notion에 저장된 최종적인 모습입니다.
👉 업무를 하다보면 고객 리드, 업무 파일, 데일리 보고 등 DB화 & 자료를 정리해야하는 업무들이 빈번하게 있습니다. 해당 시나리오처럼 매번 생산되는 자료를 구글 드라이브와 노션에 자동으로 기록한다면 생각보다 많은 업무를 효율화 할 수 있습니다.

Google Analytics를 사용해 보셨다면 ‘세션’이라는 용어에 익숙하실 것입니다. Universal Analytics(GA3)에서는 세션 단위로 데이터를 수집하여 지표를 측정했지만, GA4에서는 데이터 수집 방식이 달라져 주의가 필요합니다. GA4의 세션 관련 지표는 혼란을 일으킬 수 있습니다.
이번 글에서는 세션의 개념을 자세히 살펴보고, GA4에서의 세션이 어떻게 다른지 알아보겠습니다.
세션 관련해서 구글 가이드 문서에 따르면
- 세션은 사용자가 웹사이트 또는 앱과 상호작용하는 기간입니다.
- 세션은 사용자가 앱을 포그라운드에서 열거나 페이지나 화면을 보고 현재 활성화된 세션이 없는 경우 시작됩니다.
- 세션 수 : 고유 세션 ID 수를 추정하여 사이트나 앱에서 발생하는 세션 수를 계산합니다.
예를 들어 유저가 브라우저 탭에서 페이지를 열고 이메일을 확인하거나 다른 일을 하다가 2시간 뒤에 다시 돌아와서 브라우징을 할 수 있겠죠? GA4에서는 이를 페이지 뷰가 있는 세션으로 보고 2시간 뒤에 사용자 참여로 간주하고 새로운 세션으로 기록합니다.
1. 첫 번째 세션:
2. 두 번째 세션:
이때 새로운 세션이 시작되지만 페이지 조회 이벤트는 기록되지 않습니다.→ 두 번째 세션이 사용자 참여로만 기록됩니다
빅쿼리로 실제 어떤 케이스인지 특정 유저의 로그를 한 번 확인 해보겠습니다.

이렇게 페이지뷰 이벤트가 없는 두 번째 세션이 생기며, 이는 참여율(Engagement Rate) 지표로 나타납니다.
참여율 = 참여 세션 수 / 총 세션 수

이런 유저가 많아지면 세션 기반의 지표(예: 세션당 페이지뷰, 세션당 평균 참여시간)가 낮아집니다.
세션당 페이지뷰 수 계산 예시:
페이지뷰 수 / 세션 수 = 10 / 1 = 10
위와 같은 유저의 행동이 늘어나면:
페이지뷰 수 / 세션 수 = 10 / 2 = 5
페이지뷰 이벤트가 포함되지 않은 세션이 발생하니 지표가 감소하게 됩니다.(분모가 커지므로)
따라서 GA3에서 사용하던 세션 기반의 지표는 주의해서 사용해야 하며, 이벤트나 참여 관련 지표(참여 세션)를 보는 것이 좋습니다.
(GA4와 GA3의 데이터 수집 방식도 다릅니다)
자.. 그리고 또 있습니다.
세션 데이터의 현실.. 빅쿼리를 열어보면 .. 더 조심해야겠구나 라는 생각이 들겁니다.
일단 절대 세션수 ≠ session_start 이벤트의 수 가 아닙니다.
왜그런지 직접 조회해보죠!
아래 특정 유저의 세션을 특정해서 조회해봤습니다.
event_name 컬럼에 session_start 이벤트는 없고 다른 이벤트만 있죠?

이런 상황은 빈번하지 않지만 발생할 수 있습니다. 하나의 세션에 두 개의 세션 이벤트가 발생했고, 심지어 사용자 아이디도 다릅니다.
GA4 인터페이스에서는 당연히 단일 세션으로 계산하지 않을 것 같지만 빅쿼리에서는 이런 케이스 때문에 user_pseudo_id와 ga_session_id를 조합해서 각 세션에 대한 고유 식별자를 만들어서 session 을 카운팅 해야됩니다.
concat(user_pseudo_id, (select value.int_value from unnest(event_params) where key = 'ga_session_id')) as session_id,

GA3에서는 세션 윈도우(30분)가 지나면 완전히 새로운 세션이 시작되지만, GA4에서는 기존 세션이 계속 되기 때문에 이렇게 소스가 1개 이상 발생할 수 있습니다.

구글 애널리틱스에서도 세션수를 집계할 때 추정값을 사용합니다.
실제로 빅쿼리에 count(distinct ga_sesssion_id) 를 집계하면 성능에 영향을 줍니다..
그런데 전 세계에서 이걸 조회하는데 이걸 진짜 집계를 ?? 불가능하죠
그래서 HyperLogLog ++ (가이드 링크)라는 알고리즘을 적용해서 추산한 값을 보여줍니다.

실제로 성능을 눈으로 확인해보죠
ga_session_id를 고유하게 카운팅 해보는 쿼리로 비교를 해보겠습니다.
COUNT(DISTINCT ga_session_id)

HLL_COUNT.EXTRACT(HLL_COUNT.INIT(ga_session_id, 14))

차이가 보이시나요? (참고로 데이터 하루치만 조회했고 쿼리 결과는 같습니다)
모든면에서 더 효율적인 처리를 하고 있음을 알 수 있습니다.
사실 GA4에서는 세션이라는 개념은 더 이상 의미가 없고 지금까지 위의 예시를 통해 확인할 수 있었습니다.
그럼에도 세션 지표를 무조건 써야된다면 참여 세션지표를 사용하는게 좋습니다.
이제 이걸 통해서 다음 글에서는 GA4의 꽃 세그먼트 분석에 대해서 알아보겠습니다.
(세그먼트 기능을 쓰려면 세션에 대한 이해가 꼭 필요하기 때문에 이번 글부터 시작하게 되었습니다.)

디지털 전환이란 무엇일까요? DT 또는 DX로도 불리는 디지털 전환은 Digital Transformation에서 유래했습니다. 여기서 Transformation, 전환은 상태의 변화를 말합니다. 즉 디지털이 아니던 것이 디지털 상태로 변화하는 것입니다.

디지털 전환, 어쩐지 거창합니다. 마티니의 그로스팀에서 큰 규모의 회사를 방문했을 때 주로 DX실, DT실이 명함에 기재된 경우가 많더라고요. 즉 큰 곳에서 시도하는 경우가 많다는 것이겠죠.

온라인 비즈니스는 진행 중입니다. 오프라인을 온라인으로 전환시키는 DX와 DT는 상당수 진척되었습니다. 평범한 일상만 생각해 봐도 그렇습니다.
즉 현재의 디지털 트랜스포메이션, 디지털 전환(DT, DX)의 주요 과제는 오프라인의 온라인 전환은 아닌 듯합니다.

우리 프로덕트의 사용자가 10명, 100명, 1,000명일 때는 수기가 가능할 수 있습니다. 10명에게는 매일 전화를 할 수도 있을 것이고, 100명에게는 문자를 보낼 수 있을 것이고, 1,000명까지는 어떻게 수기로 그룹화를 해서 카카오톡을 보낼 수도 있겠죠.
하지만 [10,000명] 에게는요? [100,000명] 에게는요? 예를 들어보겠습니다.

