


Recent

데이터 기반 고객 이탈 방지 전략 4단계

마케터들이 가장 두려워는 지표가 있습니다. 바로 '이탈률'입니다. 지난달 대비 이탈률이 또 올랐다면, 많은 담당자들은 급하게 이탈 고객 복귀(윈백) 캠페인을 기획하거나 할인 쿠폰을 발송하는 등 ‘발등에 불 떨어진’ 캠페인을 진행하곤 합니다.
하지만 문제는, 이탈률 상승을 확인하는 시점에는 이미 고객들이 떠난 상태라는 점입니다. 사후 분석으로는 무엇이 잘못되었는지 파악할 수 있지만, 이미 이탈한 유저를 되돌리기는 어렵습니다.
실제로 한 글로벌 연구에 따르면, 신규 고객 확보 비용은 기존 고객 유지 비용보다 5~7배 더 많이 소요된다는 연구 결과가 있습니다. 반대로 생각해보면, 고객 이탈을 미리 감지해 고객 유지율을 단 5%만 높여도 25%에서 95%까지 수익을 증가시킬 수 있다는 의미입니다.
그렇다면 고객이 떠나기 전에 이런 신호를 조기에 포착하고, 장기 고객으로 전환시킬 수 있는 방법은 무엇일까요?
이번 아티클에서는 이탈 예방을 위해 주목해야 할 지표와 행동 패턴, 그리고 고객 리텐션을 높이는 실무 전략을 알아보겠습니다.
이탈 방지의 핵심 이해하기
먼저 고객의 이탈을 방지하기 위해서는 이탈의 본질을 제대로 파악하는 것이 중요합니다. 이탈에는 두 가지 일반적인 유형이 있습니다.
- 자발적 이탈 : 고객이 구독 취소, 서비스 중단 또는 앱 제거를 통해 자발적으로 발생하는 이탈
- 비자발적 이탈 : 결제 실패, 카드 만료 또는 계정 오류와 같은 수동적인 문제로 인해 발생하는 이탈
결제 오류나 시스템 장애로 인한 비자발적 이탈은 마케터가 통제하기 어렵습니다. 하지만 고객 행동 데이터에서 나타나는 자발적 이탈 신호들의 패턴들(로그인 감소, 사용량 감소, 메시지 참여도 하락 등)은 충분히 사전에 감지할 수 있습니다. 그렇다면 많은 팀들은 왜 여전히, 고객이 보내는 신호를 놓치고 있는것일까요?
.webp)
바로 '이탈률'이라는 결과에만 집중하기 때문입니다.
대부분의 마케터들은 해당 지표에 대한 뒤늦은 대응으로 이미 떠난 고객에게 이탈 고객 복귀(윈백) 캠페인 예산을 쓰고, 할인 쿠폰을 보내고, 이메일을 발송하는 일만 반복하곤 합니다. 하지만 진짜 중요한 건 고객이 떠나기 전 보이는 행동 변화의 패턴을 먼저 읽는 것입니다. 고객 이탈은 갑작스러운 결정이 아니라 고객이 보내는 여러 신호들을 놓친 결과이기 때문입니다.
'자발적 이탈 신호'든 '비자발적 이탈 신호'든, 이를 방치하면 팀 효율성, 캠페인 성과, 브랜드 건강 모두에 부정적인 영향을 미칠 수 있기 때문에, 데이터에서 '무엇을' 봐야 하는지, '어떻게' 대응해야 하는지만 알면 충분히 막을 수 있습니다. 그렇다면 어떤 지표로 이탈 직전 신호를 포착할 수 있을까요?
데이터로 이탈 신호 포착하기
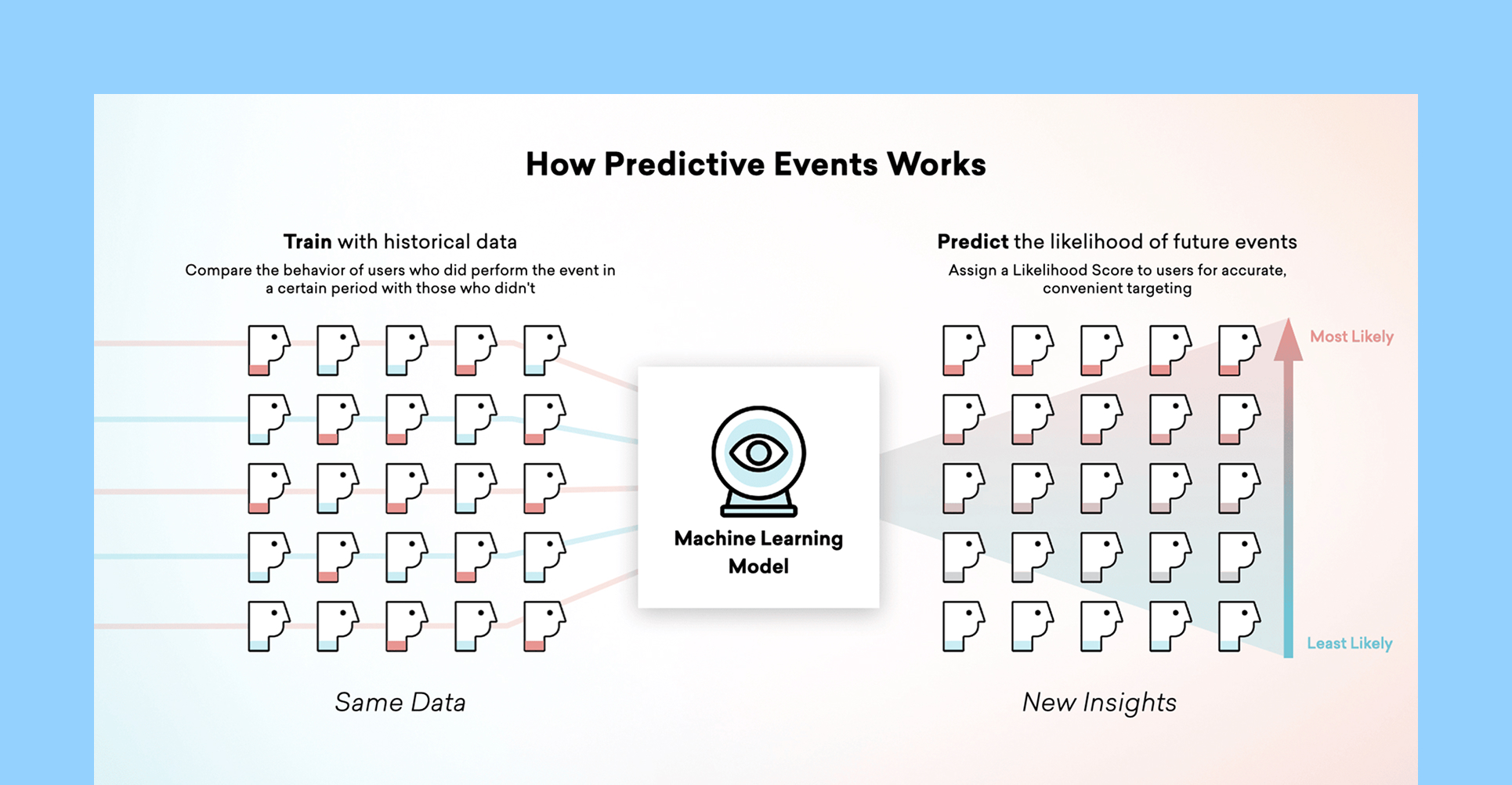
글로벌 CRM 솔루션 브레이즈는 모든 이탈 방지 모델에 아래 주요 신호들이 필수적이라고 강조합니다.
- 참여도 하락: 이메일 오픈율, 푸시 알림 클릭률, 앱 실행 횟수 같은 참여 지표가 떨어지기 시작했다면 주의 깊게 살펴봐야 합니다. 고객의 관심이 다른 곳으로 옮겨가고 있다는 신호일 수 있습니다.
- 서비스 사용 빈도 감소: 로그인 간격이 점점 길어지거나 아예 접속하지 않는 고객이 보인다면, 서비스에서 지속적인 가치를 느끼지 못하고 있다는 의미일 수 있습니다. 특히 일주일 이상 미접속 상태가 지속된다면 더욱 주의해야 합니다.
- 결제 및 구독 패턴: 결제 일정이 늦어지거나 상위 플랜에서 하위 플랜으로 다운그레이드하는 고객이 늘어난다면 위험 신호입니다. 현재 비용 대비 가치를 의심하고 있다는 뜻이기 때문입니다.
- 고객 불만 누적: 해결되지 않은 문제가 쌓이거나 고객 만족도 점수가 계속 낮게 나온다면 위험합니다. 서비스 불만족을 나타내는 대표적인 신호이기 때문에, 개선되지 않으면 고객이 조용히 이탈할 수 있습니다.
- 온보딩 과정 이탈: 신규 가입 후 튜토리얼을 중간에 포기하거나 핵심 기능을 전혀 사용하지 않는 고객을 유심히 관찰해야 합니다. 초기 온보딩 단계에서의 이탈은 장기 고객 유지에 치명적인 영향을 미칠 수 있습니다.
이런 신호들을 데이터로 포착하기 위해서는, 명확한 행동 지표 설정이 필요합니다. 구체적으로는 '유지 및 이탈 지표', '참여 및 행동 신호', '경험 및 만족도 측정 항목' 세 가지 영역으로 나눌 수 있습니다.
.webp)
유지 및 이탈 지표
- 이탈률: 특정 기간 동안 서비스 사용을 중단한 고객 비율입니다. 시간에 따른 변화를 추적할 수 있는 핵심 기준이 됩니다.
- 유지율: 이탈률과 반대되는 개념으로, 고객이 얼마나 오랫동안 서비스를 계속 사용하는지 보여줍니다.
- 고객 생애 가치(LTV): 한 고객이 서비스를 이용하는 전체 기간 동안 창출하는 매출 추정치입니다. LTV가 높을수록 고객 참여도와 충성도가 높다는 의미입니다.
참여 및 행동 신호
- 참여 중단 지점: 사용자가 이메일 확인, 로그인, 콘텐츠 상호작용을 멈추는 구체적인 시점과 위치를 찾아냅니다.
- 재활성화율: 재참여 캠페인을 진행한 후 실제로 다시 돌아오는 이탈 사용자 비율을 측정합니다.
- 가치 실현 시간(TTV): 신규 고객이 서비스에서 첫 번째 의미 있는 성과를 얻기까지 걸리는 시간입니다. 이 시간이 길어질수록 온보딩 단계에서 조기 이탈할 가능성이 높아집니다.
경험 및 만족도 측정 항목
- CSAT 또는 NPS 추세: 고객 만족도와 브랜드 추천 의향을 지속적으로 모니터링합니다. 점수가 하락하는 추세는 대개 이탈 증가로 이어집니다.
- 고객 지원 상호작용: 반복되는 불만, 해결되지 않는 문제, 느린 응답 속도 등은 고객 신뢰를 서서히 떨어뜨리고 결국 이탈로 연결될 수 있습니다.
이런 부정적인 신호들을 지표를 통해 관리하면, 실제 유저 이탈의 문제가 발생했을때 미리 감지하여 대처할 수 있습니다.
실제 사례로 보는 브레이즈 기반의 이탈 방지 전략
.webp)
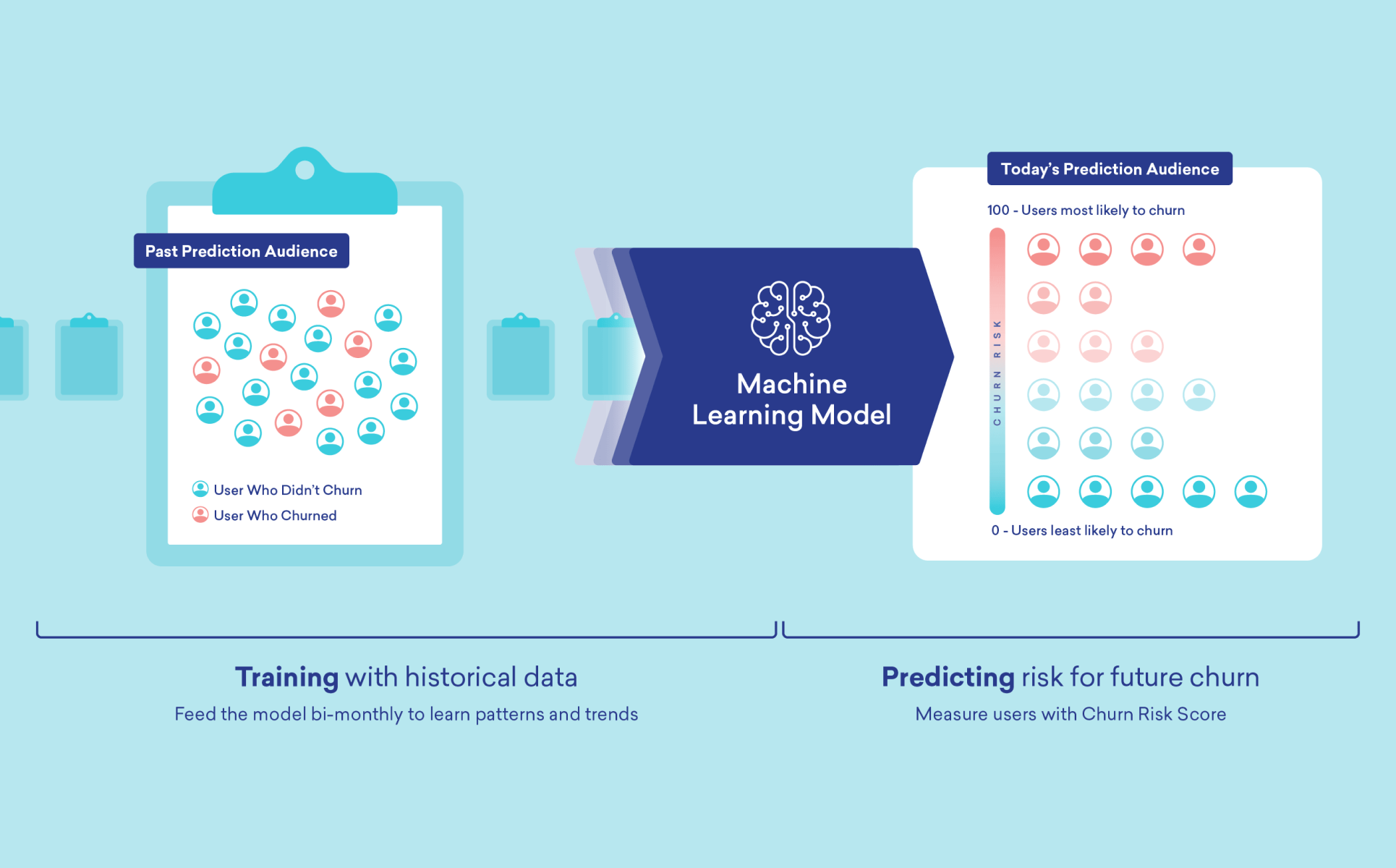
문제를 인식했다면 이제 이탈 예정 유저에게 어떤 전략을 펼칠지 고민해야 합니다. 이탈 방지의 핵심은 속도와 정확성입니다. 브레이즈를 사용하면 이탈 신호를 자동으로 감지하고 즉시 대응할 수 있습니다.
브레이즈는 실시간 세분화와 개인화된 고객 여정을 통해 단순한 문제 발견을 넘어 고객 라이프사이클 전반에 걸쳐 연결된 경험을 제공합니다. 실제로 이런 전략이 어떻게 작동하는지, 위 사례를 통해 브레이즈의 핵심 기능들을 바탕으로 구체적인 이탈 방지 방법을 살펴보겠습니다.
.gif)
1. 실시간 세분화
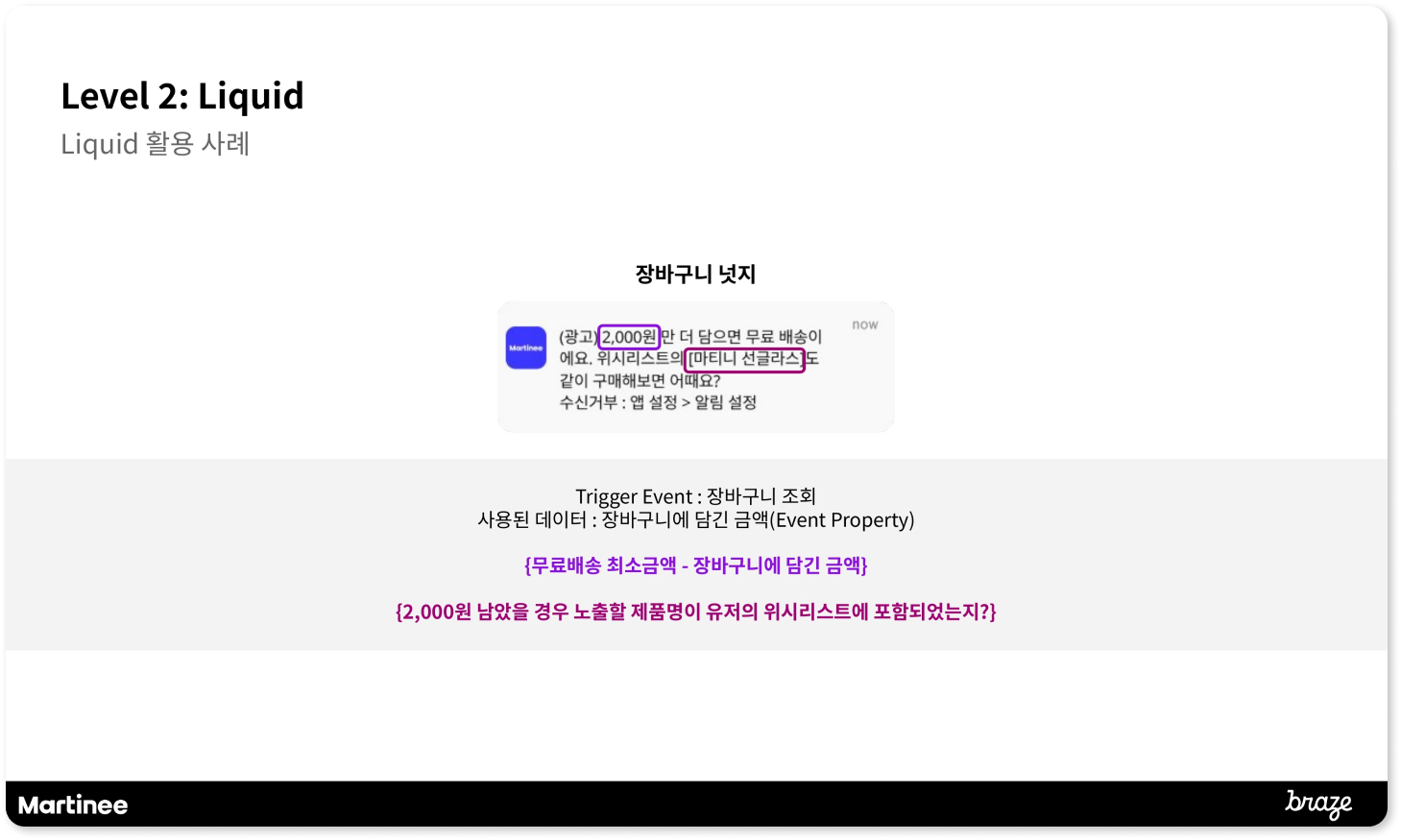
브레이즈의 Dynamic Segment 기능을 사용하면 고객 행동에 기반한 그룹을 쉽게 만들 수 있습니다. '제주도 여행 검색 후 3일간 미접속', '장바구니 3회 이상 포기', '푸시 오픈율 30% 이하 하락' 같은 구체적인 위험 신호별로 고객 그룹을 자동 생성할 수 있습니다. 이런 세그먼트는 실시간으로 업데이트되어 위험 고객을 놓치지 않습니다.
2. 예측 이탈 분석
Braze Predictive Suite를 통해, 각 고객이 언제쯤 떠날지 미리 예측 가능한 시스템을 구축할 수 있습니다. 고객의 검색 패턴, 접속 간격, 참여도 변화를 종합 분석해 이탈 위험도를 점수로 매깁니다. 예를 들어 7일간 여행 상품을 검색하다가 갑자기 접속이 끊긴 고객에게 높은 이탈 위험 점수를 부여해 우선 대응 대상으로 분류합니다.
3. 크로스채널 여정 오케스트레이션
.webp)
Canvas 기능을 통해 마케터가 이메일, 푸시, SMS, 앱 내, 웹 등 다양한 채널에서 메시지를 효과적으로 전달할 수 있습니다. 접속이 끊긴 고객에게 첫 번째는 푸시로 여행 상품을 추천하고, 반응이 없으면 이메일로 할인 쿠폰을 보내고, 그래도 반응이 없으면 SMS로 마지막 어필을 하는 단계적 접촉 시나리오를 브레이즈 Canvas로 자동화할 수 있습니다. 각 단계에서 고객이 반응하면 여정을 종료하도록 설정하면 됩니다.
4. 개인화된 재참여 유도 메시지
브레이즈는 Liquid 템플릿, Connected Content, AI 기반 아이템 추천 등 다양한 개인화 도구를 지원합니다. 이런 기능을 통해 브랜드는 각 사용자의 상황, 행동, 선호도에 맞춰 콘텐츠를 맞춤화하여 재참여 및 장기 고객 유지 가능성을 높일 수 있습니다.
예시로, "안녕하세요 고객님" 대신 "지난번 관심 보이신 제주도 여행 패키지에 특가 혜택이 추가되었어요"처럼 실제 검색 이력을 반영한 메시지를 보낼 수 있습니다.
5. 다양한 기능을 활용한 지속적인 최적화
이탈 방지 전략은 고정되어 있지 않기 때문에, 다양한 채널을 통해 어떤 메시지가 더 효과적인지 확인하고 계속 개선해야합니다.
"지금 예약하면 30% 할인" vs "내일까지만 특가" 같은 메시지 톤 차이나, 오전 9시 vs 오후 7시 발송 시간, 할인율 차이를 A/B 테스트로 비교 분석합니다. 마티니에는 이런 최적화를 통해 검색 후 이탈 고객의 재참여와 전환을 이끌어낸 경험이 있습니다.
결국 핵심은 고객의 미세한 행동 변화부터 복합적인 이탈 신호까지 브레이즈 같은 하나의 플랫폼에서 통합 분석하고, 개인별 맞춤 대응 전략을 자동 실행해야한다는 점입니다. 마티니는 국내 브레이즈 공식 파트너사로 이런 예측 모델 구축부터 크로스채널 캠페인 최적화까지 체계적으로 지원하고 있습니다.
고객 이탈 신호를 놓치지 않는 통합 시스템 설계 방법
.webp)
고객의 이탈 신호를 놓치지 않으려면 단편적인 대응이 아닌 통합 시스템이 필요합니다. 모든 고객 데이터를 하나로 연결하고, 위험 신호를 실시간으로 감지하며, 적합한 시기에 개입할 수 있는 구조를 만들어야 합니다.
이를 위한 통합 시스템 구축 방법으로는 먼저 고객 데이터의 통합(중앙화)를 추천합니다. 행동 신호, 참여 내역, 지원 상호작용, 제품 사용 데이터를 통합된 고객 뷰로 연결해야 실시간 대응이 가능합니다. 그다음에는 위험 고객군 파악을 통해 지난 14일간 미참여 유저나 취소 페이지 방문 후 이탈하지 않은 고객 등을 자동으로 분류할 수 있는 시스템이 있어야 합니다.
하지만 가장 중요한 것은, ‘실제로 이탈이 발생하는것을 막기 위한’ 신속한 대응입니다. 로그인 실패나 장바구니 포기 같은 이탈 신호가 나타나는 즉시 자동화된 재참여 여정이 시작되어야 합니다. 또한 목표 달성을 위한 단계별 계획 수립을 통해 온보딩 중단 유저와 기존 고객 이탈에 각각 다른 접근법을 적용해야 합니다.
이런 체계적인 이탈 방지 시스템을 구축하려면, 브레이즈 같은 전문 플랫폼 도입을 권장합니다. 실시간 고객 분석, 여러 채널을 통한 메시지 발송, 이탈 예측 기반 대응을 수작업으로 처리하기엔 한계가 있기 때문입니다. 자동화된 시스템으로 효과적인 고객 유지 전략을 실행할 수 있습니다.