[CRM마케팅/수동]
#1 보유한 데이터베이스(DB)에 접근하여
#2 조건에 맞는 쿼리문을 작성하여#3 '고정된 시점'의 사용자 데이터를 추출함
#4 성과 분석 시, 동일 프로세스를 거쳐 특정 시점의 사용자 데이터를 재추출함
#5 엑셀 등을 활용하여 수기로 데이터 값을 비교함
[CRM마케팅/자동] *솔루션 활용
#1 보유한 데이터베이스(DB)를 CRM 솔루션의 클라우드에 연동하고
#2 CRM 솔루션의 어드민에서 변수를 조절하여 (클릭!)
#3 '실시간'으로 사용자 데이터를 추출함
#4 성과 분석 시 어드민에서 변수를 조절하여 (클릭!)
#4 솔루션에서 제공하는 대시보드/그래프 형태로 데이터 값을 비교함

[퍼포먼스마케팅/수동]
#1 광고 매체 별 광고관리자에서 성과를 엑셀로 다운로드 후
#2 보고용으로 맞춰둔 엑셀 형식에 맞춰 복붙 합니다. (ctrl+C, ctrl+V)
*매체 A, 매체 B, 매체 C, 매체 D.... 매체를 많이 쓸수록 이 절차는 많아집니다.
**혹시 글로벌이라면? 국가별로도 쪼개줘야 합니다.
***신규 사용자와 기존 사용자의 리타겟팅을 나눈다고요? 이것도 쪼개서...
#3 매체 성과와 자사 내부 DB 성과의 숫자가 맞지 않습니다.
기여 모델 및 기여 기간의 설정이 다르거나...
[퍼포먼스마케팅/자동]
#1 광고 매체 별 데이터를 연동합니다.
#2 광고 매체와 MMP, CRM 솔루션의 데이터를 통합합니다. (DW)


마케팅 업무 자동화, 마케팅 오토메이션(Automation)의 효율에 대해서 이야기를 종종 하게 되는데요. 업무 효율성을 높이는 것이 수익 상승에 기여하지는 않는단 의견을 종종 듣습니다.
문제 정의와 해결 방안 제시 및 대응. 문제 해결자(problem-solver)라는 직무도 존재하는 것처럼 사실 모든 직업은 분야와 내용과 형식이 다를 뿐, 어떠한 문제를 해결하는 것 아닐까요?
위의 사례로 들었던 CRM 메시지 수신자 추출도, 퍼포먼스마케팅 성과 분석도 고객(사용자)이 아닌 실무자에게 필요한 디지털 전환, 즉 마케팅 자동화의 일환인데요.



여러 기업들의 디지털 전환을 도우면서 가장 기본적이지만 가장 중요했던 것은 바로 '측정'입니다. 웹과 앱에서의 성과 측정을 위해 필수적인 것, 바로 UTM입니다.
웹페이지의 주소인 URL에 UTM 파라미터를 넣어 유입된 사용자들이 어떤 경로로 들어왔는지 파악할 수 있습니다.

보통 퍼포먼스 광고를 운영할 때 페이스북 광고관리자의 구성에 맞추어 캠페인/그룹/소재 단으로 구성하는 경우도 있습니다.

유상 광고(paid media)를 운영하는 퍼포먼스마케팅 외에, 인플루언서 마케팅(earned media)이나 유튜브/인스타그램/블로그 등에 자체 콘텐츠(owned media)를 게재할 때도 UTM을 삽입한 URL을 활용하면 좋습니다!

개인화 추천 시스템: 고객의 과거 구매 내역 및 검색 기록을 바탕으로 맞춤형 제품 추천
챗봇 및 가상 어시스턴트: 고객 문의 및 지원을 자동화하여 실시간으로 대응


고객 세그멘테이션: 고객 데이터를 분석하여 세분화된 마케팅 전략 수립
실시간 데이터 분석: 판매, 트래픽, 재고 등의 데이터를 실시간으로 분석하여 빠른 의사 결정 지원

스케일러블 인프라: 트래픽 변동에 유연하게 대응할 수 있는 클라우드 기반 인프라.
클라우드 기반 CRM: 고객 관계 관리 시스템을 클라우드에서 운영하여 언제 어디서나 접근 가능.

모바일 최적화 웹사이트 및 앱: 모바일 사용자를 위한 최적화된 사용자 경험 제공.
모바일 결제 시스템: 다양한 모바일 결제 옵션 지원.
온라인 및 오프라인 데이터 통합: 고객의 온/오프라인 행동 데이터를 통합하여 일관된 경험 제공.
클라우드 컴퓨팅, 증강 현실 (AR), 사물 인터넷 (IoT), 결제 기술, 로봇 프로세스 자동화 (RPA) 등이 디지털 전환에 필요한 주요 기술로 여겨집니다.
디지털 전환을 검색하면 정말 방대한 의미의 내용들이 나옵니다. 클라우드 컴퓨팅, 인공지능(AI)과 머신러닝(ML), 빅데이터 분석, 사물인터넷(IoT), 블록체인, 사이버 보안 등이 대표되는 단어죠.
생각해 보면 그로스 컨설팅이라고 꼭 디지털 전환이 완료된 상황에서만 될 수 있는 것은 아닙니다. 어느 영역의 디지털 전환이 그로스 컨설팅의 실행 방안이 될 수도 있는 것이죠.
Chat GPT가 생활화되고 AI에 대한 기사가 쏟아지는 요즘이지만, UTM을 잘 쓰는 것도 생각보다 어렵습니다. 디지털 전환을 위해 AI 도입보다 먼저인 것들이 있지 않을까요?

이 글을 읽고 계시다면 코호트 분석을 이미 하고 계실 건데 측정 기준에 대해서 의문이 생기신 분이 보실 것 같네요
구글에 '코호트 분석 SQL' 라고 검색하면 정말 많은 글들이 많습니다.
글에서 소개하는 쿼리 예시는 대부분 datediff함수를 활용해서 Date Granularity를 계산합니다.
이해하기 쉽게 예를 들어보겠습니다.
유저 1 : 23:30 에 회원가입 후 다음날 다시 들어왔습니다.
유저 2 : 13:30에 회원가입 후 다음날 다시 들어왔습니다.
day 단위로 계산을 하면 유저 1 은 우리 서비스를 30분 경험하고 다음날 재방문했다고 계산됩니다.
유저 2는 약 10시간 30분 서비스를 경험하고 재방문을 했다고 계산됩니다.
동일한 조건일까요? 그렇지 않죠?
만일 시간 단위로 계산을 하게 되면 특정 행동을 수행한 시간부터 다음 행동까지의 Time window를 24시간 뒤로 하면 이 유저는 다음날이 아닌 모레 재방문했다고 계산되겠죠?
DATEDIFF( [first_event_dt], [second_event], DAY )
DATEDIFF( [first_event_dt], [second_event], HOUR ) / 24 )
월단위로 계산할 때도 마찬가지입니다.
월별 일자수가 모두 다릅니다. 1월(31일), 2월(28일), 4월(30일)...
월 단위로 측정할 때도 30일로 모두 통일해줍니다.
DATEDIFF( [first_event_dt], [second_event], HOUR ) / 24 * 30)
이렇게 계산되면 유저별로 경과 시간은 모두 통일 되었습니다!!
실제로 Amplitude(앰플리튜드)의 코호트 분석 기능에는 이런 기능들이 존재합니다. 만약 안 쓰고 계시다면 직접 쿼리를 날려서...
여기 가이드를 보시면 앰플리튜드가 24시간 단위로 경과 시간을 측청 하는 방식을 설명해 두었습니다.


24시간 윈도우 기준, 캘린더 기준으로 경과 시간(t)을 측정하는 옵션이 있죠?
얼마나 차이를 보였는지 가상의 데이터로 확인을 해보았습니다.
(참고로 더미 데이터는 kaggle 이나 Mockaroo 에서 생성하실 수 있습니다)
참고로 해당 데이터 계산 기준은 월별 첫 구매 기준 재구매율입니다.

t = 1 지점부터 차이를 보이기 시작하는데 t = 0 이 100%라서 차이가 잘 안 보입니다. 로그 스케일을 통해 다시 확인해 보면

확실히 달력 기준의 리텐션율이 조금 더 높아 보이네요
얼마나 차이 나는지 두 기준의 리텐션율을 나눠 보겠습니다 최대 1.27배까지 납니다. (아래 차트에서는 0은 무시합니다. t = 0 은 100%이기 때문에)
t = 1 : 1.15배
t = 22 : 1.27배

데이터에 따라서 차이가 달라지겠지만
코호트의 기준이 만일 회원가입일 기준의 재구매율이거나 회원가입일 기준 재방문율을 측정한다면 더 많은 차이를 보일 수 있을 걸로 예상됩니다.
제가 사용한 쿼리는 아래와 같습니다.
WITH tb_pay_first AS (
SELECT country
,user_id
,min(pay_datetime_id) first_pay_datetime_id
FROM order
GROUP BY 1,2
)
, tb_base_ AS (SELECT st0.*
, FLOOR(TIMESTAMPDIFF(HOUR, st1.first_pay_datetime_id, st0.pay_datetime_id) / 24) AS days_since_first_pay
, FLOOR(TIMESTAMPDIFF(HOUR, st1.first_pay_datetime_id, st0.pay_datetime_id) / (24 * 30)) AS months_since_first_pay_period_24h
, (YEAR(pay_datetime_id) - YEAR(first_pay_datetime_id)) * 12 + (MONTH(pay_datetime_id) - MONTH(first_pay_datetime_id)) AS months_since_first_pay_period_day
, st1.first_pay_datetime_id
FROM order st0
LEFT JOIN tb_pay_first st1
ON st0.user_id = st1.user_id
AND st0.country = st1.country
WHERE 1 = 1
)
, tb_base_24h AS (
SELECT time_id_
, country
, since_time_period_24h
, CASE
WHEN 'acc' = 'normal' THEN SUM(SUM(IF(since_time_period_24h = max_since_time_period_24h, repurchase_user_cnt, 0))) OVER
(PARTITION BY time_id_, country ORDER BY since_time_period_24h DESC RANGE BETWEEN UNBOUNDED PRECEDING AND CURRENT ROW)
ELSE SUM(repurchase_user_cnt)
END AS repurchase_user_cnt
, count(1) pay_user_cnt
, sum(sales) AS sales
FROM (SELECT *
, CASE WHEN since_time_period_24h = 0 AND pay_cnt > 1 THEN 1
WHEN since_time_period_24h = 0 AND pay_cnt <= 1 THEN 0
ELSE 1
END AS repurchase_user_cnt
, MAX(since_time_period_24h) OVER (PARTITION BY country, user_id) as max_since_time_period_24h
FROM
(SELECT tmp0.time_id_
, tmp0.country
, tmp0.since_time_period_24h
, tmp0.user_id
, SUM(tmp0.pay_cnt) AS pay_cnt
, SUM(tmp0.sales) AS sales
FROM
(SELECT DATE_FORMAT(first_pay_datetime_id ,'%Y-%m-01') time_id_
, country
-- , months_since_first_pay_period_day AS since_time_period_day
, months_since_first_pay_period_24h AS since_time_period_24h
, user_id
, COUNT(distinct order_id) AS pay_cnt
, SUM(sales) as sales
FROM tb_base_
-- WHERE DATE_FORMAT(first_pay_datetime_id ,'%Y-%m-01') >= '2023-01-01'
GROUP BY 1,2,3,4) tmp0
GROUP BY tmp0.time_id_
, tmp0.country
, tmp0.since_time_period_24h
, tmp0.user_id
) tmp
) tmp1
GROUP BY time_id_
, country
, since_time_period_24h
)
, tb_base_day AS (
SELECT time_id_
, country
, since_time_period_day
, CASE
WHEN 'acc' = 'normal' THEN SUM(SUM(IF(since_time_period_day = max_since_time_period_day, repurchase_user_cnt, 0))) OVER
(PARTITION BY time_id_, country ORDER BY since_time_period_day DESC RANGE BETWEEN UNBOUNDED PRECEDING AND CURRENT ROW)
ELSE SUM(repurchase_user_cnt)
END AS repurchase_user_cnt
, count(1) pay_user_cnt
, sum(sales) AS sales
FROM (SELECT *
, CASE WHEN since_time_period_day = 0 AND pay_cnt > 1 THEN 1
WHEN since_time_period_day = 0 AND pay_cnt <= 1 THEN 0
ELSE 1
END AS repurchase_user_cnt
, MAX(since_time_period_day) OVER (PARTITION BY country, user_id) as max_since_time_period_day
FROM
(SELECT tmp0.time_id_
, tmp0.country
, tmp0.since_time_period_day
, tmp0.user_id
, SUM(tmp0.pay_cnt) AS pay_cnt
, SUM(tmp0.sales) AS sales
FROM
(SELECT DATE_FORMAT(first_pay_datetime_id ,'%Y-%m-01') time_id_
, country
, months_since_first_pay_period_day AS since_time_period_day
-- , months_since_first_pay_period_24h AS since_time_period_24h
, user_id
, COUNT(distinct order_id) AS pay_cnt
, SUM(sales) as sales
FROM tb_base_
GROUP BY 1,2,3,4) tmp0
GROUP BY tmp0.time_id_
, tmp0.country
, tmp0.since_time_period_day
, tmp0.user_id
) tmp
) tmp1
GROUP BY time_id_
, country
, since_time_period_day
)
, cohort_base_24h AS
(SELECT time_id_
, country
, since_time_period_24h
, repurchase_user_cnt
, pay_user_cnt
, sales
, SUM(sales) OVER w AS acc_sales
, FIRST_VALUE(pay_user_cnt) OVER w AS cohort_user_cnt
, COUNT(1) OVER (PARTITION BY country) AS cohort_cnt
FROM tb_base_24h
WINDOW w AS (PARTITION BY time_id_, country ORDER BY since_time_period_24h RANGE BETWEEN UNBOUNDED PRECEDING AND CURRENT ROW
)
)
, cohort_base_day AS
(SELECT time_id_
, country
, since_time_period_day
, repurchase_user_cnt
, pay_user_cnt
, sales
, SUM(sales) OVER w AS acc_sales
, FIRST_VALUE(pay_user_cnt) OVER w AS cohort_user_cnt
, COUNT(1) OVER (PARTITION BY country) AS cohort_cnt
FROM tb_base_day
WINDOW w AS (PARTITION BY time_id_, country ORDER BY since_time_period_day RANGE BETWEEN UNBOUNDED PRECEDING AND CURRENT ROW
)
)
SELECT *
, (pay_user_cnt * 100) / cohort_user_cnt AS retention_rate
FROM
(SELECT 1 AS time_id
, country
, since_time_period_24h
, SUM(repurchase_user_cnt) AS repurchase_user_cnt
, SUM(pay_user_cnt) AS pay_user_cnt
, FIRST_VALUE(sum(cohort_user_cnt)) OVER(PARTITION BY country RANGE BETWEEN UNBOUNDED PRECEDING and CURRENT ROW) as cohort_user_cnt
FROM cohort_base_24h
GROUP BY 1
, country
, since_time_period_24h) tmp3분석의 기준은 굉장히 중요합니다. 어떤 기준으로 분석하느냐에 따라서 의사결정 방향이 달라질 수 있겠죠?
코호트 분석은 시간을 계산해서 집계하는 분석인만큼 시간의 기준을 제대로 설정하는 게 중요합니다.
저도 실제로 분석해 보면서 분석 기준의 중요성을 다시 한번 깨달을 수 있었습니다.
혹시 지금 day 단위로 코호트 활용해 재구매율을 측정하고 계신다면 24시간 단위로 계산해 보시면 어떨까요?
Reference
https://medium.com/@paul.levchuk/how-to-build-user-cohort-properly-b70a74e5e1c8