브레이즈를 통한 데이터 기반
고객 이탈 방지 전략이 궁금하다면?
지금 마티니와 함께 국내 비즈니스에 딱 맞는 브레이즈 도입을 통해, 데이터 기반 고객 이탈 방지 전략을 세워보세요.

북극성 지표 A-Z: 프로덕트 전략의 필수 지표

북극성 프레임워크는 단일 지표인 북극성 지표를 기반으로 한 프로덕트 관리 모델로, 고객이 프로덕트에서 얻는 가치를 가장 잘 나타냅니다. 북극성 지표는 좋은 제품 전략 프레임워크지만, 오해하거나 잘못 사용하면 팀의 방향성이 틀어질 수 있습니다. 따라서 지표를 올바르게 설정하는 것이 매우 중요합니다.
모든 프로덕트에는 북극성 지표가 필요합니다. 북극성 지표는 비즈니스에 더 나은 방향성을 제시하고, 명확한 우선순위를 설정하고, 리소스를 절감하는 데 도움이 되기 때문입니다.
이번 아티클에서 북극성 지표란 무엇이며, 좋은 북극성 지표를 설정하기 위해서 어떤 것을 고려해야 하는지 알아보세요.
북극성 지표는 무엇이며, 왜 중요할까요?

북극성 지표는 프로덕트의 성패를 측정하는 핵심 척도입니다. 이 지표는 프로덕트 팀이 해결하려는 고객의 문제와 이를 통해 얻고자 하는 수익의 관계를 정의합니다.
특히, 북극성 지표를 통해 다음과 같은 내용을 확인할 수 있습니다.
- 프로덕트 팀이 무엇에 집중하고 무엇을 포기해야 하는지에 대해 명확한 방향성을 제공합니다.
- 프로덕트 팀의 영향력과 프로젝트 진행 상황을 사내에 전파하여 프로덕트 전략에 대한 지원을 확보합니다.
- 프로덕트 팀이 어떤 것을 목표로 해야 할지, 어떤 결과에 책임을 져야 하는지 확인할 수 있습니다.
많은 기업에서 프로덕트 팀의 성공은 비즈니스에 미치는 영향이 아닌, 얼마나 많은 일을 하느냐에 따라 결정됩니다. 하지만 ‘임팩트’ 중심의 문화가 없다면 비즈니스의 방향에 영향을 미치기 어렵습니다. 북극성 지표가 없다면 프로덕트 중심으로 성장하는 기업이 되기 어렵습니다.
좋은 북극성 지표의 특징
1. 좋은 북극성 지표는 고객 가치에 부합합니다

북극성 지표는 프로덕트 내 고객 행동에 대한 깊은 이해에서 비롯되어야 합니다. 고객의 ‘아하 모먼트’를 찾는 것도 비슷한 맥락입니다. 고객이 유입 초기 프로덕트에 머무는 순간을 찾았다면, 효과적인 북극성 지표를 찾았다고 할 수 있습니다.
즉, ‘DAU(Daily Active Users)’ 또는 ‘회원가입 수’와 같은 지표는 좋은 북극성 지표가 될 수 없습니다. 일회성으로는 유용할 수 있지만 고객이 프로덕트에 대해 무엇을 중요하게 생각하는지는 알 수 없기 때문입니다. 프로덕트 팀에서 느끼는 고객 가치를 북극성 지표와 연결하지 못한다면, 비즈니스는 잘못된 방향으로 흘러갈 수 있습니다.
2. 좋은 북극성 지표는 프로덕트 전략을 대표합니다

북극성 지표를 잘 설정했다면, 그 지표만 보더라도 누구나 프로덕트가 어떤 가치를 추구하는지 쉽게 이해할 수 있어야 합니다. 북극성 지표는 단순한 숫자가 아니라 기업의 전략과 비전을 한눈에 보여주는 역할을 합니다. 조직 내부에서는 팀과 부서가 같은 목표를 바라보도록 돕고, 외부에서는 기업이 궁극적으로 어떤 문제를 해결하고자 하는지를 설명하는 공용 언어가 될 수 있습니다.
예를 들어 여행 플랫폼에서 ‘재방문 고객 비율’을 북극성 지표로 설정했다면, 플랫폼이 일회성 예약을 넘어 장기적으로 고객 경험을 개선하는 전략을 갖고 있다는 점을 확인할 수 있습니다. 이처럼 좋은 북극성 지표는 프로덕트가 만들고 있는 핵심 가치를 드러내야 합니다.
3. 좋은 북극성 지표는 성공의 지표가 됩니다

좋은 북극성 지표는 성공의 선행 지표가 됩니다. 월별 매출이나 사용자당 평균 매출(ARPU)과 같은 후행 지표는 프로덕트의 영향력을 설명하는 지표가 되기 어렵습니다. 이 지표는 매출을 예측하기보다는 과거에 무슨 일이 일어났는지를 파악하는 지표입니다.
어떻게 좋은 북극성 지표를 설정할 수 있을까요?
적합한 북극성 지표를 선택하는 첫 번째 단계는, 비즈니스가 어떤 ‘게임’을 하고 있는지 파악하는 것입니다. 여기서 게임이란 ‘핵심 고객 참여 모델’을 의미합니다. Amplitude(앰플리튜드)에서 프로덕트에 대한 연구와 매달 1조 개 이상의 행동 데이터를 분석한 결과, 핵심 고객 참여 모델은 다음 중 하나로 분류될 수 있습니다.
프로덕트 팀은 위의 3가지 중 하나의 모델을 결정해야 합니다. 이는 프로덕트 전략을 수립하고, 좋은 북극성 지표를 정의하는 첫 번째 단계입니다.

위의 표는 이 위의 3가지 모델 중 하나를 채택한 기업 사례입니다. 다만, 같은 모델을 채택하고 있더라도 기업마다 고유한 프로덕트 전략을 가지고 있기 때문에 북극성 지표는 서로 다를 수 있습니다.
북극성 지표 측정을 위해 앰플리튜드(Amplitude)를 활용해 보세요

앰플리튜드를 활용하면 북극성 지표를 실시간으로 트래킹할 수 있습니다. 북극성 지표를 활용하면 팀 내에서 보다 가치 있는 커뮤니케이션이 가능합니다. 북극성 지표를 찾고, 구현하기 위해서는 프로덕트 팀이 단순 업무 상태 관리에서 벗어나, 보다 프로덕트에 깊이 몰입하고 아이디어를 공유하는 데 집중할 수 있습니다.

[Review] Snowflake World Tour 2025 | 마케팅 빌리지


지난 9월 9일, 코엑스에서 글로벌 AI 데이터 클라우드 ‘스노우플레이크(Snowflake)’가 개최하는 ‘스노우플레이크 월드 투어(Snowflake World Tour)’가 개최되었습니다. 제조, 금융, 커머스, IT 등 다양한 산업의 실무자 및 리더들이 모여 AI 시대의 데이터 활용에 대한 인사이트를 나눌 수 있는 자리였습니다.
마티니는 이번 행사에서 데이터를 활용해 비즈니스 성장을 이끌어가고자 하는 마케팅 실무자들을 위해 ‘마케팅 빌리지’ 세션을 준비했습니다. AI 시대 마케터의 역할에 대해 논의하는 Fireside Chat부터, 데이터를 활용한 Data Driven Marketing Journey, 롯데ON의 CRM 가속화 사례까지 스노우플레이크 월드 투어에서 마티니가 나눈 인사이트를 확인해 보세요.
Inspiring Fireside Chat: AI 시대, 마케터는 어떻게, 어디까지 성장할 수 있을까요?

사전 등록기간부터 관심이 집중되었던 Inspiring Fireside Chat 세션에서는, 마티니의 황수민 퍼포먼스 매니저와 스노우플레이크 Denis Persson CMO가 AI 시대 마케터의 역할과 성장 방향에 대해 이야기를 나눴습니다.

Denis Persson CMO는 글로벌 데이터 클라우드 기업인 스노우플레이크를 소개하며, 어떻게 회사를 전 세계로 확장해 현재 약 800억 달러의 시가총액을 갖춘 기업으로 성장시켰는지에 대한 경험을 공유했습니다. 특히 스타트업과 엔터프라이즈 환경에서의 차이를 짚으며, 각 단계에서 집중해야 할 과제와, 업무 방식의 차이에 대해 언급했습니다.

또한 빠르게 발전하는 AI 시대에, 마케터는 ‘전략가’로서, 창의적인 문제 해결 능력과 끊임없이 배우는 태도를 갖는 것이 중요하다고 강조했습니다. 글로벌 기업의 CMO로서 새로운 팀원을 영입할 때는 “스킬셋뿐 아니라 성장 가능성과 협업 태도를 중시한다”는 점도 덧붙였습니다.

마티니의 황수민 퍼포먼스 매니저는 AI 도입이 가속화되는 환경에서 마케팅 생태계의 변화에 대해 언급했습니다. Denis Persson CMO는 “기술이 평준화를 만들어낼수록 고유의 가치와 차별화된 고객 경험이 더욱 중요해진다”고 이야기 했습니다. 더불어 마케팅 조직과 데이터 조직 간의 협업이 필수적이라는 점을 강조하며, 데이터 기반의 의사결정을 위해 긴밀하게 소통해야 한다고 조언했습니다.

마지막으로 청중들에게는, “급격한 변화 속에서도 두려워하지 말고 새로운 기회를 탐색해야 하며, 지금은 결과를 만들어내는 동시에 커리어를 성장시킬 수 있는 시대”라는 메시지로 응원을 전하며 세션을 마무리했습니다.
Data Driven Marketing Journey: 데이터 기반 마케팅 의사결정

이어서 진행된 세션은 마티니 이재철 그로스 리드의 진행으로, 데이터 기반 마케팅 의사결정에 대한 인사이트를 나눴습니다. 데이터 기반 마케팅을 단순한 분석 차원을 넘어, 어떻게 인사이트 발굴과 실질적인 성과로 연결할 수 있는지를 실제 사례 중심으로 풀어낸 시간이었습니다.


먼저 F&B 업계 사례를 통해 AARRR 퍼널 기반 지표 설계에서 출발해 지표 분석, 가설 도출, 실험 설계 및 진행, 그리고 결과 분석으로 이어지는 과정을 소개했습니다. 특히 다양한 변수와 그룹을 대상으로 최적의 조합을 찾아가는 실험 과정을 공유해 현장의 높은 관심을 끌었습니다.

이어진 커머스 사례에서는 퍼포먼스 마케팅과 CRM, 그리고 제품 분석을 결합한 통합 고객 분석을 다뤘습니다. 고객 행동 데이터를 기반으로 한 가설 수립과 실험 과정을 보여주며, RFM 그리드 분석을 통해 ‘나쁜 유저 집단을 좋은 유저 집단으로 전환’하고 이를 유저 고착화로 연결하는 전략을 소개했습니다. 또한 이에 맞춰 설계된 CRM 시나리오와 실행 과정을 구체적으로 설명했습니다.