Modern Growth Stack, 모던 그로스 스택으로 디지털 마케팅 솔루션 에어브릿지(Airbridge)와 브레이즈(Braze), 앰플리튜드(Amplitdue) 등을 다루는 AB180이 개최하는 디지털 마케팅 세미나입니다.
https://www.moderngrowthstack.com/speaker

이번 MGS 2024는 'FUTURE OF GROWTH'라는 주제로 2024.07.31 (수) 9시부터 18시까지 서울 코엑스 1층 그랜드볼룸 & 2층 아셈볼룸에서 진행됩니다.
디지털 마케팅 분야에서 MGS만큼 큰 규모로 개최되는 세미나는 3개+ 정도 있습니다.
1. MGS: Modern Growth Stack by AB180
2. The Maxonomy by CJ Maxonomy
3. MAX Summit by 모비데이즈(MOBIDAYS)
2022년에는 맥스서밋에서 발표를 했었고("온택트 시대, 푸드 테크 기업의 新 마케팅 전략"), 2023년에는 The Maxonomy에서 마티니의 발표 자료("마케팅하는데 개발이 왜 문제일까?")를 만들었고 2024년은 MGS에 마티니의 일원으로 참가하는데요.
MGS와 같은 대형 세미나를 가면 보통 한 장소에 홀이 여러 개 (main, sub1, sub2...) 있고 세션이 나눠서 진행됩니다. 관심사에 맞는 세션을 들으러 시간마다 자리를 이동하곤 하고요.



세션은 다양합니다.
인하우스(브랜드나 플랫폼)에서 마케팅 전략 및 실행안에 대한 인사이트를 나눌 때도 있고 솔루션사(Amplitude, Braze, Airbridge 등 PA, CRM, MMP Soltuion)에서 솔루션의 이점에 대해서 말하기도 하고요. 광고 플랫폼이나 대행사, 컨설팅사 등 주제와 연사도 다양하고 그에 따라 내용과 난이도도 다채롭습니다.
2024년 연사진만 슬쩍 봐도 구글(Google), 메타(Meta), X(엑스: 구 트위터 twitter), 커니(Kearny) 등의 광고 플랫폼들과 컨설팅사 및 29CM 등의 인하우스 눈에 띄네요.
디지털 마케팅 분야에서 유명한 AB180, CJ Maxonomy, 모비데이즈가 개최하는 세미나들인 만큼 운영하는 세션의 주제만으로도 트렌드를 파악하기 충분합니다. 오늘은 MGS 2024의 세션을 통해 최근의 마케팅 트렌드가 무엇인지 알아보려고 합니다.
우선 AB180측에서 분류해 둔 키워드는 #글로벌, #애드테크·마테크, #트렌드 #프라이버시 #게임 #제품분석 #AI #MMP #UA #크리에이티브 #풀퍼널마케팅 #CRM #수익화 등입니다.

키워드가 좀 많다 보니, 세션들을 확인하고 좀 더 포괄적으로 공통되는 주제로 분류하자면 아래 4개의 카테고리 정도입니다. 관련 주제에 어떤 세션들이 준비되어 있는지 짚어봅니다.
디지털 마케팅에서 이제 인공지능(AI)이 빠질 수 없겠죠. AI로 마케팅에 들어가던 인풋을 줄여주거나 성과를 개선하거나 데이터를 활용하는 내용 위주인 듯합니다.
이주원 Meta | Head of Marketing Science, Korea
https://ko-kr.facebook.com/business/ads

안재균 Moloco | 한국 지사장

Andy Carvell Phiture | CEO

이수현, Snowflake | 테크 에반젤리스트

Adrien Kwong, Xtend | Chief Commercial Officer
신창섭 X 코리아 | 대표
CRM: Customer Relationship Management 고객관계관리라는 아주 넓은 의미의 단어로 통용되고 있는 CRM 마케팅은 사용자와 닿는 메시지(팝업 배너, 앱푸시, 카카오톡, 문자, 이메일 등) 위주인데요.
퍼포먼스 마케팅보다는 비용 효율적이고(ex. 광고 소재 클릭당비용 보다는 카톡 발송 비용이 더 저렴한 경우), 웹/앱에서 사용자 행동 기반 개인화가 가능해 그로스해킹/그로스마케팅의 방법론으로도 많이 활용됩니다.
고주연, Braze | Area Vice President of Korea
이건희, 마티니 | 팀장
조형구/강하은, 29CM | Growth Marketer
최동훈, Amplitude | Senior Korea Partner Sales Manager
이재철, 마티니 | 팀장, 이형일, BKR | 이사
조경상, NNT | CEO
민병철, PIEDPIXELS | 사업 이사
오담인, 윤정묵, 장소영, 김형준, AB180 & Airbridge | Customer Success Team
애드테크는 Advertisement+Tech, 마테크는 Marketing+Tech로 광고와 마케팅에 있어 기술을 접목한 형태를 말합니다. 웹이나 앱에서의 성과 측정 및 사용자 행동 분석 등에 필요하죠.
정헌재, AB180 & Airbridge | CPO
김형빈, Viva Republica (Toss) | 부문장
✅ Shaping Android’s Privacy Sandbox
Pan Katsukis, Remerge | Co-Founder & CEO
호명규, Amplitude | 한국영업총괄
진겸, 당근 | 팀장
원하윤, Liner | PM
김동훈, 도소희, 현대카드 | Online Marketing
Bob Wang, PubMatic | Country Manager, Greater China & Korea
이승제, 딜라이트룸 | Product Owner, BD Lead
김나은, AB180 & Airbridge | VP of Growth
최동훈, Amplitude | 한국비즈니스총괄
최준호, Braze | Partner Sales Director
이수현, Snowflake | Tech Evangelist
윤가비, Apptweak | 한국 지사장
#글로벌, #애드테크·마테크, #트렌드 #프라이버시 #게임 #제품분석 #AI #MMP #UA #크리에이티브 #풀퍼널마케팅 #CRM #수익화
그로스마케팅, 그로스해킹, 그로스전략은 아직까지도 유효한 트렌드인 듯합니다. 그렇지만 결국 그로스를 이뤄내기 위해서는 조금 더 세부적인 부문의 실행 방안들이 필요합니다.
실행방안 #풀퍼널 #제품분석 #UA #크리에이티브 #CRM #수익화
사용자 여정의 풀퍼널(Full-Funnel)과 제품을 분석했을 때 프로덕트의 상황에 따라 UA(User Acquisitio, 신규 사용자 획득)에 초점을 맞춰야 할 수도 있고, 크리에이티브를 다변화하며 소재 A/B테스트를 운영해야 할 수도 있고, CRM을 통해서 사용자들에게 다음 단계 혹은 리텐션을 유도해야 할 수도 있고, '구매 전환'을 통한 수익화를 최우선으로 해야 할 수도 있습니다.
.
.
.
최근에 작은 브랜드를 운영하시는 대표님을 만나 뵌 적이 있었는데, 정말 열심히 하는 분이었습니다. 주말이면 온갖 웨비나와 세미나를 섭렵하시고 책도 읽고 강의도 들으시더라고요. 마케팅이 아닌 다른 부문에서 한평생 일하시다가 중장년의 나이에 공부를 하다 보니 따라가고 싶어 노력하신다 하셨어요.
이런저런 이야기를 하다가 저는 대표님께, 이제는 그만 듣고 또 공부하고 그냥 해야 할 때라고 말씀드렸습니다. 지금 수능 보고 낮은 점수받기 싫어서 계속 인터넷 강의 듣는 N수생 같다고요.
할 때는 해야 합니다. 다만 남들이 이미 풀어본 문제를 어떻게 푸는지 알고 가면 좋겠죠. 그 방식이 꼭 나에게도 맞을 거라는 보장은 없지만, 그래도 참고하면 방향성을 잡기에는 훨씬 수월하니까요. 그래서 디지털 마케팅 세미나들이 꽤 유용하지 않나 싶습니다.


최근 데이터 시각화 및 분석 도구들이 발전하면서 사용자 친화적인 인터페이스가 중요해지고 있습니다. Google Looker Studio는 이러한 요구에 맞춰 다양한 기능을 제공하며, 그 중 하나가 선형(Line) 차트와 막대(Bar) 차트를 전환할 수 있는 토글 스위치 기능입니다. 물론 기본적인 제공 기능 아니지만 루커스튜디오의 기능을 활용하면 간단하게 구현 가능합니다.
데이터를 분석하는 과정에서 서로 다른 유형의 차트를 사용하면 데이터를 다양한 각도에서 시각화할 수 있습니다. 예를 들어, 막대 차트는 특정 시점의 데이터를 비교하는 데 유용하며, 선형 차트는 시간에 따른 변화를 나타내는 데 적합합니다. 이러한 차트들을 손쉽게 전환할 수 있는 기능이 있으면, 사용자는 더 쉽게 다양한 인사이트를 얻을 수 있습니다.
💡스위치 필터 사용 시 매개변수는 숫자형만 반응. 따라서 텍스트가 아닌 데이터 유형을 숫자로 설정하여 매핑.


💡BarIF(차트 타입 = 1, Revenue, null)
💡LineIF(차트 타입 = 2, Revenue, null)

이러한 토글 스위치 기능은 사용자에게 더 나은 데이터 시각화 경험을 제공합니다. 사용자는 필요에 따라 차트를 전환하며 데이터를 더 직관적으로 이해할 수 있습니다. 이는 데이터 분석의 효율성을 높이고, 더 나은 결정을 내리는 데 도움을 줍니다.
Google looker Studio에서 선형 및 막대 차트를 전환하는 토글 스위치를 구현하는 방법을 알아보았습니다. 이러한 기능은 데이터 분석을 더욱 직관적이고 효율적으로 만들어 줄 것입니다. 이제 여러분도 데이터 시각화를 한 단계 업그레이드 해보세요.

앰플리튜드(Amplitude) Product Analytics, PA라고도 불리는 분석 솔루션 중 하나입니다. 구글에 '앰플리튜드'를 검색했을 시 스폰서(광고) 제외 두 번째 위치에 제 브런치의 글이 나옵니다. 어떻게 했을까요?

https://brunch.co.kr/@marketer-emje/8

상위노출 방법 전에 SEO의 개념을 먼저 훑고 갑니다!
Search Engine Optimization의 약자로, 검색엔진을 최적화한다는 뜻입니다. *검색엔진은 Google, Naver와 같이 '검색'을 통해 정보를 찾아주는 플랫폼이죠.
즉 SEO란 검색엔진에 노출되는 페이지를 최적화하여 상위 노출을 시키고, 특정 키워드를 검색한 사용자들이 상위 노출된 페이지를 보고 클릭하여 사이트에 '무료'로 유입될 수 있도록 하는 것을 말합니다.
사실 SEO 최적화라는 말은 Optimiziation의 뜻이 중복되는 말이지만, '최적화'가 가장 중요한 부분이니 만큼 강조된다고 생각할 수 있습니다.
SERP는 Searh Engine Result Page의 약자로 검색 결과 페이지라는 뜻입니다. 검색엔진에 특정 단어를 검색했을 시 노출되는 결과 페이지를 말합니다. 구글에 'SEO 최적화'를 검색했을 시의 SERP를 예시로 보면
1. 추천 스니펫 영역 2. 개별 사이트/페이지 노출 영역으로 구분되어 있네요. 구글 SERP의 구조 상, 스니펫은 없는 경우도 있고, 광고(sponsor)가 추가되는 경우도 많습니다.

CPC가 O원입니다. 배너 광고나 검색 광고처럼 Click per Cost(클릭당 비용)이 발생하지 않습니다. 즉 SEO 최적화에 의해 상위노출된 페이지로 생기는 트래픽은 '무료'로 발생한다는 것이죠.
이는 마케팅에서 중요한 포인트입니다. 구글 검색광고나 네이버 검색 광고 중 경쟁 강도가 높은 키워드들의 경우 한 번의 클릭에 1, OOO원은 기본이며 비싸게는 1O, OOO원~2O, OOO원의 비용이 듭니다. (단 한 번의 클릭인데요! 심지어 그다음 단계로 전환될 것이라는 보장도 없습니다, 실수로 눌려서 예산은 소진됩니다.)
그런데 SEO 최적화로 상위노출이 되는 페이지들은, 맨 처음 페이지 제작에 들어가는 초기 비용을 제외하면 추가 비용이 들지 않습니다. 꾸준히 새로운 사용자가 유입되고, 트래픽이 발생합니다.

앰플리튜드 관련 글은 4월에 조회수 2,000 > 5월에 조회수 3,000 > 7월에 조회수 4,000을 돌파했습니다.
다른 브런치 글들에 비하면 작게는 4배, 크게는 10배 차이입니다.

물론 미미한 숫자이지만 이렇게 생각하면 꽤 크지 않나요? 이런 자연 유입이 여러 키워드에서 잡힌다면 DAU/MAU에 꽤 유효하게 작용하게 됩니다.
클릭당비용(CPC) 외에 클릭률(CTR)을 본다면, 자연 영역에서 최상위 노출이 될 시 클릭률이 최대 53%에 달한다는 결과가 있었습니다. (*제가 사용자일 때도, 전 스폰서/광고가 걸린 페이지는 거의 안 누르긴 합니다.)