세션의 마지막에서는 성공적인 데이터 기반 마케팅을 위해 반드시 갖춰야 할 조건으로 정확한 데이터, 통합적 분석, 빠른 실행력을 강조했습니다. 더 나아가 AI 도입이 가속화되면서, 데이터 드리븐을 넘어 AI 드리븐으로의 전환이 이루어지고 있음을 짚으며, “마케터의 역할은 단순 실행자가 아니라 전략을 기획하고 방향을 제시하는 지휘자로 변화해야 한다”는 메시지를 전했습니다.
참가자들은 실제 사례와 실행 과정이 담긴 이번 강연을 통해, 데이터 드리븐 마케팅 여정의 실질적인 접근 방법을 배우고 앞으로의 변화를 준비할 수 있는 인사이트를 얻을 수 있었습니다.
롯데ON은 이렇게 합니다: 개발자 없이도 가능한 CRM 가속화 성공 사례

롯데ON의 사례를 중심으로 구성된 세 번째 세션에서는, 롯데ON이 스노우플레이크 데이터 연동을 통해 어떻게 CRM 캠페인을 구성하고 성과를 만들어 가고 있는지에 대해 소개했습니다. 마티니의 김찬희 CRM Part Lead는 롯데ON의 비즈니스 단계와 현황에 대한 소개를 시작으로, 롯데ON과의 협업 과정을 소개했습니다.

롯데ON과의 협업에서는 A/B 테스트로 검증된 캠페인 자동화, 비즈니스 지표 구축 및 개선, 신규 HTML 기반 IAM(인앱 메시지) 제작이 중점적으로 진행되었습니다. 특히 개발 리소스가 제한적이거나 서버 부하가 우려되는 상황에서, 스노우플레이크 연동을 통해 개발자의 직접적인 개입 없이도 다양한 데이터 활용이 가능했다는 점에 주목해볼 수 있었습니다.

롯데ON은 ‘리텐션 유지’라는 과제를 해결하기 위해 마티니와 협업하고 있습니다. 마티니와 롯데ON이 협업한 대표적인 세 가지 캠페인 사례를 세션에서 만나볼 수 있었습니다.

마지막으로, 롯데ON이 최근 집중하고 있는 과제와 향후 계획도 함께 공유되며 세션이 마무리되었습니다. 이번 사례는 데이터 인프라를 활용해 개발 리소스 제약을 극복하고, 실질적인 성과로 이어지는 CRM 캠페인을 운영할 수 있다는 가능성을 잘 보여주었습니다.
데이터 기반 마케팅의 모든 것
이번 행사는 AI 시대 마케팅의 방향성, 데이터 드리븐 마케팅의 실천 방법, 그리고 실제 기업의 성공 사례까지 다채로운 인사이트를 한 자리에서 공유할 수 있는 시간이었습니다. 각 세션에서 제시된 경험과 노하우는, 변화하는 환경 속에서 마케터가 어떤 역할을 해야 하는지에 대한 실질적인 길잡이가 되었습니다.
많은 분들이 현장에서 얻은 인사이트를 비즈니스에 적용해 새로운 도약의 계기를 마련하시길 기대합니다. 마티니는 앞으로도 다양한 파트너와 함께 더 깊이 있는 논의와 배움의 자리를 만들어가겠습니다.



Snowflake World Tour 2025 | 마케팅빌리지
주최 | Snowflake
일시 | 2025년 9월 9일 (화) 15시
장소 | 코엑스 컨퍼런스센터 2F 아셈볼룸 202-203호

[Review] Martinee ✕ Amplitude ✕ AppsFlyer VIP 세미나

지난 9월 3일, 여의도 콘래드 서울에서 ‘업계 리더를 위한 데이터 마케팅 인사이트’를 주제로 VIP 세미나가 진행되었습니다. 앱스플라이어(AppsFlyer)와, 앰플리튜드(Amplitude) 기반의 데이터 분석 및 활용 전략부터, 가장 최신의 마케팅 트렌드를 확인하고 공유하는 시간이었습니다.
활발한 네트워킹과 함께 유의미한 인사이트를 공유할 수 있었던 VIP 세미나 현장을 확인해 보세요.
Beyond the Click: 고객 여정 인사이트로 여는 풀 퍼널 성장

마티니 이선규 CEO 주도로 진행된 진행된 첫 번째 세션에서는 의미있는 전환을 만들어 내기 위해, 의미있는 클릭을 측정하고 분석해서 최적화하는 과정에 대해 이야기를 나눴습니다.

최근 시장 환경이 빠르게 변화하면서, ‘클릭’ 뒤에 숨은 의미를 파악하는 것이 중요해지고 있습니다. 이선규 CEO는 단순 유입을 넘어 의미있는 전환을 만드는 것이 중요하며, 이 과정에서 앱스플라이어, 앰플리튜드, 마티니가 어떤 역할을 할 수 있는지 전했습니다.
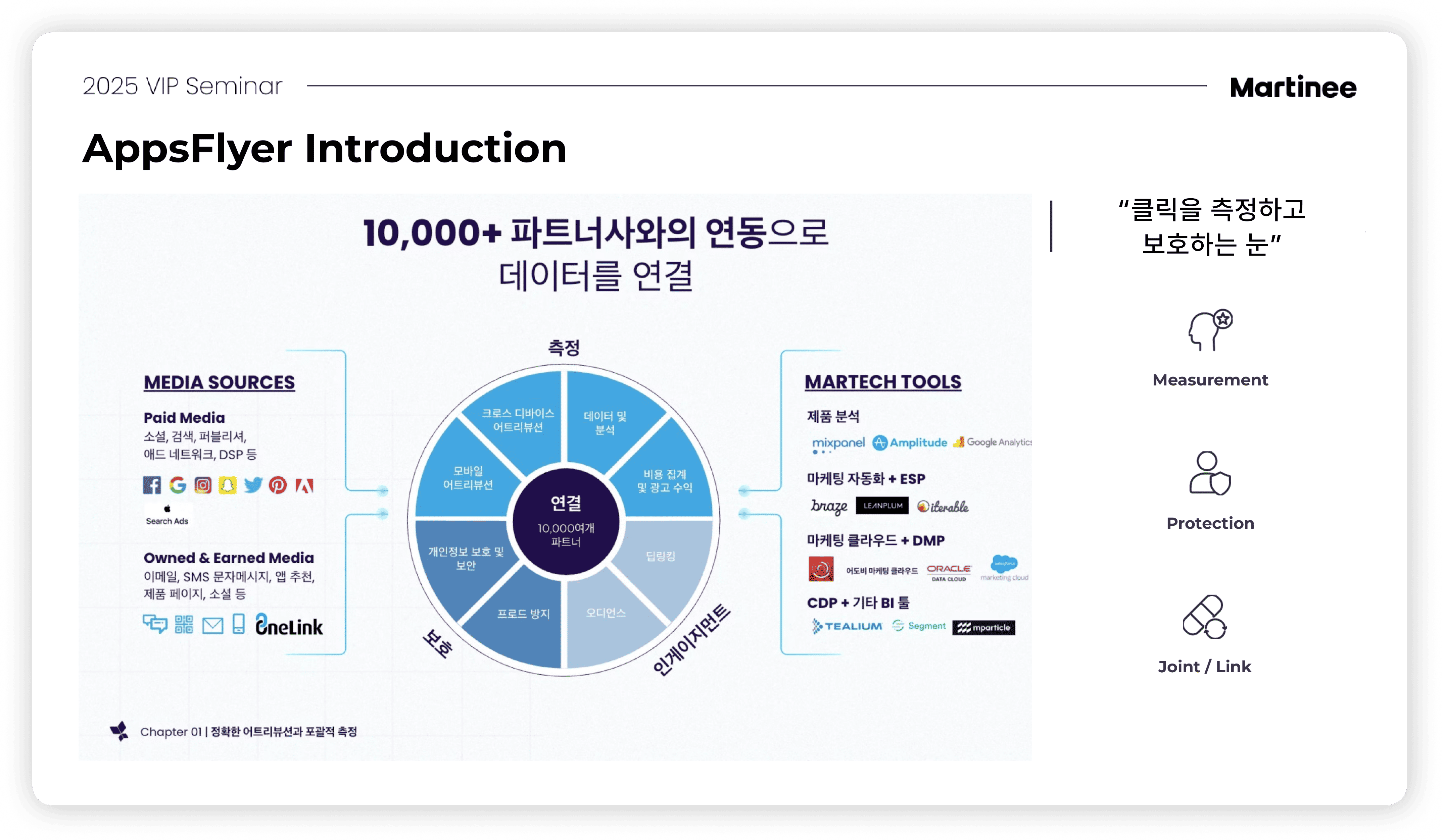
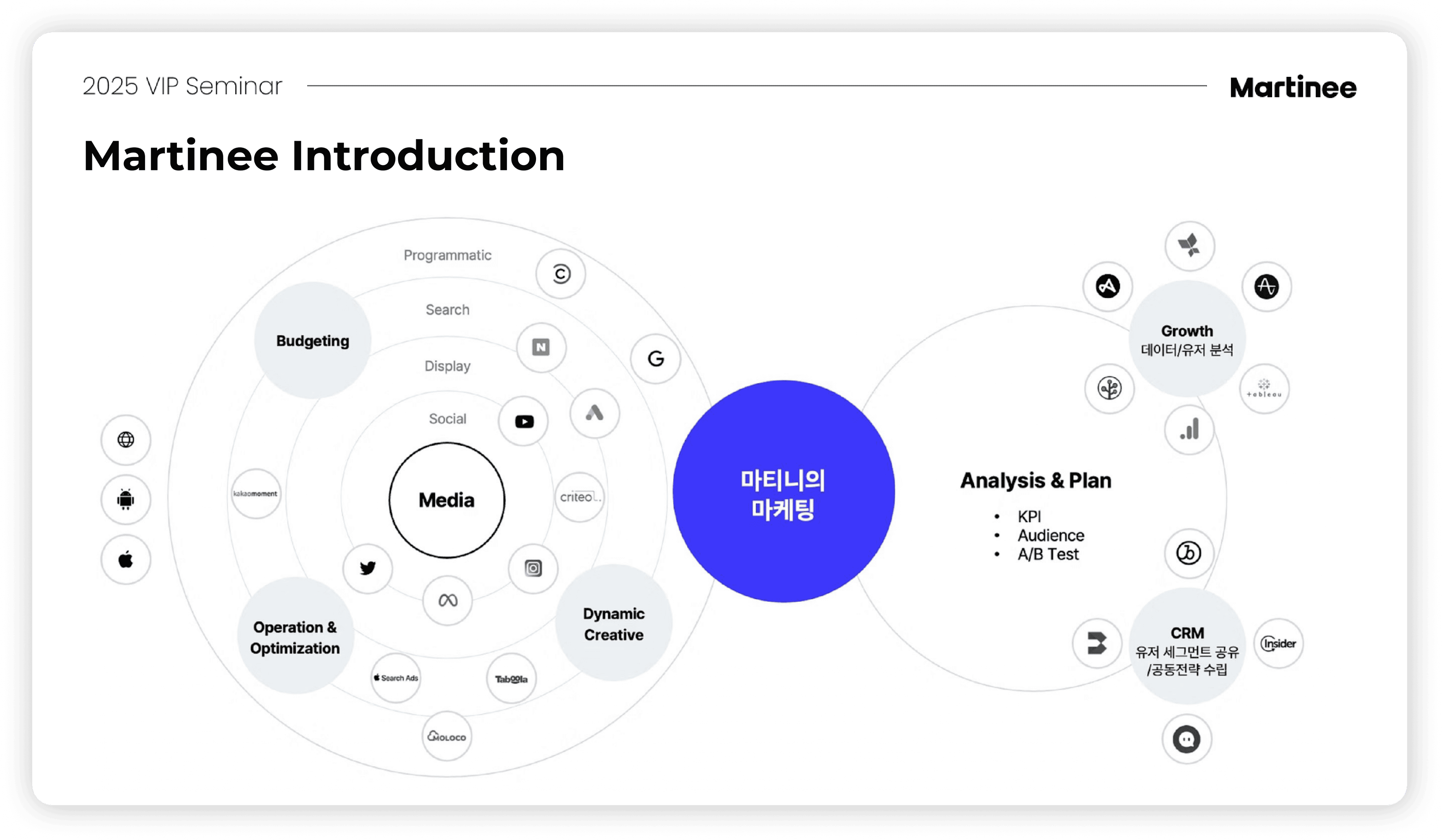
이 과정에서 앱스플라이어는 ‘클릭을 측정하고 보호하는 눈’으로, 앰플리튜드는 ‘고객 행동을 읽는 창’이라고 할 수 있으며, 마티니는 이를 연결하고 실행하는 통합자의 역할을 하고 있습니다. 세션을 통해 서비스 성장을 설계하는 과정에서 실질적으로 앱스플라이어, 앰플리튜드가 어떤 도움을 제공할 수 있는지 알 수 있었습니다.

특히, 의미있는 전환을 만들기 위해 마티니가 어떤 노력을 하고 있는지 살펴볼 수 있었습니다. 특히 퍼포먼스 마케팅, CRM 마케팅, 서비스 분석 조직의 시너지를 통해 풀퍼널 성장을 만들어 가는 과정을 구체적인 사례를 통해 확인했습니다.
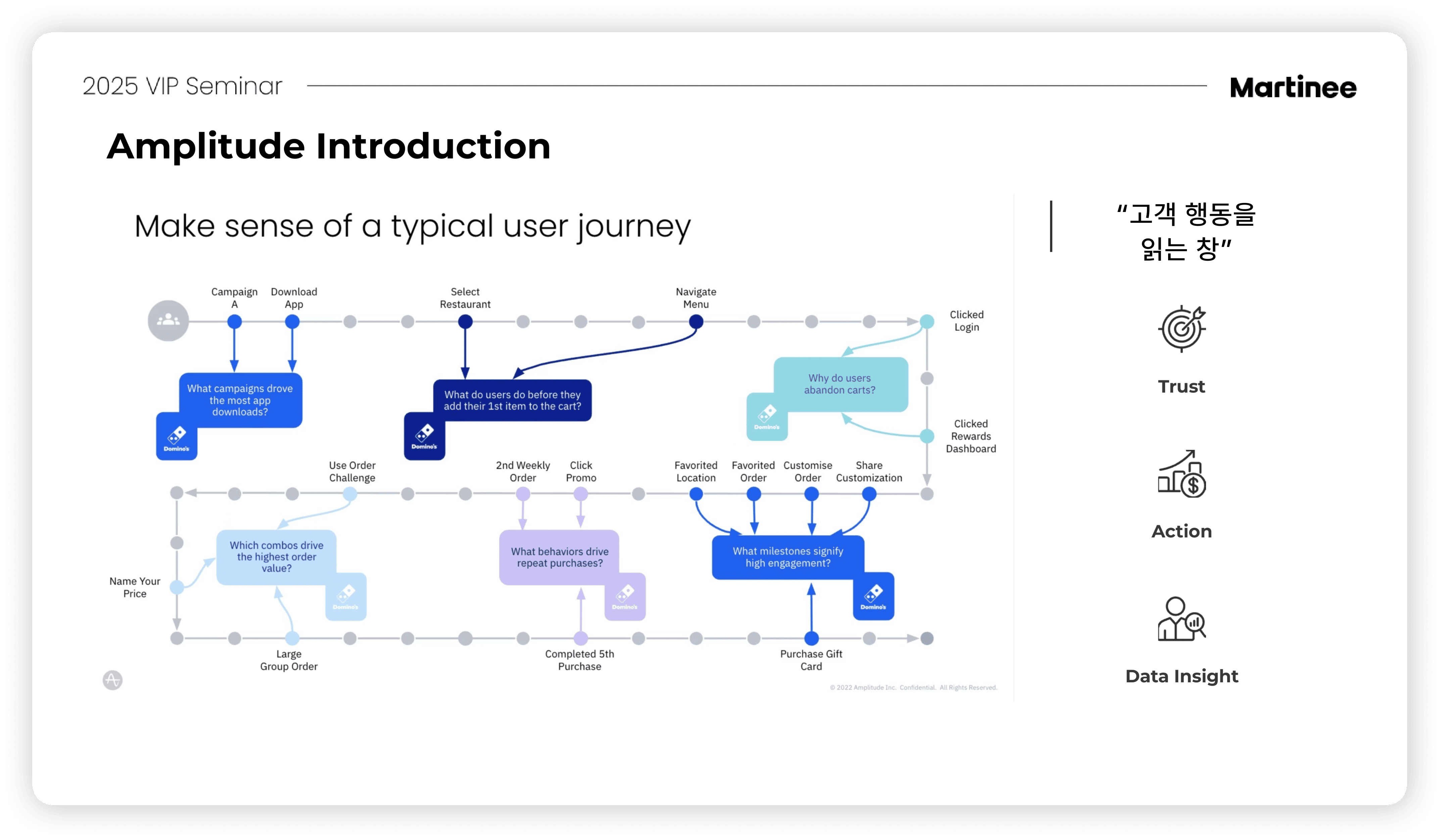
AI로 다시 그리는 그로스 스택: 인사이트에서 실행까지

앰플리튜드 최동훈 한국 비즈니스 총괄 주도로 진행된 두 번째 세션에서는, 앰플리튜드를 활용해 데이터에서 더 높은 수준의 인사이트를 발견하고, 이를 실행까지 연결할 수 있는 방법에 대해 알아보았습니다.