SEO 최적화, 즉 검색엔진에 잘 맞는 페이지로 만들어줘야 상위노출이 잘 잡힙니다. 여기서 SEO 방법론은 몇 가지로 나눌 수 있습니다.
웹사이트 내부에서 SEO를 최적화할 수 있는 요소입니다. 타이틀 태그와 메타 설명(meta description), 헤더 태그(header tag: H1, H2, H3...), 키워드 선정 및 사용, 콘텐츠 품질(이미지 포함), 링크 활용, 로딩 속도, 모바일 친화성 등이 있습니다.
내부에서 관리할 수 있는 영역인 것이지, 내부에서의 요소는 외부에도 고스란히 영향을 미칩니다. 무신사의 디스이즈네버댓 브랜드 페이지를 보면 내부에서 기재해 둔 텍스트가 구글 검색 시 동일하게 노출되는 것을 확인할 수 있습니다.


웹사이트 외부에서 SEO를 최적화할 수 있는 요소입니다. 백링크(back-link), On-page SEO에서는 페이지 내에 링크를 걸었던 것과 반대로 링크가 걸림 '당하는 것'입니다. 검색엔진에서 노출에 있어 선호하는 신뢰도가 높은 사이트 등 다른 사이트에서 자신의 사이트로 연결되는 링크가 있으면 좋습니다. 이외 SNS 등의 소셜 미디어, 인플루언서 등의 활용이 있습니다.
제가 더 주요하게 소개하고자 하는 SEO 최적화 방법론은 콘텐츠 SEO와 테크니컬 SEO로 나눌 수 있습니다.
콘텐츠 SEO에 주요한 요소는 키워드와 콘텐츠, 메타데이터입니다.
키워드 최적화는 프로덕트/서비스와 사용자, 시장, 경쟁사(유사 서비스)에서 사용하는 키워드를 분석하고 활용하는 것이 중요합니다.
a. 프로덕트/서비스에서 사용하는 키워드
b. 사용자가 사용하는 키워드
c. 시장에서 사용하는 키워드
d. 경쟁사가 사용하는 키워드

콘텐츠 최적화는 앞서 키워드 분석을 통해 선정한 주요 키워드 위주로 콘텐츠의 내용을 채우는 것과 콘텐츠의 형식을 구조화하는 것이 중요합니다.
a. 콘텐츠의 내용
b. 콘텐츠의 형식

메타 데이터는 웹 페이지 관련 정보를 제공하여 검색 엔진 및 소셜 미디어 플랫폼 내 페이지의 표시 방식에 영향을 미칩니다.
메타 데이터(메타 태그) 최적화
메타 데이터는 웹 페이지의 정보와 속성을 설명하고 검색 엔진 및 소셜 미디어에서 공유할 때 사용되어, 사용자에게 페이지 내용을 이해시키고 검색 엔진이 페이지를 색인화하는 데 도움을 줍니다.
*HTML 구조는 웹 페이지의 레이아웃과 콘텐츠를 정의하고, 시맨틱 태그는 HTML 구조 내에 의미론적으로 중요한 부분을 강조하며 메타 데이터는 검색엔진과 사용자에게 그 정보를 제공하는 것입니다.


자사몰을 보유하고 있을 때는 위와 같은 요소들을 고려하는 것이 필요합니다. 다만 개인의 페이지일 때는 검색엔진에 따라 유리한 사이트들이 있습니다. 예를 들어 똑같이 글을 쓰는 플랫폼이라고 하더라도, '네이버'에서는 네이버 블로그만이 노출되는 것처럼 '구글'에서는 워드프레스, 티스토리, 브런치 등이 유리합니다.

신경 쓰지 않았습니다. 고려했다면 워드프레스 등으로 블로그를 구축했겠으나... 시간을 아끼고자 했습니다. 대신 구글 상위노출을 목표로는 브런치를, 네이버 상위노출을 목표로는 개인 블로그를 활성화시켰습니다.
신경 많이 썼습니다! 키워드를 찾고, 선정하고, 글감을 목록화했습니다.


약 60장의 페이지에 꾹꾹 눌러 만들었습니다. 성함/이메일/회사의 정보를 입력해 주시면 다운로드하실 수 있어요!




디지털 시대의 급속한 발전과 함께 마케팅 환경이 빠르게 변화하고 있습니다. 다양한 채널을 통한 고객 접점이 증가하면서 기업들은 복잡해진 고객 관계 관리(CRM)에 직면하고 있습니다. 이러한 상황에서 CRM 대시보드의 중요성이 더욱 부각되고 있습니다.
CRM 대시보드는 여러 채널에서 수집된 CRM 캠페인 데이터를 통합하여 분석하고, 현황을 한눈에 파악할 수 있게 해주는 강력한 방법입니다. 다양한 CRM 채널로 인해 단일 기준으로 분석하기 어려운 데이터들을 대시보드를 통해 효과적으로 통합하고 시각화함으로써, 마케터들은 보다 신속하고 정확한 CRM 마케팅 의사결정을 내릴 수 있게 됩니다.
이러한 CRM 대시보드의 활용은 단순히 데이터를 보여주는 것에 그치지 않습니다. 실시간으로 캠페인 성과를 모니터링하고, 고객 행동 패턴을 분석하며, 각 채널별 효과를 비교할 수 있게 해줍니다. 이를 통해 기업은 더욱 효율적인 마케팅 전략을 수립하고, 고객 경험을 개선하며, 궁극적으로는 ROI를 향상시킬 수 있습니다.
본 글에서는 범용적으로 활용가능한 CRM 대시보드를 템플릿을 제공합니다.
Looker Studio CRM 캠페인 대시보드 템플릿은 마케팅 캠페인의 성과를 실시간으로 모니터링하고, 데이터를 시각화하여 분석할 수 있도록 돕는 강력한 도구입니다. 이 템플릿을 통해 효과적인 의사결정을 지원하고, 전략을 최적화할 수 있습니다.



Looker Studio CRM 캠페인 대시보드 템플릿은 캠페인의 실시간 성과 모니터링, 데이터 시각화, 마케팅 전략 최적화를 목적으로 활용됩니다. 이를 통해 효과적인 의사결정과 전략적 개선이 가능합니다.
실시간 대시보드를 통해 데이터를 업데이트하고, 다양한 필터 기능을 사용하여 원하는 데이터를 정확히 추출할 수 있습니다. 맞춤형 리포트를 생성하여 필요에 따라 커스터마이즈된 분석이 가능합니다.
마케팅 팀, 경영진, 데이터 분석가 등 다양한 사용자들이 이 템플릿을 활용하여 캠페인 성과를 모니터링하고 분석할 수 있습니다.
1. 주기적인 업데이트
2. 필터 활용
3. 성과 지표 설정
4. 데이터 비교
5. 팀과 공유
템플릿은 마케팅 캠페인의 성과를 종합적으로 관리하고 분석하는 데 유용하며, 데이터를 기반으로 한 전략적 의사결정을 지원합니다.
.png)
지난 편에서는 각 솔루션별 데이터 수집 방법(바로가기)에 대해서 알아보았습니다.