앰플리튜드 세션에서는 실제로 앰플리튜드가 제품 지표를 분석하고 인사이트를 얻는 과정에서 실질적으로 어떻게 도움이 되는지 확인했습니다.
단순 기능 설명을 넘어, 실제로 구현된 대시보드를 보면서 모든 내용을 직접 확인할 수 있었습니다. 특히 아직 공개되지 않은 신규 기능의 소식도 이번 세미나를 통해 먼저 만나볼 수 있었습니다.

앰플리튜드의 신규 기능인 AI 에이전트를 활용해 인사이트를 획득하고, 실행까지 연결하는 방법을 데모 영상과 함께 확인했습니다. 앰플리튜드 AI 에이전트는 단순히 질문에 답변하는 AI를 넘어 지표를 실시간으로 모니터링해 먼저 개선 방안을 제안하기 때문에, 프로덕트 팀의 리소스를 크게 절감할 수 있습니다.
오찬 및 네트워킹

세션 이후에는 식사와 함께 자유롭게 네트워킹 할 수 있는 자리가 마련되었습니다. 세션에서 나눈 이야기를 기반으로, 현업에서 MMP(Mobile Measurement Partner), PA(Product Analytics) 도입과 활용에 대해 고민 중이신 다양한 이야기를 들어볼 수 있었습니다. 특히 업계 리더 분들이 모여 각 업계의 데이터 활용 인사이트를 나눠주셔서 더욱 뜻깊은 자리였습니다.


이와 함께 소중한 시간을 내어 모여주신 참석자 분들을 위해, 럭키드로우를 통해 작은 선물을 전달드렸습니다. 마지막까지 적극적으로 참여해 주신 많은 분들께 진심으로 감사드립니다.
마티니와 데이터 기반 성장 전략을 설계하세요
마티니는 앰플리튜드, 앱스플라이어를 활용한 데이터 분석부터 더 많은 유입을 위한 퍼포먼스 마케팅, 의미있는 전환을 위한 CRM 마케팅까지 데이터 기반의 풀퍼널 마케팅 서비스를 제공하고 있습니다. 데이터를 기반으로 성장을 만들어 가고 싶으시다면, 지금 바로 마티니와 만나보세요.





Martinee ✕ Amplitude ✕ AppsFlyer VIP 세미나
주최 | Martinee, Amplitude, AppsFlyer
일시 | 2025년 9월 3일 (수) 10시
장소 | 콘래드 서울 6층 Studio 7

Braze Release Note 25.08
Braze는 고객 경험을 더 풍부하게 만들고, 마케터가 보다 효율적으로 CRM 캠페인을 운영할 수 있도록 꾸준히 프로덕트를 발전시키고 있습니다. 마티니는 브레이즈의 공식 파트너사로서, 지난 한 달 간 브레이즈에서 업데이트 된 기능과, 새롭게 공유된 소식을 가장 빠르게 전달합니다.
앞으로도 마티니 블로그와 링크드인, 인스타그램을 통해 브레이즈 업데이트 소식을 가장 먼저 만나보세요.
Canvas Context Step에서의 Timezone 사용
현재 얼리액세스 단계인 Canvas Context Step에서의 Date Type 데이터 사용 시, 자동으로 Timezone은 UTC로 적용됩니다.
우리나라는 UTC와 9시간 시차가 발생하여, 저장한 데이터에 따라 날짜가 바뀌어버리는 경우가 발생할 수도 있습니다. 따라서 Liquid를 통해 timezone을 설정하고 사용할 것을 권장합니다.
Timezone 설정 예시
사전 알람 신청한 A이벤트가 {{canvas_entry_properties.${event_start_date} | time_zone: 'Asia/Seoul' | date: "%Y-%m-%d %H:%M"}}에 시작돼요!
시간 계산을 위한 Liquid 예시
{% assign new_start_date{{canvas_entry_properties.${event_start_date} | date:'%s" | minus: 32400 %}
💡 Canvas Context Step

- Canvas 흐름 도중에 유저가 갖고 있는 정보를 변수로 저장하여, Message Step에서 미리 저장해둔 변수를 호출할 수 있는 기능입니다.
- Message Step에서
{{context.${example_variable_name}}}와 같은 형식으로 사전 저장된 Step을 호출할 수 있습니다. - Nested Objects는 지원하지 않습니다.
Segment Funnel Statistics
Segment Funnel Statistics를 통해 유저의 Funnel별 전환율을 확인할 수 있게 업데이트 되었습니다.
Segment 생성 또는 Campaign의 Target Audience에서 타겟 설정 시 각 필터를 걸 때마다 전환율을 확인할 수 있습니다.
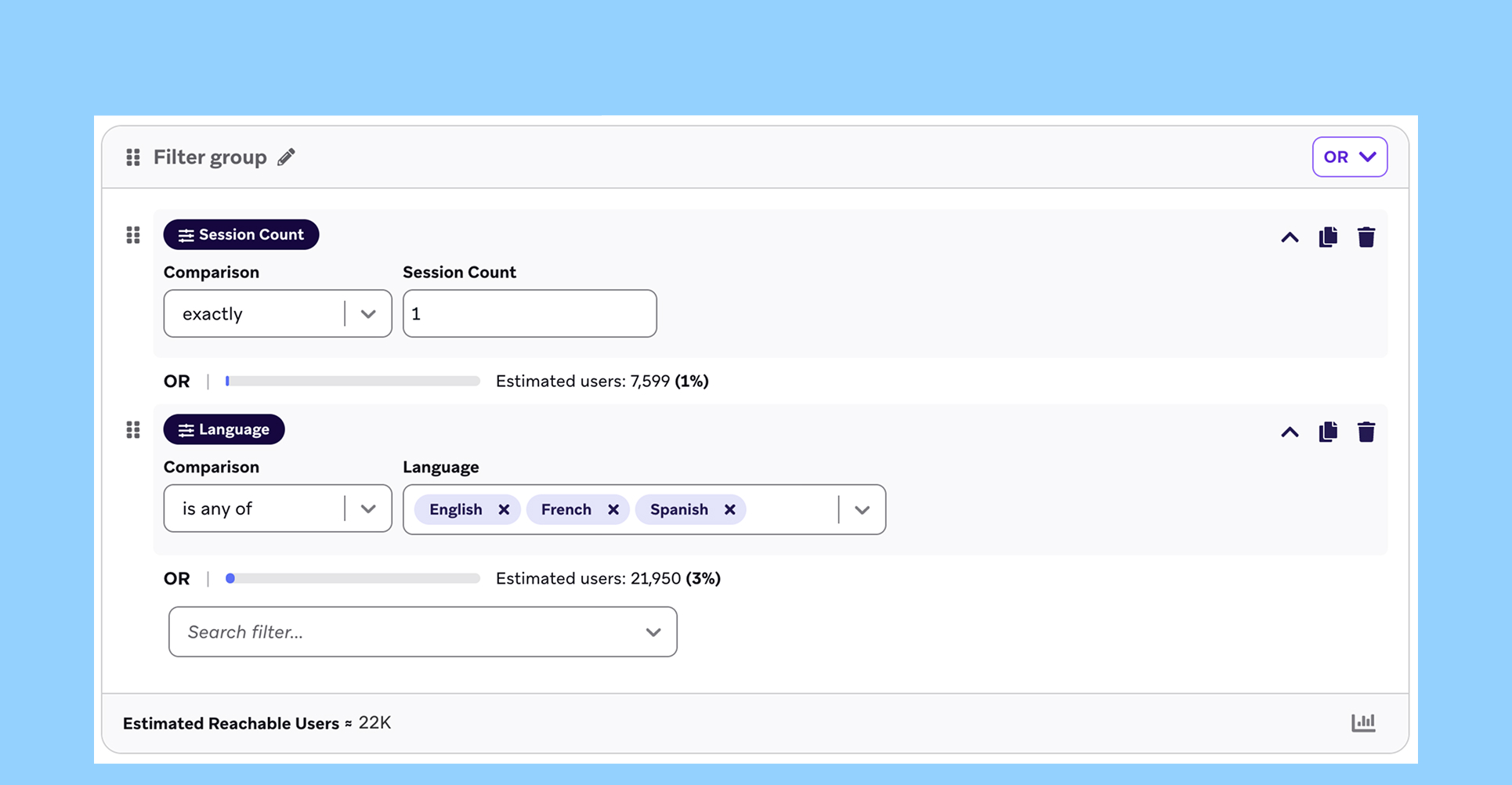
기존에는 단순 모수만 표기되어 전환율/이탈율 확인에 불편함이 있었는데요, 이번 업데이트로 필터별 전환율/이탈율 확인이 훨씬 수월해졌습니다.
더불어 이번 업데이트로 Segment 기능은 단순 타겟팅을 위한 용도 외에도 Funnel별 전환율을 확인하기 위한 용도로도 사용될 수 있습니다. 특히, 모수가 큰 필터부터 작은 필터까지 순서대로 걸면 Funnel 전환율 확인에 더욱 용이할 것 같습니다.
푸시 이미지 불러오기
/campaigns/details Endpoint는 캠페인의 상세 정보를 불러올 수 있는 API입니다.
이 API를 사용하여 아래 정보들을 불러올 수 있습니다.
- 메시지 내용
- 캠페인 스케쥴
- 처음/마지막 발송 시간
- 발송 채널
- 설정된 Conversion 정보
- 기타

이를 통해 현재 운영 중인 캠페인 현황을 확인하거나 히스토리를 파악하기에 용이한데요.
위 이미지와 같이 우리 서비스가 보내고 있는 모든 메시지들을 일괄 관리할 수 있습니다. 여기에 이번 업데이트로 푸시 이미지 정보도 함께 불러올 수 있게 되었습니다.
푸시 이미지는image_url, large_image_url object를 통해 불러올 수 있습니다.
BrazeAI Use Case
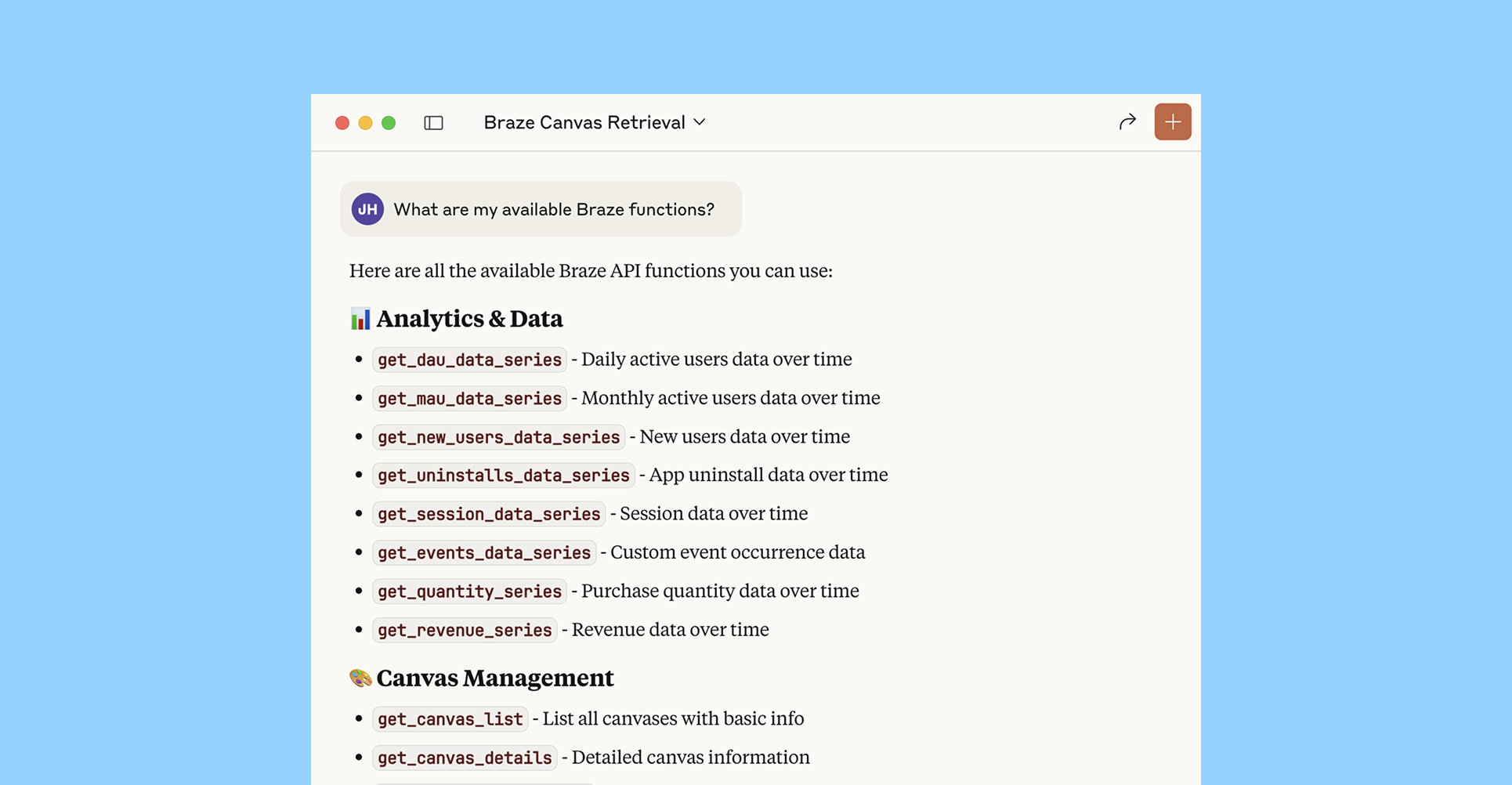
Braze 공식 문서에서 BrazeAI를 활용한 Use Case 아티클이 신규 게재되었습니다.
BrazeAI는 AI를 통해 유저 이탈/전환을 예측, 상품 추천, 발송 타이밍 개인화, 실험 변수의 개인화된 적용 등 다양한 기능들을 제공하고 있습니다.
이번에 추가된 Use Case는 아래에서 살펴볼 수 있습니다.
AI에게 Braze 데이터 분석 시키기
*본 기능은 현재 베타 버전입니다.
MCP(Model Context Protocol)은 AI 에이전트가 다른 플랫폼과 데이터를 연결하기 위한 프로토콜입니다.
이번 업데이트로 Braze에서 MCP 서버를 제공하여, AI로부터 Braze의 데이터를 열람하고, 분석을 요청할 수 있게 되었습니다.
MCP를 통해 Braze와 AI 에이전트를 연결하면, 아래와 같은 분석들이 가능해질 것으로 보입니다.
- 주요 지표들의 트렌드 시각화 요청 (DAU, MAU, 신규 유저 등)
- 캠페인 성과 분석
- 이벤트 간의 상관관계 분석

[Review] 브레이즈 부트캠프 | 개인화 CRM 캠페인 구성하기

지난 8월 28일, 개인화 태그 활용 사례와 Liquid 문법을 중심으로 직접 개인화 캠페인을 구현해볼 수 있는 브레이즈 부트캠프가 진행되었습니다. 개인화 태그를 활용하면, 고객 경험을 한 차원 업그레이드하고, 더 높은 성과를 만들 수 있습니다. Braze를 더 잘 활용하고, CRM 마케팅을 고도화 하고자 모인 많은 실무자 분들과 함께 한 생생한 현장을 만나보세요.
세션 1. 개인화 태그 및 Liquid 개요

마티니의 최영아 CRM Part Lead 진행으로 시작된 첫 번째 세션은, 개인화 태그에 대한 기본적인 개념과 함께 개인화 태그를 활용했을 때 어떤 메시지를 구성할 수 있는지를 중점적으로 다뤘습니다. 이론적인 내용은 물론, 실제로 개인화 태그로 어떤 캠페인을 구현할 수 있는지 사례를 중심으로 확인하며 개인화 태그에 대한 이해를 높일 수 있었습니다.
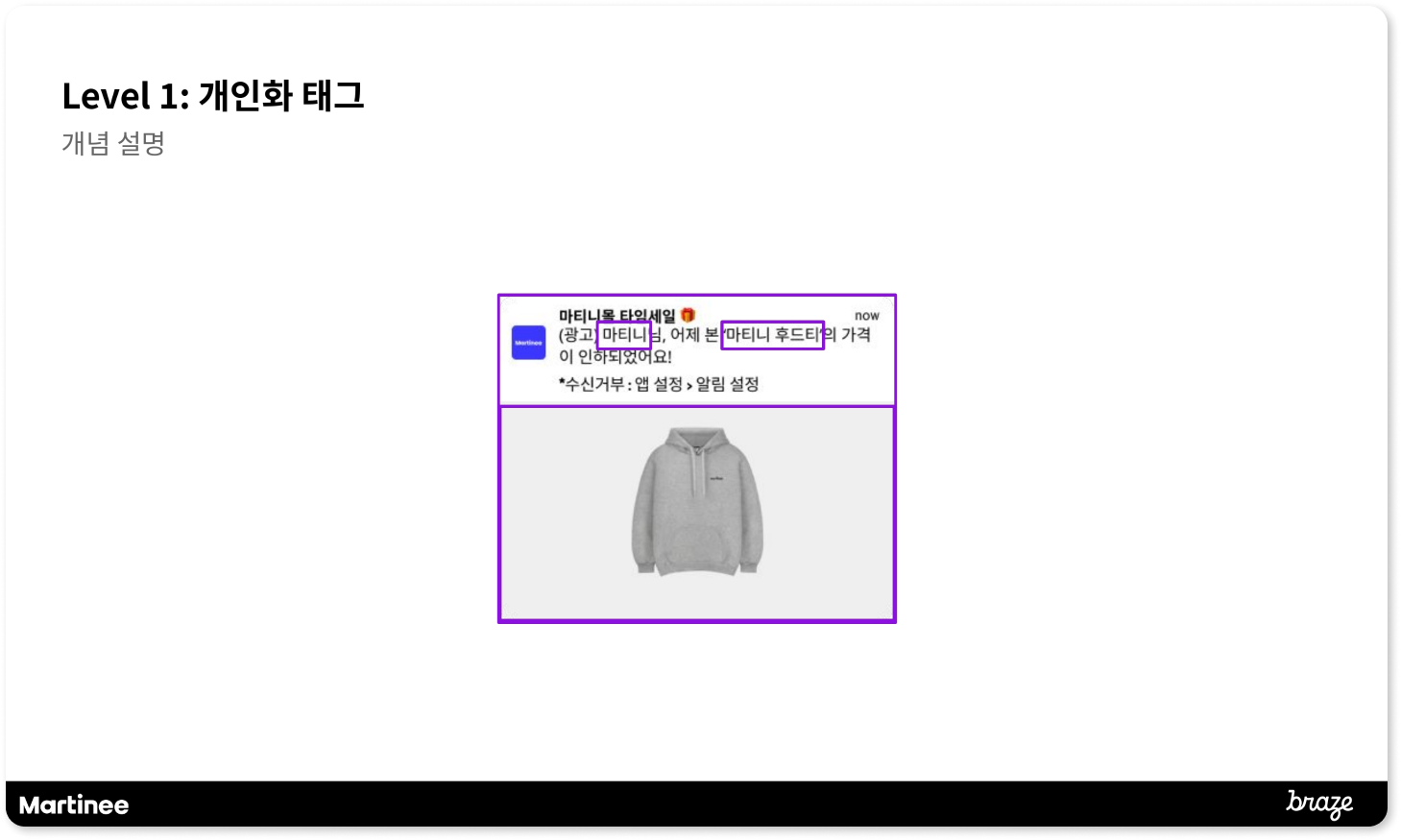
조회한 상품, 시간, 회원가입 일자 등 유저별로 다른 데이터를 저장하고 활용해 위와 같은 개인화 캠페인을 구현할 수 있습니다. 세션에서는 실제로 이와 같은 메시지가 어떤 과정으로 구성되는지 자세히 살펴보는 시간을 가졌습니다.
세션 2. Liquid 문법 설명 및 실습 문제 풀이

이어진 두 번째 세션에서는, 마티니의 CRM 팀을 이끌고 있는 이건희 COO 주도로 본격적으로 실습 문제를 풀어보는 시간을 가졌습니다. 다양하게 구성된 실습 문제를 통해 실제로 코드를 작성해 개인화 캠페인을 구현해볼 수 있었습니다.
문제 풀이에서 그치는 것이 아니라, 작성한 코드가 어떻게 구현되는지 눈으로 확인하면서 Liquid 문법에 대한 이해를 높였습니다. 여러 유형의 실습 문제를 통해 빠르게 Liquid 문법을 이해하고 익힐 수 있는 세션이었습니다.

늦은 시간임에도 적극적으로 임해주신 참여자 분들 덕분에 더 유익하고 알찬 시간을 보낼 수 있었습니다. 실무에서 실제로 활용하실 수 있는 많은 인사이트를 얻은 시간이 되셨기를 희망합니다.
브레이즈 부트캠프만의 특별한 혜택

적극적으로 참여해주신 실무자 분들을 위해, Braze Certification을 50% 할인된 가격으로 취득할 수 있는 프로모션 코드를 제공해드렸습니다. Braze Certification을 취득하면, 브레이즈 부트캠프에서 배운 내용을 점검해볼 수 있을뿐만 아니라, Braze 활용 역량을 공식적으로 인증받을 수 있습니다.
11월, 브레이즈 부트캠프가 돌아옵니다

오는 11월에는 CRM 캠페인 자동화, 성과 분석에 대해 알아볼 수 있는 세션을 준비하고 있습니다. 자동화 캠페인과 체계적인 성과 분석을 통해 CRM 마케팅 성과를 높이고 싶으시다면, 다가오는 11월을 기대해 주세요!
Braze Bootcamp - Personalization
주최 | Martinee ✕ Braze
일시 | 2025년 8월 27일 (수) 19시
장소 | 서초 마제스타시티 타워2 12F

CRM 마케팅에 개인화 엔진이 꼭 필요한 이유

현대의 소비자들은 관심 분야, 살고있는 지역, 사용하는 언어 등을 기반으로 개인화된 경험을 하는 데 익숙해져 있습니다. ‘안녕하세요, {이름} 님’에 그치는 수준의 개인화로는 더 이상 소비자들을 설득할 수 없습니다. 결국, 더 수준높은 개인화 경험을 제공하는 브랜드만이 경쟁에서 살아남을 수 있습니다.
브랜드가 진정으로 고객과 소통하고 장기적인 충성도를 높이기 위해서는 모든 채널에서 일관되게 개인화된 경험을 제공해야 합니다. 바로 여기서 ‘개인화 엔진(Personalization Engine)’이 필요합니다. 개인화 엔진은 실시간으로 고객 행동 데이터를 분석하고, 예측 하여 개인 수준에서 메시지와 경험을 커스터마이징합니다. 높은 목표를 가진 브랜드의 경우 이러한 확장 가능한 개인화는 전략적으로 필수적입니다.
이번 아티클에서 개인화 엔진이 무엇이고, 어떻게 작동하며 고객 참여를 이끌어 내는데 어떻게 도움이 되는지 자세히 알아보세요.
개인화 엔진은 무엇인가요?

개인화 엔진은 기업이 고객 데이터를 수집하고 분석하여 개인화된 고객 경험을 만드는 데 사용하는 소프트웨어입니다. 기업은 인공지능(AI)을 기반으로 한 개인화 기능이 내장된 고객 참여 플랫폼을 개인화 엔진으로 활용할 수 있습니다.
일반적으로 개인화 엔진은 구매 이력, 웹사이트 또는 앱 상호작용과 같은 행동 정보와 함께 인구 통계 데이터, 브랜드 충성도, 고객 서비스 또는 영업과 같은 다른 부서의 정보를 수집합니다. 개인화 엔진이 수집하는 데이터가 더 포괄적이고 고품질일수록 해당 데이터를 사용하여 개인화된 메시지를 더 정확하게 전달할 수 있습니다.
개인화 엔진의 작동 원리
개인화 엔진은 유저 행동 데이터를 지속적으로 수집하고 학습합니다. 개인화 엔진은 학습한 데이터를 바탕으로 다양한 정보를 제공합니다. 예를 들어, 특정 고객의 구매 시점을 예측한 정보를 바탕으로, 마케터가 적시에 구매를 유도하는 메시지를 보낼 수 있도록 돕습니다. 또는 고객이 언제 이탈할지 예측하여 고객이 이탈하지 않고 머물도록 유도하는 메시지를 보낼 수도 있습니다.
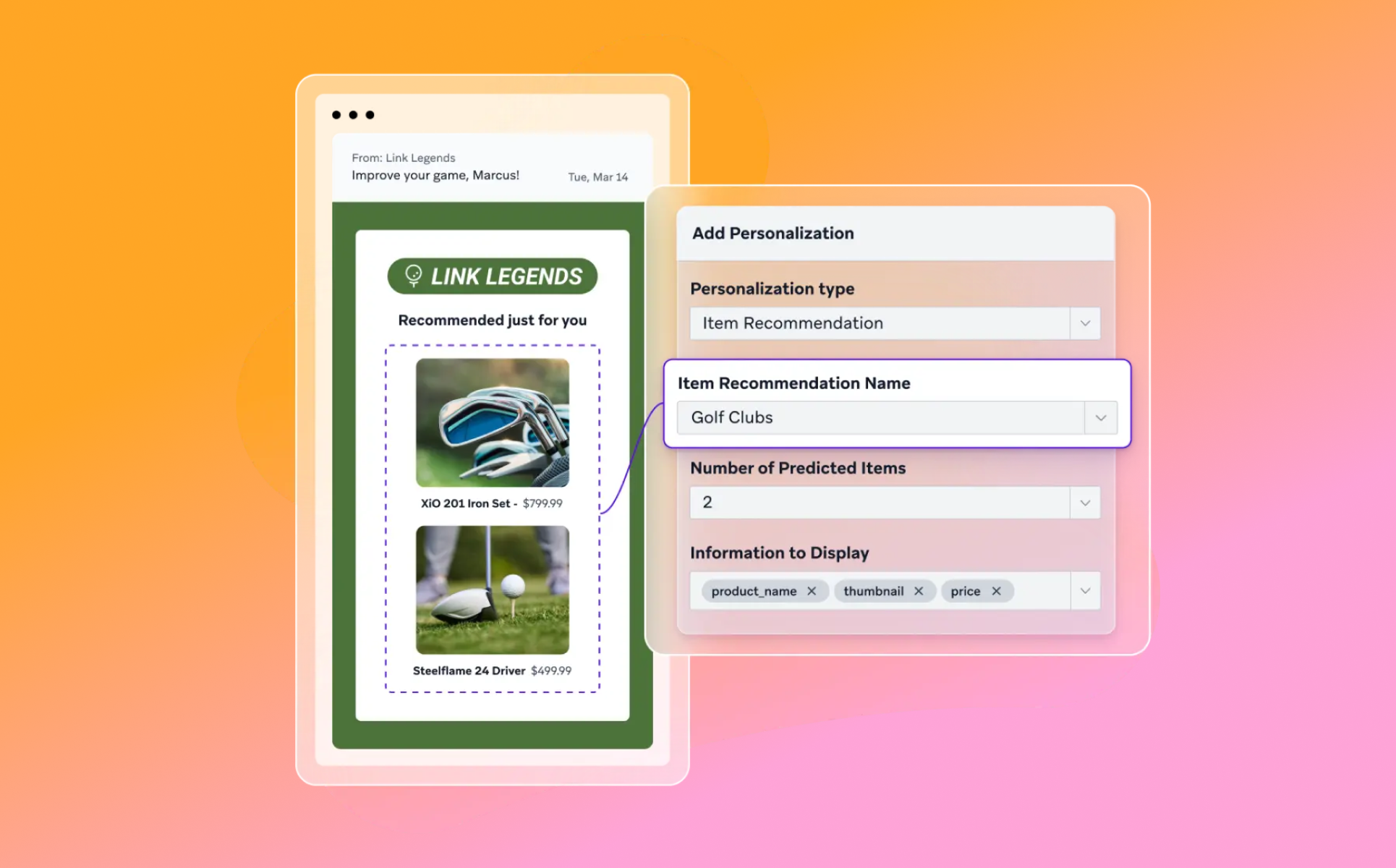
인공지능을 활용하면 개인화 엔진의 복잡한 프로세스를 자동화하여 대규모의 개인화가 가능합니다. 예를 들어, 브레이즈(Braze)의 AI 상품 추천은 인공지능을 사용하여 각 고객의 구매 이력과 개별 속성을 기반으로 한 맞춤형 제품을 추천합니다. 더불어 추천 내역은 캠페인에 통합되어, 브랜드가 각 고객에게 가장 관련성 높은 제품이나 콘텐츠를 제공할 수 있도록 도와줍니다.
마케터는 브레이즈 개인화 경로(Personalized Path)와 같은 기능을 통해 개별 고객이 참여할 가능성이 가장 높은 콘텐츠를 기반으로 메시지 콘텐츠, 크리에이티브, 채널 또는 오퍼를 간단한 토글로 자동으로 조정할 수 있습니다.
개인화 엔진의 8가지 장점
다음은 개인화 엔진을 사용했을 때의 주요 장점입니다.
1. AI 기반 추천을 통한 수익 극대화
고객이 구매할 확률이 높은 제품을 적극적으로 추천해, 수익을 극대화해보세요.
2. 수준 높은 브랜드 경험
이메일, 문자 메시지와 같은 비즈니스 플랫폼부터 인앱 메시지(IAM), 푸시(Push) 알림 등 플랫폼 간 유기적인 연결을 통해 메시지의 도달 가능성을 높이는 것은 중요합니다. 하지만 여러 채널로 메시지를 보내는 것보다 얼마나 관련있는 메시지를 제공하는지가 훨씬 중요합니다. 위치 기반 푸시 알림이나 관심사 기반 인앱 메시지가 적절한 시점에 제공될 때 더 강력한 감정적 연결을 형성하고 더 나은 성과를 만들 수 있습니다.
3. 기술과 통합된 추천 제공
개인화 엔진은 적절한 개인화 도구와 함께 활용되어 고객 데이터를 수집, 분석할 뿐만 아니라 지속적으로 성과를 추적합니다. 즉, 특정 데이터가 필요한 시점에 해당 데이터가 최신 상태로 유지되고 있으므로 의사결정을 내리고 계획을 조정하는 것이 훨씬 쉬워집니다. 최신 데이터를 기반으로 캠페인을 구성하면서, 더 관련성이 높은 메시지를 구성할 수 있습니다. 더불어 이 모든 과정을 빠르고 효율적으로 구현할 수 있습니다.
4. 팀 간 데이터 통합으로 성과 향상
마케팅 조직의 주요한 불만 중 하나는 각 팀이 각기 다른 데이터와 목표를 기반으로 일하고 있다는 점입니다. 개인화 엔진은 모든 데이터를 고객 참여 플랫폼에 통합해 다양한 캠페인을 위해 활용할 수 있도록 합니다. 이를 통해 보다 각 팀의 프로세스를 일원화하고, 이는 곧 고객의 일관된 경험으로 이어집니다.
AI와 자동화를 통해 수작업으로 하던 과정을 대규모로 한 번에 처리할 수 있습니다. 실시간 데이터를 빠르게 처리하는 이 기능은 개인화 엔진이 가진 가장 큰 장점 중 하나입니다.
5. 맞춤형 메시지를 통한 수익 창출

개인화를 활용하면 구매를 유도할 수 있는 맞춤형 메시지를 구성할 수 있습니다. 위와 같이, 고객이 확인한 상품, 고객의 이름, 고객이 가지고 있는 쿠폰 등의 정보를 활용해 맞춤형 메시지를 구성해 보세요.
6. 더 매력적인 고객 경험 창출
고객이 스스로 이해했다고 느낄 때, 더 오래 머물 가능성이 높아집니다. 개인화 엔진은 브랜드가 각 사용자에게 적합한 직관적인 고객 여정을 만들 수 있도록 돕습니다. 검색, 구매, 기기 간 상호작용 등 모든 고객 여정에서 관련성 높은 콘텐츠를 제공합니다.
7. 고객 여정 최적화를 통한 전환 극대화
자동화를 통해 고객 여정의 주요한 순간에 개인화 경험을 고도화할 수 있습니다. 개인화 엔진과 통합 도구를 활용해 보세요. 예를 들어, 브레이즈의 개인화 경로를 사용하면 마케터는 고객의 참여를 유도할 수 있는 메시지, 크리에이티브와 채널을 결정할 수 있습니다.
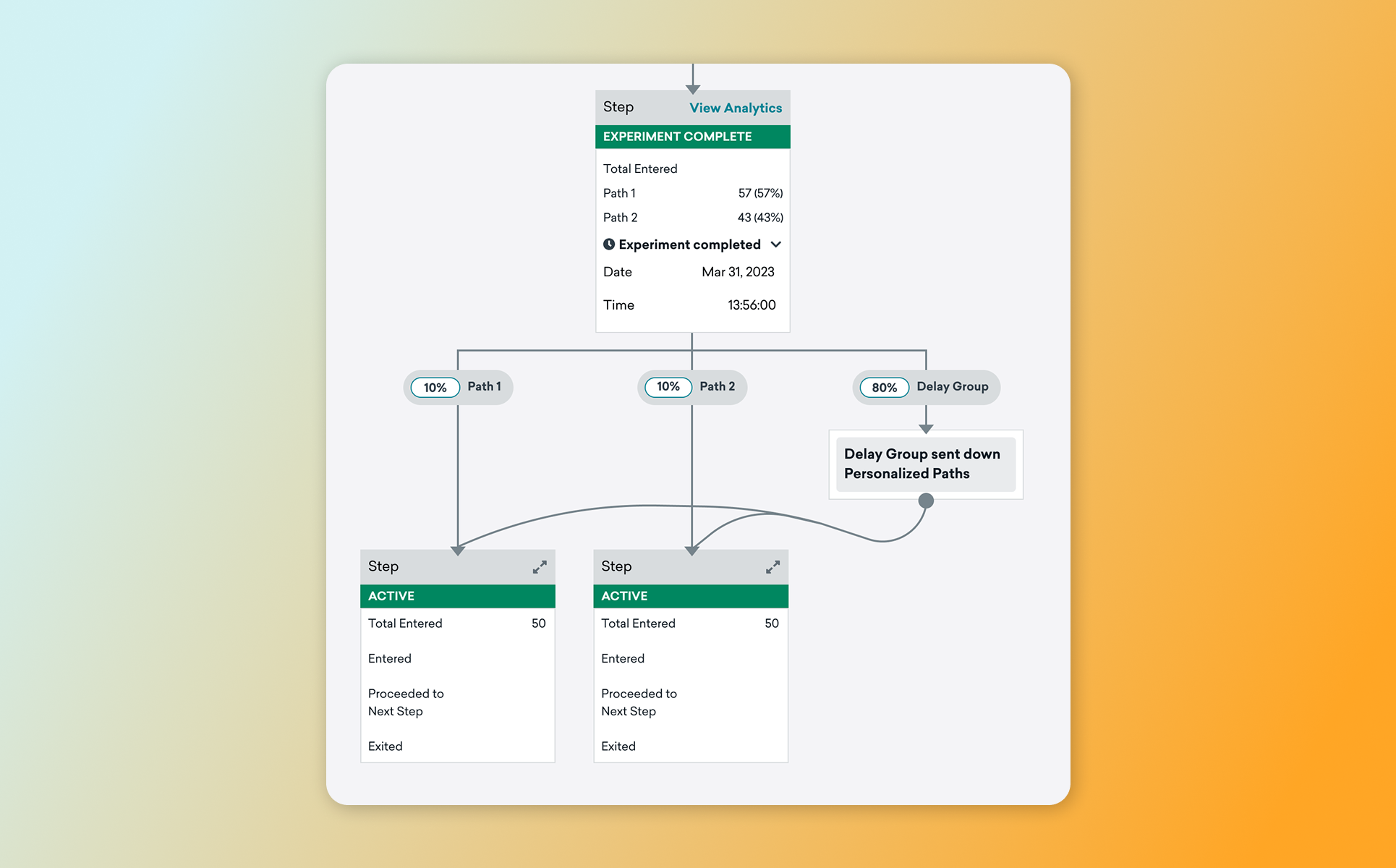
코드를 작성할 필요 없이, 캔버스(Canvas)를 활용하여 높은 반응을 이끌어낼 수 있는 역동적인 고객 여정을 구성해 보세요.
8. 예측 기반 참여 유도
마케터는 ‘예측’을 통해 적절한 시점에 행동을 취하고 결과를 더 유리한 방향으로 전환할 수 있습니다. 브레이즈의 Predictive Suite를 사용하면, 브랜드는 이탈 위험이 있는 사용자 또는 핵심 행동을 취할 가능성이 가장 높은 사용자를 자동으로 식별하여 참여를 유도할 수 있습니다.
지금 바로 개인화 엔진을 활용해 보세요
개인화 엔진은 데이터를 더 많이 활용하고, 더 고도화된 전략을 사용하고, 더 효율적으로 일할 수 있도록 돕습니다. 예측 기반의 추천부터, 동적 콘텐츠와 AI 기반 고객 여정 오케스트레이션(Orchestration)까지. 속도나 규모에 구애받지 않고 아이디어를 실행할 수 있습니다.
이러한 개인화 엔진이 브레이즈와 같은 고객 참여 플랫폼에 내장되면, 모든 채널과 고객 여정 전반에서 더 효율적인 개인화가 가능합니다. 이는 고객이 브랜드와 상호작용하는 모든 순간을 연결하는 경험을 창출하는 일입니다. 지금 바로 개인화 엔진과 브레이즈를 활용해 개인화된 고객 경험을 설계해 보세요.