1. Third Party 데이터 수집 자동화
2. 수집된 데이터 전처리하기
3. 시각화하기
이번에는 수집된 데이터를 활용하여 어떻게 전처리 해야 되는지 알아보겠습니다.
각 데이터 셋들은 분석하려는 차원(dimension)을 기준으로 집계(group by)를 통해서 동일한 형태로 전처리한 후 조인 연산을 통해 데이터를 통합하는 과정이라고 생각하시면 됩니다.
마케팅 성과를 분석하기 위해서 필요한 데이터 다음과 같습니다.
Dimension : 날짜(일별), 유입소스(GA4 = utm_source, Appsflyer = Media_source), 캠페인
Metric : 구매수, 매출, 인스톨 수
GA4가 웹, 앱 모두 트래킹을 할 수 있지만 WEB은 GA4, APP은 MMP로 성과를 합쳐서 보실 겁니다.
GA4, Firebase는 앱과 웹 내 고객 행동 분석에 주로 쓰이는 툴이고 MMP 는 광고 성과를 측정하는 툴이니깐요
그러면 이렇게 됩니다.
<GA4 데이터 집계> - WEB
Dimension : 날짜(일별), 세션 소스, 캠페인
Metric : 구매수, 매출
<MMP 데이터 집계> - APP
Dimension : 날짜(일별), Media_source, 캠페인
Metric : 구매수, 매출, 인스톨 수
집계된 두개의 테이블을 UNION 다시 한번 집계를 해줍니다.
이렇게 하면 집계된 웹앱 데이터 통합이 되었습니다. (MMP 데이터 전처리 과정은 생략)
Dimension : 날짜(일별), Media_source, 캠페인
Metric : 구매수, 매출, 인스톨 수
브레이즈 커런츠(braze currents)데이터는 유저 인게이지먼트 데이터입니다.
여기에는 유저별로 어떻게 우리 서비스로 참여를 하고있는지를 기록한 데이터들이 기록되어 있으니 메시지 발송 수단별로 노출, 클릭 성과들이 들어있습니다. 하지만 우리는 성과(구매) 판단은 MMP, GA4로 해야 하므로 서로 다른 데이터들을 어떻게 통합해서 볼지를 알아보겠습니다.
커런츠 데이터는 아래와 같이 구성이 되어있습니다.

위와 같은 데이터를 일자, 메세지 발송 타입, 캠페인 or 캔버스별 발송수, 노출수, 클릭수 데이터를 집계를 하기 위해서는 유니크한 ID를 나타내는 차원 데이터를 만들어 줘야 합니다.
동일한 유저라도 캠페인, 캔버스, 베리에이션 등 다양한 형태로 타겟이 될 수 있으므로, 아래와 같이 유니크한 차원 데이터를 만들기 위해 새로운 아이디를 생성합니다. (해당 아이디는 발송 타입별로 카운트하기 위해 활용됩니다.)
차원의 이름은 원하시는대로 명명하시면 되고 저는 user_id_dispatch_id 이렇게 명명하였습니다.
-- 태블로 계산식
IFNULL([User Id],'') + '-' +
IFNULL([Campaign Id],'') + '-' +
IFNULL([Message Variation Id],'') + '-' +
IFNULL([Canvas Id],'') + '-' +
IFNULL([Canvas Variation Id],'') + '-' +
IFNULL([Canvas Step Message Variation Id],'') + '-' +
IFNULL([Dispatch Id],'')
다음으로 캠페인 단위로 성과를 집계할 예정이기 때문에 캠페인 차원을 만들어줘야 합니다.
왜냐하면 브레이즈에는 캠페인과 캠버스로 나뉘는데 campaign_name 값이 존재하면 canvas_name 이 빈값이고 거꾸로 canvas_name 값이 존재하면 campaign_name이 빈값이기 때문입니다.
-- 태블로 계산식
IFNULL([Campaign Name],[Canvas Name])
{send_type}_click 이런 식으로 차원 이름을 명명하고 아래와 같은 태블로 계산식으로 차원을 만들어줍니다.
이렇게 되면 email_click, push_click, in_app_message_click 이벤트별로 ID(user_id_dispatch_id)를 생성됩니다.
-- 태블로 계산식
{ FIXED [user_id_dispatch_id],[Event Type] : COUNTD(IF CONTAINS([Event Type], 'inappmessage_click') THEN [user_id_dispatch_id] END)}
최초에 S3에 적재된 currents 데이터(avro 파일)를 DW에 적재할 때 파일별 Event 구분을 위해 Event_Type 칼럼을 생성하였습니다. (이전 글을 참고해 주세요)
['users.messages.email.Open.avro',
'users.messages.email.Click.avro',
'users.messages.pushnotification.Send.avro',
'users.messages.inappmessage.Click.avro',
'users.messages.email.Delivery.avro',
'users.messages.pushnotification.Open.avro',
'users.messages.inappmessage.Impression.avro']
-- 태블로 계산식
IF CONTAINS([Event_Type], 'email') then 'email'
elseif CONTAINS([Event_Type], 'push') then 'push'
elseif CONTAINS([Event_Type], 'inappmessage') then 'iam' end
이제 집계를 위한 전처리는 완료되었습니다(세세한 전처리 과정은 생략됨)
이제 위에서 만들었던 차원을 가지고 집계를 합니다.
일자별, send_type, campaign/canvas, device_category 별 오픈, 클릭, 노출, delivery 데이터는 아래와 같이 집계되었습니다.

통합된 GA4 / MMP 데이터와 커런츠 데이터를 통합해야 되는 과정이 또 남았습니다.
어떻게 이 두 데이터를 엮어야 될까요?
조인키를 위에서 집계한 차원 데이터로 잡고 Full Outer Join으로 데이터를 조인합니다.
이유는 특정 날짜에 브레이즈 커런츠 데이터는 존재하는데 성과 데이터(GA4, MMP) 데이터가 존재하지 않는다면 매칭될 수 없으니 누락이 되어버립니다. 거꾸로 성과 데이터(GA4, MMP) 데이터가 존재하는데 브레이즈 커런츠 데이터가 존재하지 않을 경우 누락이 되어버리기 때문입니다.
광고 성과 데이터 전처리하는 예시를 통해 Full Outer JOIN 이 어떻게 데이터를 처리되는지 예시를 통해 잠깐 확인해 보겠습니다
2024년 1월 1일 twitter 채널의 e 캠페인에서 비용이 1000원 소진했습니다. 그런데 GA4, MMP 데이터에는 해당 광고 채널의 캠페인에서 전환이 아예 일어나질 않았습니다. 하지만 비용이 발생했기 때문에 이 데이터를 버릴 수는 없겠죠? 무조건 살려야 됩니다.
거꾸로 광고 데이터에서 비용은 발생하지 않았는데 Attribution Window로 인해 전환이 발생했습니다. 이것도 버릴 수 없겠죠?
이 두 데이터에서 LEFT JOIN 또는 RIGHT JOIN을 수행하게 되면 조인키에 대응하지 않은 데이터는 매칭이 안되어 누락이 되어 버립니다. 이를 방지하기 위해서 INNER, LEFT OUTER, RIGHT OUTER 조인 집합을 생성하는 FULL OUTER JOIN을 수행합니다.
결과를 보면 각 테이블의 모든 데이터들이 출력이 되는 걸 알 수 있습니다.

본론으로 돌아와서!
Full Outer Join을 수행하기 전에 앞서 GA4, MMP 데이터를 합친 후 우리는 CRM 데이터만 필요하기 때문에 CRM 데이터만 필터를 합니다.
이제 Braze Current 데이터와 성과 데이터(GA4, MMP)를 날짜, 유입소스명, 캠페인명을 조인키로 두고 Full Outer Join 을 수행합니다.(분석하고자 하는 차원데이터가 추가로 더 있다면 추가로 필요한 차원도 조인키로 활용하시면 됩니다.)
이와 같은 방식으로 Paid 성과 데이터를 전처리 할 때도 위와 같은 방법으로 수행하면 됩니다.
데이터를 전처리 할 때 중요한 건 분석하고자 하는 결과물을 먼저 그려본 뒤에 결과를 도출하기 위해서 각 테이블을 어떻게 만들어 갈 것인지 생각하면서 만들어가면 됩니다. 실제로 전처리하다 보면 자잘하게 처리해야 되는 부분이 상당히 많습니다.
특히 데이터를 통합하기 위해서는 무엇보다 네이밍 컨벤션이 가장 중요한 점은 강조하지 않을 수 없습니다.
데이터 수집까지 잘했는데 캠페인 네이밍 컨벤션이 서로 다르다?.. 데이터 통합은 불가능합니다..
네이밍 컨벤션은 말 그대로 명명 규칙입니다.
위에서 언급한 대로 우리가 데이터 통합을 위해 차원 데이터를 조인키로 활용한다고 했었는데 캠페인 차원이 MMP, GA4, Braze or 광고 데이터가 모두 다르면 안 되겠죠? 아래와 같이 통일을 시켜야만 데이터를 연결할 수 있습니다.

여기까지 마케팅 데이터 수집부터 전처리 과정까지 알아보았습니다.
다음 글에서는 이 데이터를 활용해서 시각화 하는 방법을 살펴보겠습니다.


루커 스튜디오(Looker Studio)는 구글에서 제공하는 강력한 데이터 시각화 도구입니다. 다양한 데이터 소스를 연결하여 직관적인 대시보드를 만들 수 있으며, 이를 통해 복잡한 데이터를 쉽게 이해할 수 있습니다. 특히, 마케팅, 영업, 운영 등 다양한 분야에서 유용하게 활용될 수 있습니다. 루커스튜디오가 궁금한 분들은 해당 글을 참고해주세요.
인터랙티브 퍼널 차트는 사용자 행동을 단계별로 분석하여 시각적으로 표현하는 방식입니다. 특히, 마케팅 퍼널 분석에 유용하며, 고객이 제품이나 서비스를 구매하기까지의 과정을 시각화하여 각 단계에서의 전환율을 파악할 수 있습니다.
퍼널 분석에는 두 가지 전환율 분석 방식이 존재합니다:
이 두 가지 방식 모두 데이터의 절대값(absolute) 형태와 비율(rate) 형태로 나눠서 분석할 수 있습니다. 이를 통해 어떤 단계에 문제가 있는지 비교하면서 파악할 수 있습니다.
퍼널 분석을 통해 마케팅 전략의 효과를 검토하고 개선할 수 있는 인사이트를 얻을 수 있습니다. 예를 들어, 특정 단계에서 이탈율이 높다면 해당 단계의 문제점을 찾아 해결하는 방식으로 퍼널의 전반적인 전환율을 개선할 수 있습니다.
루커 스튜디오 인터렉티브 퍼널 분석 차트 만들기 | Looker studio
인터랙티브 퍼널 리포트를 작성하는 단계는 크게 데이터 준비, 바 차트 생성, 차트에 인터랙티브 기능 추가로 나눌 수 있습니다.
먼저, 데이터 소스를 연결한 후 필요한 데이터를 정리합니다. 예시는 GA4 데모 데이터를 활용 하였습니다.
계산된 필드와 매개변수 설정이 필요합니다.
아래 이미지에 활용할 매개변수 2가지를 만들어봅시다.

Drop-off type

Value type
데이터 혼합을 이후에 활용할 예정입니다. 데이터 혼합에서 매개변수 사용을 위해서는 매개변수를 측정기준으로 아래와 같이 변경하는 작업이 필요합니다.

앞서 살펴봤던 매개변수의 계산된 필드 변환을 포함하여 3가지 측정기준을 만들어 줍니다.
Drop-off type dim

Value type dim

Funnel step order #
GA4의 전자상거래 5개 이벤트를 선택하고 해당 단계의 순서를 지정하는 이벤트를 만들어줍니다.
Looker Studio 코드 1
CASE
WHEN 이벤트 이름 = "add_to_cart" THEN 1
WHEN 이벤트 이름 = "add_shipping_info" THEN 2
WHEN 이벤트 이름 = "begin_checkout" THEN 3
WHEN 이벤트 이름 = "add_payment_info" THEN 4
WHEN 이벤트 이름 = "purchase" THEN 5
ELSE NULL
END

GA4 – Checkout steps
앞서 정의한 5개 외 나머지 이벤트는 Null로 처리 되었습니다. 해당 이벤트는 분석에 활용하지 않을 예정이므로 필터를 이용하여 제외 처리를 해줍니다. 해당 필터는 이후 단계에서 활용하도록 하겠습니다.

퍼널 분석을 위해선 직전단계와 다음 단계 사용자의 차이를 구해야합니다. 다만 루커스튜디오는 단일 소스로 해당 계산을 하기가 어렵기 때문에 데이터 혼합의 교차 조인을 활용하여 단계별 유저 차이를 구하는 식을 만들 수 있습니다.


데이터 준비가 완료되면, '차트 추가' 메뉴에서 바 차트를 선택합니다. 바 차트를 생성한 후, X축과 Y축에 표시할 데이터를 설정합니다.
3.4.1 설정 탭
Abs users
Looker Studio 코드 2
IF(
Values type dim = "Absolute values"
,
Total users
,
null
)
Abs exited users
Looker Studio 코드 3
IF(
Values type dim = "Absolute values"
,
IF
(
Drop-off type dim = 'Funnel drop-off'
,
IF(Ref Funnel step order = 1 AND Funnel step order != 1, (Ref Total users - Total users),null)
,
IF(Ref Funnel step order = Funnel step order - 1, (Ref Total users - Total users),null)
)
,
null
)
% active
Looker Studio 코드 4
IF(
Values type dim != "Absolute values"
,
IF
(
Drop-off type dim = 'Funnel drop-off'
,
CASE
WHEN Funnel step order = 1 THEN 1
WHEN Ref Funnel step order = 1 AND Funnel step order != 1 THEN (Total users ) / Ref Total users
ELSE NULL
END
,
CASE
WHEN Funnel step order = 1 THEN 1
WHEN Ref Funnel step order = Funnel step order - 1 THEN (Total users ) / Ref Total users
ELSE NULL
END
)
,
null
)
% drop off
Looker Studio 코드 5
IF(
Values type dim != "Absolute values"
,
IF
(
Drop-off type dim = 'Funnel drop-off'
,
IF(Ref Funnel step order = 1 AND Funnel step order != 1, (Ref Total users - Total users)/Ref Total users,null)
,
IF(Ref Funnel step order = Funnel step order - 1, (Ref Total users - Total users)/Ref Total users,null)
)
,
null
)
3.4.2 스타일 탭

인터랙티브 퍼널 리포트는 다양한 마케팅 시나리오에서 유용하게 활용될 수 있습니다. 예를 들어, 고객의 구매 여정을 단계별로 분석하여 각 단계에서 발생하는 이탈율을 파악하고, 이를 개선하기 위한 전략을 세울 수 있습니다.
또한, 특정 마케팅 캠페인의 성과를 분석할 때도 퍼널 리포트를 사용하면 각 채널별로 고객의 반응을 비교할 수 있습니다. 이를 통해 어떤 채널이 가장 효과적인지 파악하고, 마케팅 예산을 효율적으로 분배할 수 있습니다.