아하 모먼트: 유저 경험 혁신하기

고객 여정에는 ‘아하 모먼트(Aha Moment)’라는 중요한 순간이 있습니다. 유저가 프로덕트의 핵심 가치를 이해하는 순간입니다.
아하 모먼트를 찾고, 디자인하는 것이 중요한 이유는 아하 모먼트를 통해 목표에 도달하는 데 프로덕트가 어떻게 도움이 되는지 보여주고, 결과적으로 유저가 이탈할 확률을 줄여주기 때문입니다. 아하 모먼트를 파악하기 위해서는 기능 이해, 온보딩 완료와 같은 기본적인 유저 행동을 확인해야 합니다.
이번 아티클에서 더 많은 유저를 장기 고객으로 전환할 수 있는 아하 모먼트란 무엇인지, 그리고 어떻게 아하 모먼트를 찾고, 아하 모먼트로 유저를 유도할 수 있는지 알아보세요.
아하 모먼트란 무엇일까요?
아하 모먼트는 유저가 프로덕트의 핵심 가치를 파악하고 내면화하는 순간입니다. 활성화(Activation) 모먼트, 유레카 모먼트, 깨달음의 순간(Lightbulb moment)이라고도 합니다. 아하 모먼트는 단일 순간일 수도 있고, 사용자가 프로덕트의 가치를 진정으로 파악할 수 있을만큼 충분히 사용한 시점일 수도 있습니다. 이 갑작스러운 순간은 유저를 활성화시키는 데 아주 중요하며, 일반적으로 유저가 프로덕트에 투자하기로 한 의사결정과 일치합니다.

션 엘리스(Sean Ellis)는 그의 저서 ‘진화된 마케팅 그로스 해킹’에서 아하 모먼트를 ‘유저에게 프로덕트의 유용성이 인식되는 순간, 유저가 핵심 가치를 진정으로 얻을 때’라고 정의합니다. 여기서 핵심 가치란, ‘프로덕트가 무엇을 위한 것인지, 왜 필요한지, 그리고 그것을 사용함으로써 얻을 수 있는 이익은 무엇인지’에 대한 개념입니다.
프로덕트의 아하 모먼트를 발견하는 방법
프로덕트의 아하 모먼트는 만드는 것이 아니라 사용자가 느끼는 것입니다. 아하 모먼트를 만들 수는 없지만 '프로덕트에서 아하 모먼트가 발생할 수 있는 조건'을 만들 수는 있습니다. 프로덕트 팀은 아하 모먼트를 이해하고 더 많은 유저가 아하 모먼트에 도달할 수 있도록 안내해야 합니다.
프로덕트의 아하 모먼트를 알 수 있는 몇 가지 방법을 소개합니다.
1. 유저 세그먼트 만들기
유저들은 모두 같은 특성을 갖고 있지 않습니다. 유저는 각자 가지고 있는 니즈와 해결하고자 하는 문제가 다르기 때문에 서로 다른 아하 모먼트를 경험할 수 있습니다. 이러한 아하 모먼트를 알아내려면 유저가 프로덕트를 사용하는 방법과 이유에 따라 서로 다른 페르소나를 파악하고, 그룹화해야 합니다.
몇몇 기업의 경우 유저 세그먼트를 지역과 연령대로 분류합니다. 다른 기업은 유저 역할(엔지니어 vs 디자이너, PM vs 디자이너 등)을 중심으로 세그먼트를 분류하기도 합니다. 유저 세그먼트에 대한 정의를 내리면 각 세그먼트의 라이프사이클을 보다 정확하게 분석할 수 있습니다.
위 질문에 대한 답변은 유저가 프로덕트의 가치를 빠르게 파악하고, 아하 모먼트가 발생하도록 유저를 가이드하는 데 도움을 줄 수 있습니다.
2. 고객 여정 분석하기
아하 모먼트를 이해하고 최적화하려면 고객 여정 전체를 파악해야 합니다. 앰플리튜드의 ‘세션 리플레이’ 기능은 유저 세션 리플레이(Session Replay)와, 실시간 분석을 결합하여 보여주기 때문에 고객 여정을 쉽게 파악할 수 있습니다.
세션 리플레이를 통해 유저의 ‘돌파구’와 같은 순간을 시각적으로 확인해 보세요. 유저가 인터페이스를 어떻게 탐색하고, 어떤 기능을 주로 사용하며, 어느 시점에 프로덕트에 대한 이해가 높아지는지 관찰할 수 있습니다. 유저 행동을 분석해 아하 모먼트가 발생하는 정확한 지점을 파악하세요. 여기서 유저 경험을 세분화하면 더 많은 유저를 아하 모먼트로 안내할 수 있습니다.
3. 유저 피드백 받기
유저 피드백을 사용하여 프로덕트의 아하 모먼트를 발견할 수도 있습니다. 유저의 공감을 불러일으키는 기능을 이해하여 프로덕트 경험을 개선하고, 더 많은 유저에게 이 기능을 안내할 수 있습니다.
4. 리텐션 데이터 활용하기
분석 도구를 활용해 전환율, 유저 리텐션과 같은 프로덕트 지표를 분석해 보세요. 특정 기능이 선택된 이유, 특정 조건이 적용되는 위치를 통해 리텐션 데이터를 시각화할 수 있습니다. 예를 들어 소셜미디어 앱에서 고객 행동을 분석하면, 처음 며칠 이내에 특정 수의 유저와 연결되는 것이 장기적인 리텐션으로 이어지는 것과 밀접한 관련이 있음을 알 수 있습니다.
프로덕트와 유저에 대한 깊이있는 분석으로 아하 모먼트에 대한 중요한 인사이트를 얻을 수 있습니다. 그러나 ‘선택 편향’을 주의해야 합니다. 예를 들어, 특정 온보딩 플로우를 완료한 유저에게만 초점을 맞추면 그들의 리텐션을 해당 플로우에 대한 기여로만 측정하는 오류를 범할 수 있습니다. 해당 플로우를 건너뛴 유저의 아하 모먼트는 완전히 다를 수 있습니다. 따라서 분석을 할 때에는 다양한 액션과 고객 여정을 포함하여 더 많은 유저에게 리텐션을 유도할 수 있는 아하 모먼트를 정확하게 판단해야 합니다.
아하 모먼트 디자인하기

아하 모먼트를 정의했다면, 프로덕트에서 유저가 아하 모먼트를 효과적으로 경험하도록 안내해 보세요.
1. 가벼운 개입으로 사용자 안내하기
유저를 아하 모먼트로 안내하는 것도 중요하지만 강압적인 전략은 역효과를 낼 수 있습니다. 유저는 정해진 경로대로 따라가는 것을 꺼려하고, 자신의 속도에 맞춰 프로덕트의 가치를 발견하고 싶어하는 경향이 있습니다.
방해가 되는 모달과 툴팁으로 유저 여정을 방해하기보다 직관적인 유저 여정을 설계해 보세요. 잘 설계된 도시에는 명확한 표지판, 유용한 랜드마크, 탐험의 자유를 제공하면서도 목적지까지 쉽게 이동할 수 있는 길이 있습니다.
이와 마찬가지로 프로덕트는 유저가 자연스럽게 아하 모먼트를 경험할 수 있도록 주요 액션과 기능을 부드럽게 연결해야 합니다.
2. 제품 가치를 발견하는 명확한 경로 설계하기

유저를 아하 모먼트로 안내하는 것은 단순히 기능을 보여주는 것이 아닙니다. 새로운 유저가 프로덕트의 핵심 가치를 경험할 수 있도록 명확한 경로를 설계해야 합니다. 이해와 참여를 유도하는 주요 액션과 상호 작용에 우선순위를 두는 ‘유저 저니 맵(User Journey Map)’을 만든다고 생각해 보세요.
사용자를 자연스럽게 안내하는 직관적인 워크플로우를 구축해 보세요. 예를 들어 파일 공유 앱의 아하 모먼트가 ‘어디서든 파일에 액세스 할 수 있다는 것을 인식하는 순간’이라면, 온보딩 플로우를 통해 유저가 다른 장치에서 파일을 업로드하고 액세스할 수 있도록 즉시 유도할 수 있습니다.
3. 적절한 시점에 적절한 곳으로 유도하기
프로덕트에 세 가지 일반적인 아하 모먼트가 있다고 가정했을 때, 이 세 가지 순간을 모두 경험하게 하는 것은 어려운 일입니다. 유저가 모든 아하 모먼트에 도달하도록 하는 대신 유저의 의도에 집중해 보세요. 유저가 두 번째 아하 모먼트로 나아가고 있는 것을 발견했다면 그 순간으로 이동시키는 데 집중해야 합니다.
유저의 반응이 예상되는 시점이 있다면 해당 시점에 유저를 안내해야 합니다. 유저가 몇 가지 모달이나 툴팁이 표시되자마자 닫거나 삭제한 경우, 시간차를 두고 다른 내용을 보여주는 것이 효과적입니다.
4. 다양한 가치 지점을 설계하기
성공적인 프로덕트는 여러 경험을 통해 유저에게 가치를 제공합니다. 단 하나의 아하 모먼트에만 의존하는 것이 아니라, 유저에게 가치를 제공할 수 있는 다양한 방법을 생각해 보세요.
핵심 가치를 제안하는 주요 아하 모먼트와 유저 참여를 지속할 수 있는 보조 아하 모먼트를 설계하세요. 이를 통해 프로덕트 내에서 여러 경로를 만들어 유저가 프로덕트의 잠재력을 최대한으로 경험할 수 있습니다.
5. 유저의 불확실성을 최소화하기
세션 리플레이를 충분히 살펴보면, 프로덕트 내에서 정처 없이 떠돌아 다니는 유저를 발견할 수 있습니다. 유저가 이 지점에 도달하기 전에, 온보딩을 완료하도록 유도해야 합니다. 때로는 유저가 스스로 해낼 수 있도록 도와야 할 때도 있습니다.
아하 모먼트와 혼동되는 개념
‘아하 모먼트’라는 용어는 고객 여정의 다른 성과 지표와 혼동되기도 합니다. 예를 들어, 유저의 원활한 온보딩 경험은 중요하지만 아하 모먼트라고 볼 수는 없습니다. 아하 모먼트는 유저가 프로덕트의 핵심 가치를 처음으로 이해하는 순간입니다. 온보딩 프로세스는 아하 모먼트로 유저를 안내하는 역할이라고 할 수 있습니다.
마찬가지로 단순히 프로덕트 사용 방법을 이해하는 것만으로는 아하 모먼트라고 볼 수 없습니다. 예를 들어 디자인 툴에서 디자인 기능을 이해하는 것은 꼭 필요한 과정이지만, 유저의 아하 모먼트는 툴을 활용해 팀원들과 실시간 협업의 힘을 경험하는 순간일 수 있습니다. 툴팁이나 단계별 온보딩 같은 인앱 가이드도 프로덕트의 가치를 전달하는 데 도움이 될 수는 있습니다. 그러나 아하 모먼트는 이러한 팁의 전달이 아니라 팁을 따를 때 유저가 프로덕트가 왜 필요한지 이해하게 되는 순간입니다.
앰플리튜드로 유저의 아하 모먼트 이해하기
유저 여정을 분석하여 프로덕트의 아하 모먼트를 정확히 파악해 보세요. 앰플리튜드의 분석 기능은 사용자 경로를 시각화하고, 참여를 유도할 수 있는 주요 기능을 식별하는 데 도움이 됩니다. 퍼널 분석을 사용하여 사용자 이탈 지점을 확인하거나, 여정 분석을 통해 일반적인 액션을 파악할 수 있습니다. 이러한 인사이트를 사용자 리서치와 결합하면 사용자 여정을 최적화하고 더 많은 사용자가 아하 모먼트를 경험하도록 안내할 수 있습니다.

[종료] 브레이즈 부트캠프 | 개인화 CRM 캠페인 구성하기
.png)
.png)
.png)
Braze Bootcamp 신청 바로가기
🔗 이벤터스 신청 페이지 | https://event-us.kr/martinee/event/109928
안내사항
- 신청 시 기입한 이메일이 회사 계정이 아닌 경우 선정이 불가합니다.
- 참가 인원이 한정되어 있어 별도로 참석 확정 연락을 드릴 예정입니다.
- 브레이즈 실습 과정이 포함된 교육으로 개인 노트북 지참이 필요합니다.
- 주차권 제공 가능합니다.
- 다시 보기 및 강의 자료가 별도 제공되지 않습니다.
강의 취소 및 환불 규정
1. 취소/환불 규정
- 강의 당일 기준 1일 전까지 취소/환불 신청 시 100% 취소/환불이 가능합니다.
- 구매자가 단순 변심 등의 본인의 사정으로 인해 환불을 신청할 경우에도 강의 1일 전까지 취소/환불이 가능합니다.
- 강의 당일(0시 기준)에는 취소/환불이 불가능합니다.
- 패키지의 경우 구매자가 이후 강의를 수강하지 아니하여도 결제 PG사 환불 규정에 따라 부분 및 일부 금액 환불 불가능합니다.
2. 취소/환불 수수료
- 결제 수단에 따라 환불 수수료가 부과될 수 있습니다.
- 취소/환불 수수료는 결제수단에 따라 다르게 적용 및 공제됩니다.
- 결제 수단, 환불 신청 시점에 따라 환불 방식은 결제 취소 또는 환불 신청으로 다를 수 있습니다.
- 취소/환불 수수료는 결제 수단에 따라 다르게 적용 및 공제됩니다.
- 취소/환불 수수료 공제에 대한 세금계산서 또는 현금영수증을 희망하는 경우 고객센터로 문의 바랍니다.
3. 취소/환불 방식
- 신용카드 환불의 경우 결제 PG사에서의 환불 처리가 완료되고 카드사를 통해 결제 승인이 취소되면 환불이 완료됩니다.
- 결제 당일 이후 결제 취소 시 카드사를 통한 결제 승인 취소 확인은 3~7일 가량 소요될 수 있으며, 이는 카드사마다 다를 수 있습니다.
- (시행일) 본 약관은 2024년 3월 26일부터 시행됩니다.
Contact
마티니와 함께 효과적인 CRM 마케팅을 시작해 보세요!

[Review] The MAXONOMY 2025 (더 맥소노미 2025)

지난 6월 26일, CX:CODE – 고객 경험 설계의 모든 것을 주제로 열린 The Maxonomy 2025가 성황리에 마무리되었습니다. 데이터, 마케팅, 테크 세 가지 트랙에서 총 24개의 세션을 통해 업계 전문가들의 인사이트가 깊이 있게 공유된 자리였습니다. 이번 컨퍼런스에서 마티니는 고객 여정 전반을 데이터로 연결하여 실제 성과로 이어낸 풀퍼널 마케팅 전략을 제시했습니다.
Martinee | The MAXONOMY 2025


마티니 그로스 그룹장 이재철님은 <버킷스토어가 찾은 성장공식 : CRM X 퍼포먼스 조합하기> 세션을 통해 골프웨어 브랜드 '버킷스토어'와 함께한 마티니의 풀퍼널 마케팅 사례를 공유했습니다.
버킷스토어는 연 매출 3,000억 원 규모의 크리스에프엔씨가 운영하는 온라인 자사 플랫폼으로 파리게이츠, 핑, 팬텀 등 다수의 브랜드를 보유한 골프 & 스포츠웨어 전문몰입니다.
버킷스토어는 코로나로 인한 골프 시장 축소와 함께 주요 브랜드의 매출 성장 정체라는 과제에 직면해 있었습니다. 마티니는 이러한 상황을 개선하고, 자사몰을 성장시키기 위해 다음과 같은 4단계 데이터 드리븐 마케팅 전략을 수립했습니다.
1️⃣ MMP & CRM & PA 솔루션을 연계한 데이터 분석 환경 구축
2️⃣ 멀티 채널, 코호트, RFM 중심 고객과 서비스에 대한 심층 분석
3️⃣ 데이터 기반의 광고 운영
4️⃣ 개인화 타겟팅, 멤버십 재설계 등 CRM 마케팅 고도화


가장 먼저, 정밀한 분석과 실행 환경 구축을 위해 Amplitude와 Braze를 도입했습니다.
마티니는 Taxonomy 설계부터 개발 QA까지 솔루션 도입의 전 과정을 지원하며, 고도화된 마케팅 기반을 마련했습니다. 또한 MMP와 광고 채널 데이터를 연동해 광고 성과를 자동으로 집계·리포팅할 수 있는 체계를 만들었습니다.
Braze 도입 이후에는 채널별 타겟 실험, CRM 자동화, 정교한 개인화 마케팅이 가능해졌으며, Amplitude를 통해 선·후 데이터 분석과 실험을 빠르게 수행할 수 있게 되었습니다. 이처럼 하나로 통합된 데이터 환경 위에서 주요 지표를 정의해 대시보드를 제작하고, 심층적인 고객∙서비스 분석을 진행했습니다.
마티니는 6개월 간 진행된 80개의 퍼포먼스 실험과 90개의 CRM 테스트를 바탕으로 퍼포먼스와 CRM을 유기적으로 연결해, 버킷스토어 자사몰의 실제 증분 매출로 이어지는 결과를 만들었습니다.


고객 여정은 더이상 단절된 채널과 조직으로 설명되지 않습니다.
데이터를 중심으로 통합된 구조 안에서 실행하는 접근이 필요합니다.
정확한 데이터 X 통합적 분석 X 빠른 실행,
끊임없는 데이터 기반 의사결정으로 비즈니스 성과를 만드는 마티니가 궁금하다면 아래 링크를 참고해 보세요.
👤 마티니 세일즈팀 만나보기 https://tally.so/r/wzWXG0
🌐 마티니 홈페이지 바로가기 https://www.martinee.io/

[종료] 그로스 캠프 5기 OPEN

그로스 캠프 5기 신청 바로가기
🔗이벤터스 링크 : https://event-us.kr/m/105058/36388
안내사항
- 참가 인원이 한정되어 있어 별도 참석 확정 연락을 드릴 예정입니다.
- 실습이 포함된 교육으로 개인 노트북 지참이 필요합니다.
- 주차권 제공 가능하며 리셉션 데스크로 문의 부탁드립니다.
- 참석자분들에게 간단한 음식이 제공될 예정입니다.
강의 취소/환불 규정
1. 취소/환불 규정
강의 당일 기준 1일 전까지 취소/환불 신청 시 100% 취소/환불이 가능합니다.
구매자가 단순 변심 등 본인의 사정으로 인해 환불을 신청할 경우에도 강의 1일 전까지 취소/환불이 가능합니다.
강의 당일(0시 기준)에는 취소/환불이 불가능합니다.
패키지의 경우 구매자가 이후 강의를 수강하지 아니하여도 결제 PG사 환불 규정에 따라 부분 및 일부 금액 환불이 불가능합니다.
2. 취소/환불 수수료
결제수단에 따라 환불 수수료가 부과될 수 있습니다.
취소/환불 수수료는 결제수단에 따라 다르게 적용 및 공제됩니다.
결제수단, 환불 신청 시점에 따라 환불 방식은 결제취소 또는 환불신청으로 다를 수 있습니다.
취소/환불 수수료는 결제수단에 따라 다르게 적용 및 공제됩니다.
취소/환불 수수료 공제에 대한 세금계산서 또는 현금영수증을 희망하는 경우 고객센터로 문의 바랍니다.
3. 취소/환불 방식
신용카드 환불의 경우 결제 PG사에서의 환불 처리가 완료되고 카드사를 통해 결제 승인이 취소되면 환불이 완료됩니다.
결제 당일 이후 결제 취소 시 카드사를 통한 결제 승인 취소 확인은 3~7일 가량 소요될 수 있으며, 이는 카드사 마다 다를 수 있습니다.
(시행일) 본 약관은 2024년 03월 26일 부터 시행됩니다.
Contact
마티니와 함께 데이터 분석 기반의 그로스 마케팅을 경험해보세요!

[Review] DMS 2025 (디지털 마케팅 서밋 2025)
올해로 10주년을 맞은 디지털 마케팅 서밋 2025 (Digital Marketing Summit, 이하 DMS) 에서 ‘마티니’가 프리미엄 식품 커머스 플랫폼 ‘컬리’와 유아동 오디오 콘텐츠 플랫폼 ‘코코지’와 함께 [커넥티드 시대의 성장방식: 충성 고객 전략]을 주제로 세션을 진행했습니다.
Martinee | DMS 2025


마케팅 산업의 미래를 조망하고, 최신 트렌드와 인사이트를 공유하는 글로벌 지식 포럼 DMS(Digital Marketing Summit) 가 성황리에 마무리되었습니다.
4월 10일부터 11일까지 이틀간 서울 코엑스 그랜드볼룸에서 열린 이번 행사에서는 AI 기반 혁신, 브랜드 전략, 고객 경험 등 마케팅 트렌드의 핵심 주제를 중심으로 다양한 세션과 워크숍이 펼쳐졌고, 국내외 마케팅 리더들이 연사로 참여해 깊이 있는 인사이트를 전했습니다.
마티니도 이번 DMS에 연사로 참여해 컬리와 코코지와 함께 세션을 진행하며 충성 고객 마케팅을 성공한 사례를 공유했습니다.

디지털 혁신이 가속화되고 고객의 선택지가 점점 더 다변화되는 지금, 브랜드에게 ‘한 번의 구매’보다 더 중요한 건 지속적인 관계를 만들어가는 일입니다.
단순한 구매자를 ‘충성 고객’으로 전환시키고, 그들과의 장기적인 관계를 통해 브랜드의 성장을 이어나가는 것. 이것이 오늘날 마케팅에서 가장 중요한 전략 중 하나로 떠오르고 있습니다.
충성 고객이 중요한 이유: 관계가 곧 자산이 되는 시대

DMS 2025에서 마티니와 함께한 컬리의 오유미 그룹장, 코코지의 채송이 CCO는 충성 고객 확보가 단순한 마케팅 활동이 아니라, 비즈니스의 지속가능성과 직결된 전략적 자산임을 강조했습니다.
많은 브랜드가 리텐션, 재구매, 고객 생애가치(LTV) 향상에 집중하고 있지만, 단순히 반복 구매를 유도하는 것만으로는 충성도 있는 브랜드 관계를 만들 수 없습니다. 브랜드가 어떤 고객과 연결되어 있고, 어떤 방식으로 그 관계를 유지하고 있는지에 따라 장기적인 성과가 결정됩니다.
충성 고객 전략의 4가지 핵심

1️⃣ 데이터 기반 고객 인사이트
고객을 제대로 이해하는 것에서 모든 전략은 시작됩니다.
단순히 고객이 무엇을 구매했는지 파악하는 것을 넘어, 그들의 행동 패턴과 구매 여정 전반을 분석하고 해석해야 합니다.
이를 통해 고객을 다양한 특성별로 세분화하고, 맞춤형 멤버십 및 리워드 전략으로 확장할 수 있는 기회를 만들 수 있습니다.
2️⃣ 개인화된 경험 제공
고객은 브랜드로부터 자신만을 위한 메시지를 기대합니다. 그렇기 때문에 이전과 다른 CRM 전략이 필요합니다.
경험을 개인화하는 것은 단지 이름을 부르는 것에 그치지 않습니다.
정확한 데이터 기반으로 타이밍, 채널, 메시지를 조합하여 고객의 상황에 딱 맞는 경험을 전달해야 합니다.
3️⃣ 차별화된 멤버십 모델
단순한 가격 할인 중심이 아닌 라이프스타일 맞춤형 유료 멤버십 모델을 설계하는 전략은 충성 고객 확보에 매우 효과적입니다.
고객이 ‘오직 이 브랜드에서만 누릴 수 있는 경험’을 선택하도록 만드는 차별화된 멤버십은, 진정성 있는 경험을 통해 깊은 브랜드 로열티를 구축하는 핵심적인 역할을 합니다.
4️⃣ 전략적 리워드 프로그램
고객이 반복적으로 브랜드와 상호작용하게 만드는 구조가 필요합니다.
이를 위해 단순 리워드에서 나아가 정교하게 설계된 리텐션 유도 프로그램이 중요합니다.
일회성 혜택이 아닌, 행동 기반으로 구성된 리워드 전략은 브랜드와 고객 간의 연결을 루틴으로 만드는 데 기여합니다.
브랜드별 충성 고객 전략, 어떻게 다를까?

📊 마티니 – 충성 고객 전략의 출발점: 고객을 제대로 이해하는 것
CRM 캠페인, 광고 성과, 브랜드 상품 분석.
모든 마케팅 활동의 핵심은 결국 고객을 얼마나 깊이 이해하고 있는가에 달려 있습니다.
마티니는 고객 분석의 기초이자 가장 강력한 방법으로 RFM 분석을 강조합니다.
RFM은 고객의 구매 행동을 세 가지 기준으로 모델링하여 고객을 세분화하는 분석 기법입니다.
- 최근 구매 시점(Recency)
- 구매 빈도수(Frequency)
- 총 구매 금액(Monetization)
이렇게 분류된 고객 그룹에 맞춰 맞춤형 혜택을 설계하고, 캠페인 전략에 차별화를 더하면 재방문을 유도하고 CRM 메시지 피로도를 효과적으로 관리할 수 있습니다.
또한, 고객의 구매 특성을 바탕으로 멤버십 프로그램을 설계하고,이를 통해 충성 고객 전략 매트릭스를 구체화함으로써 브랜드와 고객 간의 연결을 더욱 단단하게 만들 수 있습니다.
*RFM 분석에 대해 더 알고 싶다면 이 글을 참고해 보세요👉 [프로젝트 후기] 멤버십 및 RFM 분석

🛒 컬리 – 상품력 중심의 고객 충성도 강화
컬리는 프리미엄 식품이라는 카테고리 강점을 살려, 유료 구독 기반의 선택형 멤버십 프로그램을 설계했습니다.
고객이 직접 자신에게 맞는 혜택을 선택함으로써 경쟁사 대비 명확한 차별성과 개인화된 만족을 전달하고 있습니다.

🎧 코코지 – 감성 연결을 루틴으로 만드는 브랜드 전략
코코지는 아이들과 ‘정서적 연결’에 집중합니다.
아이들의 하루를 세계관 기반의 스토리텔링으로 풀어내, 일상의 모든 순간을 브랜드 경험으로 전환합니다.
이를 통해 브랜드가 고객과 깊은 감성적 연결을 맺고 일상 속 루틴으로 자리잡을 수 있도록 돕습니다.

고객 충성도는 하루아침에 만들어지지 않습니다. 데이터 기반의 깊은 이해, 정교한 전략, 그리고 고객의 삶과 감정에 스며드는 경험이 쌓여야 비로소 브랜드는 고객과 관계를 맺을 수 있습니다.
마티니는 이렇게 돕고 있습니다
마티니는 CRM, 퍼포먼스, 그로스, 광고기획 등 풀퍼널 마케팅 조직으로 구성되어 있으며, 데이터 기반 전략 수립부터 실제 캠페인 운영까지 성장 중심의 마케팅 실무를 제공합니다.
지금 여러분의 브랜드는 충성 고객과 어떤 관계를 맺고 있나요?
마티니와 함께 고객과 지속적으로 연결되는 마케팅을 만들어보세요. ➡️ 고객 중심 전략 설계하기
.png)
[Review] 원시그널 Surge Seoul 2025
[Martinee X OneSignal]
4월 15일(화), 앙트레블 강남에서 열린 OneSignal Surge Seoul 2025 에 마티니가 다녀왔습니다! 👏👏
.png)

행사 시작 전 원시그널에서 오신 분들과 함께 CRM 현황과 마티니가 하는 업무에 대해서 짧게 이야기를 나누었습니다.
마티니가 무슨 일을 하는 지 궁금하시다면 👉 여기서 확인해보세요!
원시그널 솔루션 소개


이번 행사에서는 OneSignal 공동 창립자 겸 CEO George Deglin이 2025 고객 참여 현황 보고서를 기반으로 최신 트렌드를 공유하며, 다양한 패널 세션을 통해 실무에 바로 적용할 수 있는 메시징 전략과 모범 사례를 소개했습니다.
특히 원시그널이 준비 중인 AI 기반 라이프사이클 마케팅 에이전트가 소개되었는데요,

CRM 전문가가 내부에 있는 기업이 드문 상황과, 그만큼 실행이 어려운 CRM 마케팅 분야를 보완하기 위해 AI의 도움을 받아 고객 이탈을 막고 최적의 마케팅 전략을 제안해주는 AI 에이전트를 준비 중이라고 합니다.
관련 내용이 궁금하시다면 👉 원시그널을 방문해보세요!
솔루션 소개 및 고객사 패널토크 : 원시그널 APAC 파트너십 리드, 모드하우스


패널 세션에서 모드하우스는 유저 경험에 집중하며, ‘CRM을 제대로 해보자’는 확신을 가지고 원시그널 도입을 결정한 여정을 공유했습니다.
한정된 리소스와 비용 문제 속에서도 다양한 논의를 거쳐 최종적으로 툴을 도입하기까지의 과정이 인상적이었습니다.
CRM 솔루션 활용 가이드 및 사례 : 마티니

마티니의 이건희 COO는 솔루션을 실무에 어떻게 적용할 수 있을지 실제 사례와 함께 명확하고 실용적인 인사이트를 전했습니다. 👇
✅ 마케팅 자동화 & 개인화: AARRR 퍼널 기반 자동화 캠페인 Critical Path를 활용한 시나리오 설계
✅ AB 테스트: 추측이 아닌 데이터 기반으로 유저 행동을 분석하고 최적의 선택을 도출
✅ 프로덕트 개선: 신규 기능 사용률 향상을 위한 실사용 데이터 기반 분석 및 유도 전략
✅ 마테크 솔루션 연동: 다양한 솔루션 간의 연계를 통해 한계를 보완하고, 부가가치를 극대화
✅ CS / CX 연계: 유저 경험 향상을 위한 CRM 솔루션의 고객지원
.png)
특히 실제로 마티니가 진행한 8000여개가 넘는 캠페인에서 얻은 인사이트를 바탕으로 다양한 사례를 가지고 CRM 솔루션을 ‘잘’ 사용하는 방법을 공유했습니다.
마케팅 리더 패널 토크 : 마티니, 마켓핏랩
마지막 세션이었던 리더 패널 토크에서는 마티니 이선규 CEO와 마켓핏랩 김선영 SVP가 깊이 있는 경험과 인사이트를 공유했습니다.

고객을 제대로 이해하기 위한 CRM 데이터의 핵심 네 가지(기본 정보, 행동 이력, 최신 활동, 상호작용 데이터)를 어떻게 활용할지, 그리고 RFM 분석을 기반으로 충성 고객을 구분하는 방법과 이를 실무에 적용하는 전략 등 깊은 인사이트가 돋보이는 실질적인 내용들이 공유되었습니다.
또한 마티니는 고객사의 CRM 운영 수준에 맞춰 입문, 중급, 고급 3단계로 전략적 액션 플랜을 공유했습니다:
📍 입문단계: 기본 데이터 수집하고 체계 구축, 신뢰 형성 메지지 설계, CRM 솔루션 검토 및 준비
📍 중급단계: 데이터 분석 및 인사이트 도출, 세그먼트 설정 및 타겟팅, 개인화 메시징 전략 구축
📍 고급단계: AI 기반 예측 모델 도입, 고도화된 세그먼트 운영, 전담 조직 구성 및 운영
이 외에도 여러 인사이트들이 가득했는데요, 리더분들 통찰력 깊은 내용들로 구성된 알찬 시간이었습니다!
네트워킹


세션이 모두 종료된 후에는 업계 리더들과 함께하는 네트워킹 시간이 이어졌습니다. 원시그널에서 준비해주신 핑거푸드를 즐기며, 각 기업이 가지고 있는 CRM에 대한 고민과 인사이트를 자유롭게 나눌 수 있었던 유익한 시간이었습니다.
마티니가 그동안 진행한 CRM 캠페인 수 입니다.
다양한 분야의 다양한 캠페인을 거치며, 마티니는 데이터 기반 전략과 실무 중심의 실행력을 바탕으로 고객과 브랜드 사이의 ‘더 나은 연결’을 만드는 마케팅을 설계했습니다.
CRM, 퍼포먼스, 그로스 전 영역을 아우르는 풀퍼널 마케팅 전문 조직 마티니가 궁금하시다면 만나보세요.
마티니는 ‘잘’ 합니다. 👉마티니 만나보기

[Review] 그로스 캠프 4기
Amplitude, 잘 사용하고 계신가요?
마티니에서는 실무에서 앰플리튜드(Amplitude)를 더 효과적으로 활용할 수 있도록 돕기 위해 4주간의 실전 교육 프로그램, 그로스 캠프를 진행했습니다.
마티니의 그로스 캠프 4기! 어떻게 진행되었는지 아래서 확인해보세요 ⬇️
.png)
행사명: 그로스 캠프 4기 - Martinee X Amplitude
장소: 서울 서초구 서초대로38길 12 마제스타시티 타워2 12F
일시: 2025년 3월 26일 ~ 4월 16일 매주 수 오후 3시
누구를 위한?
- Amplitude의 주요 기능들을 포함하여 기초 개념부터 실무 활용까지 배우고 싶은 분
- Amplitude 기반 그로스 마케팅에 관심이 있으신 분
어떤 내용을?
- 그로스 마케팅의 기초 개념부터 실무에 활용하는 응용까지 단계적으로
- Mar-Tech 솔루션을 활용한 마케팅 고급 분석 방법과 통합 데이터 기반 인사이트
어떤 결과를?
- 그로스 마케팅 워크 프로세스 이해
- 데이터 기반 유저 분석 & 서비스 분석을 통한 서비스 개선 방법
- Mar-Tech 솔루션을 활용한 데이터 드리븐 분석 활용
어떻게 진행하였나요?
- 오프라인 4회에 걸쳐, 개념과 실습을 한번에!

어떤 것들을 배웠나요?

그로스 캠프 4기는 LV. 1, LV. 2, LV. 3, LV. Expert 총 4번의 세션으로 진행되었습니다.탐색적 데이터 분석부터 코호트, AARRR 분석 등 그로스 마케팅을 위한 핵심 데이터 분석 개념과 적용 방법에 대해 다뤘습니다.
그로스 캠프 4기 첫번째 시간은 앰플리튜드 차트 분석의 기초에 대해 알아보는 시간이었습니다.
.jpg)
우선 데이터 분석은 무엇이고, 왜 필요한 지 짧게 이해하는 시간을 가졌습니다.
.jpg)
뒤를 이어 앰플리튜드의 활용 목적, 데이터 구조, 데이터 택소노미 (Data Taxonomy) 설계에 대해 알아보았고, 앰플리튜드의 기본 차트인 세그먼트(Segment), 퍼널(Funnel), 리텐션(Retention) 차트를 앰플리튜드 차트로 직접 보면서 진행했습니다.

또한 중간 중간 문제를 통해 앰플리튜드 필수 차트를 어떻게 실무에 적용하는지도 배워보았습니다.
문제는 앰플리튜드 데모 계정을 통해 직접 분석 값을 구하는 내용이었는데요, 세세하게 답을 구하는 과정까지 알려주셔서 개념도 익히고 실습도 해볼 수 있었습니다!

이어진 시간들에서는 앰플리튜드 차트 분석의 고급 버전과 AARRR, Aha-Moment, 다른 솔루션과 연계한 활용방식 등을 배워보았습니다.

LTV(고객 생애 가치), Lifecycle, Engagement matrix, Cohort(코호트)까지 데이터와 고객을 분석하기 위해 필요한 기능들을 배웠는데요,
그 중 특정 기간동안 유사한 특성이나 경험을 공유하는 사용자 집단인 코호트 분석은, 전체 데이터를 보면 보이지 않던 인사이트도 유저 그룹을 나누면 뚜렷하게 드러나기 때문에 더더욱 중요하게 다뤘습니다.
모든 강의가 마무리되고, 앰플리튜드 자격증을 취득하는 시간도 함께 진행됐는데요,

많은 분들이 앰플리튜드 자격증 득에 성공하셨답니다!
(만약 획득 못하셨어도 마티니의 특별 노하우가 담긴 앰플리튜드 사용자 가이드를 보면 금방 취득하실 수 있어요!)

강의를 수강하신 모든 분들께는 마티니가 직접 제작한 앰플리튜드 유저 가이드(*108장 분량)를 제공하여 그로스 캠프 이후에도 앰플리튜드를 원활하게 사용하실 수 있도록 했습니다.
.jpg)
4회차도 마무리된 마티니의 그로스캠프 4기!
앞으로도 실무 중심 인사이트를 바탕으로 더 많은 성장을 도울 수 있는 교육 프로그램으로 찾아뵐게요!
마티니는 고객사의 비즈니스 성장을 돕는 파트너로서, 데이터 기반 전략과 실무 중심 인사이트를 바탕으로 더 정교하고 지속 가능한 마케팅을 함께 만들어갑니다.
데이터로 진짜 성장을 설계하고 싶다면, 지금 마티니와 함께하세요. 👉마티니 만나보기

MZ 그로스 매니저의 택소노미 설계 꿀팁 대방출(2) (ft. 버거킹)
2. 이벤트 설계 원칙
1장에서 이벤트 패스와 택소노미의 전반적인 구조를 다루었다면, 이제 개별 이벤트를 어떻게 설계해야 하는지에 대해 고민해볼 차례다. 택소노미는 단순히 이벤트를 나열하는 것이 아니라, 어떤 이벤트를 정의할지, 각 이벤트가 어떤 역할을 해야 하는지, 그리고 데이터 분석에 실질적으로 도움이 되는지를 고려하며 설계해야 한다.
버거킹 택소노미를 설계하면서 나는 처음에 “이벤트를 최대한 많이 수집하는 것이 좋은 것 아닌가?”라는 생각을 했다. 하지만 이는 큰 착각이었다. 불필요한 이벤트를 줄이고, 필요한 이벤트만 남기는 것이 너무나 중요했다. 너무 많은 이벤트가 있으면 데이터가 복잡해지고, 분석 과정이 오히려 더 어려워지기 때문이다.

이벤트를 정의할 때 중요한 것은 단순히 많은 데이터를 쌓는 것이 아니라, 데이터가 실제로 분석에 활용될 수 있도록 구조적으로 설계하는 것이다. 그렇다면, 실무에서 효율적인 이벤트 설계란 무엇일까?
2.1. 모든 이벤트를 잡지 마세요. 제발!
웹 및 앱에서는 다양한 이벤트가 발생하게 된다. 누군가는 제품을 검색할 수도, 추천 제품에 호기심을 가지고 해당 제품의 상세페이지를 확인할 수도, 장바구니에 담긴 제품들을 점검할 수도 있다. 그렇다면 우리는 발생할 수 있는 모든 경우의 수의 이벤트를 수집해야만할까? 당연히 그렇지 않다. 특히 Amplitude에서는 모든 이벤트를 수집하면 고객사가 어마어마한 비용을 지불하게 된다. 그럼 어떠한 이벤트를 잡아야 할까?
해답은 간단하다. 마케터의 관점에서 생각하는 것이다.
해당 이벤트를 수집하는 것이 마케팅의 측면에서 유의미할까?
해당 이벤트에서 수집한 정보를 바탕으로 마케팅 개선을 유도할 수 있을까?
버거킹 프로젝트에서는 다음과 같은 상황이 있었다. 사이드 추천 팝업을 닫을 때 “오늘 하루 추천 받지 않음”과 “닫기”의 두 가지의 버튼이 존재하였고, 이에 따라 이벤트를 구분하는 2가지의 시나리오가 발생하였다. 어떤 방법이 나아보이는가?
🍔 버거킹 프로젝트 - 사이드 추천 팝업 닫기

stop_side_recommend_button/close_side_recommend_button
: 두 가지 케이스를 별도의 이벤트로 나누어 수집closed_side_recommend_popup
: 두 가지 케이스를 하나의 이벤트로 통합하여 수집
팀장님과 상의 후 내린 결론은 "해당 이벤트는 수집하지 않는다"였다. 이유는 마케팅적 관점에서 생각해보면된다.
사이드 추천 팝업으로 발생하는 정보로 활용할 수 있는 마케팅적 분석은 “추천에 대한 고객 전환율”이다. 다시 말해 마케터가 궁금한 것은 해당 팝업의 제품을 클릭하여 구매까지 이어지는 고객의 비율이며, 해당 팝업을 닫는 유저 비율을 만약 알고 싶다면 (1 - 추천에 대한 고객 전환율)을 통해 충분히 쉽게 파악할 수 있다. 따라서 사이드 팝업을 닫는 것에 대한 이벤트는 마케팅 관점에서 낮은 효용을 가지며, 해당 이벤트를 수집한다면 이는 의미없이 과도한 이벤트를 집계하는 것이 될 수 있다.
물론, 택소노미에 정답은 없다. 고객사의 다양한 니즈에 따라, 그리고 그로스 매니저의 판단에 따라 얼마든지 변화할 수 있기 때문이다. 예를 들어 버거킹에서 UI/UX 관점에서의 개발도 요구되는 상황이었다면, 시나리오 1번처럼 두 가지 이벤트를 별개로 수집하는 것이 필요했을지도 모른다. 택소노미의 본질은 데이터 분석을 위한 구조를 설계하는 데 있다. 즉, 수집되는 이벤트는 항상 분석 목적이 명확해야 한다. 단순히 “이벤트를 기록하면 좋을 것 같아서”라는 이유로 데이터를 쌓는 것이 아니라, 이벤트를 어떻게 활용할 것인지 먼저 정의한 후 수집해야 한다.
예를 들어, 설문조사를 설계할 때도 어떤 분석을 수행할 것인지 먼저 고려하고, 그에 필요한 질문을 구성한다. 마찬가지로, 택소노미 설계에서도 최종적으로 어떤 인사이트를 얻을 것인지 미리 정의한 후, 이를 달성하는 데 꼭 필요한 이벤트만을 수집하는 것이 중요하다. 이를 통해 불필요한 이벤트를 배제하고, 최적화된 구조를 설계할 수 있다. 다시 말해, “데이터를 수집하는 것”이 목표가 아니라, “데이터를 활용할 수 있도록 설계하는 것”이 목표가 되어야 한다.
2.2. 이벤트? 이벤트 프로퍼티?
버거킹 주문에는 “킹오더”와 “딜리버리오더”의 두 가지 타입이 존재한다. 킹오더는 직접 매장에서 식사하거나, 포장하는 등 대면을 통해 제품을 수령받아야하는 방식이며 딜리버리 오더는 제품을 지정된 주소로 배달받는 방식의 주문이다. 그리고 2023년도 택소노미에서는 두 가지 오더를 각각 k와 d로 구분하여 모든 이벤트를 분리 하였다.
예를 들어 제품의 상세페이지를 조회하는 이벤트인 item_detail_viewed를 킹오더 채널을 통한 경우라면 k_item_detail_viewed로, 딜리버리오더 채널을 통한 경우라면 d_item_detail_viewed로 구분하는 식이다. 그런데 해당 이벤트들을 처음 보자마자 가진 의문점이 하나 있었다.
이벤트 종류를 왜 이렇게 과도하게 많이 잡았을까?동일한 이벤트인데 굳이 왜 k와 d로 나누어 수집해야만 하는거지?
이벤트를 과도하게 세분화하는 것은 관리의 복잡성을 증가시키고, 데이터 분석의 일관성을 해칠 수 있다. 따라서 주문 유형을 구분해야 한다면, order_type을 이벤트 프로퍼티로 추가하는 것이 더 효율적이라고 생각했다. 이에 대한 해답을 찾기 위해 또다시, 팀장님을 찾아갔다.🥺
이유는 간단했다. 고객사가 생각하는 해당 이벤트의 중요도, 그리고 분석의 용이성 때문이었다. 택소노미는 그 자체가 목적이 아니라 후에 앰플리튜드를 활용한 데이터 분석 및 시각화에 사용되는 입력값이라는 것을 기억할 것이다. 따라서 택소노미는 고객사가 데이터를 쉽고 유용하게 활용할 수 있도록 작성되어야 한다.
예시를 들어보자. 다음은 버거킹 앰플리튜드 내 퍼널 차트 영역이다.


첫번째 사진의 차트는 k_item_list_viewed 이벤트를 실행한 유저 중 k_order_clicked 이벤트를 실행한 유저의 비율을 시각화하고 있다. 즉, [킹오더] 중에서 [아이템 목록을 조회한] 유저의 [주문하기 버튼 클릭] 전환율을 나타내고 있다.
현재는 오더의 종류를 k와 d 로 이벤트 상에서 구분해 놓았기 때문에 해당 차트를 제작하기 위해서는 [Events] 영역 내에서 이벤트를 클릭한 후 k_item_list_viewed, k_order_clicked 의 두 이벤트를 순차적으로 선택하면 된다. 만약 두 오더를 이벤트 상에서 구분하지 않고, 프로퍼티로 구분한다면 동일한 차트를 나타내기 위해서 어떻게 해야할까?

기존에는 두 번의 클릭으로 해당 차트를 만들어 낼 수 있었지만, 두 오더를 통합한다면 이벤트를 선택하고, 각 이벤트의 프로퍼티를 선택하고, 프로퍼티의 값을 선택하면서 총 6번의 클릭이 요구된다.
엥? 이게 왜 복잡하지. 그냥 클릭 좀 하면 되는거 아닌가?
위와 같이 생각할 수 있지만 고객사의 입장은 매우 다르다.
요식업에서 고객의 방문과 배달은 완벽히 분리되어있는 두 주요 구매 퍼널이고, 이에 따라 분석 시 통합된 하나의 분석보다 별개의 분석으로 나누어 보는 것이 더 유용한 인사이트를 제공한다.
마찬가지로 버거킹 입장에서 킹오더와 딜리버리 오더는 완벽히 구분하여 분석되어야 하는 두 가지의 구매 퍼널이다. 즉, 모든 분석에 기본적으로 두 오더가 구분되어야 하는데 모든 이벤트에 [+ Filter by]를 추가적으로 걸어주어야하는 구조라면 고객사의 마케터 입장에서 피로도는 매우 상승할 것이다. 또한 고객사의 모두가 택소노미와 앰플리튜드에 숙달되는 것은 매우 힘든 일이다. 만일 초보자가 이를 사용한다면 계속해서 가이드를 확인해야만 하며 이는 고객사 데이터 문해력을 저해하는 행위일 것이다.
쪼갰을 때 장점은 알겠어. 근데 합쳐서 보고싶다면? 전체 주문에 대한 전환율이 보고 싶을 때도 많잖아.
혹시 이런 생각을 했다면 당신은 나와 아주 그냥 똑같은 사람이다! 해당 질문에 대한 해답은 커스텀 이벤트(Custom Event)이다.
✅ 커스텀 이벤트(Custom Event) 생성법
: Amplitude에서는 두 가지 이상의 이벤트를 묶어서 볼 수 있는 커스텀 이벤트가 존재한다. 해당 커스텀 이벤트를 정의하면 이후에도 쉽게 이벤트를 불러올 수 있다.
1. [Combine events inline]을 통해 두 가지 이벤트를 삽입하기

2.[Save Custom Event]를 통해 두 이벤트를 하나의 이벤트로 묶기

3. 커스텀 이벤트를 생성할 수 있는 마케터가 되어보자!

계속해서 말했지만 택소노미에 정답은 없다. 그러나 왜 그렇게 택소노미를 구현했는지에 대하여 다른 사람을 설득할 수 있는 논리가 필요하다. 그리고 그 논리가 이번엔 고객사의 편의성이다.
2.3. View 이벤트의 효용성 고민하기
이벤트 트리거에는 몇 가지 방식이 존재하지만, 주로 click과 view 가 활용된다. 버거킹 택소노미에서도 소수의 complete 트리거를 제외하고는 대부분의 이벤트가 click 혹은 view 로 트리거되었다.
신기한 점은 2023 버전 버거킹의 택소노미에는 유독 view 이벤트가 많았다는 것이다. view 이벤트는 어떨 때 활용하면 좋을까?
그러나 View 이벤트를 과도하게 사용하면 데이터 최적화에 문제가 생길 수 있다. 페이지를 로드할 때마다 트리거가 된다면 불필요한 이벤트가 대량으로 수집될 위험이 있기 때문이다.
따라서 특정 이벤트의 트리거를 view 로 잡는 것은 정보 수집 측면에서 하이 리스크, 하이 리턴 (High Risk, High Return)이 될 수 있으므로 우리는 이벤트 트리거를 설정할 때 view 의 효용성을 항상 생각해야 한다. 이에 따라 버거킹 택소노미의 일부 이벤트에도 변경점이 발생하였다.
이 과정을 통해서 무의미해진 기존의 6개의 이벤트는 삭제, 2개의 이벤트가 추가되면서 이벤트 패스의 최적화가 이루어졌다. 이처럼 트리거 방식 하나를 선택하는 것만으로도 데이터의 질과 분석의 신뢰도가 달라질 수 있다. 이벤트 설계에서 view 이벤트는 사용 목적이 명확할 때 신중하게 활용하는 것이 바람직하다.
(3부에서 계속)
관련 블로그글 링크
1부 : MZ 그로스 매니저의 택소노미 설계 꿀팁 대방출(1) (ft. 버거킹)
3부 : MZ 그로스 매니저의 택소노미 설계 꿀팁 대방출(3) (ft. 버거킹)
.png)
마티니 기사 모음집
CRM, 그로스, 퍼포먼스를 아우르는 데이터 기반 풀퍼널 마케팅 전략.
마티니의 실무 중심 인사이트와 최근 미디어 보도 내용을 한눈에 만나보세요.

택소노미부터 개인화까지 '마테크' 전성시대… CRM 마케팅 체크 포인트 3가지 (25.03)
“CRM 마케팅의 성패는 설계부터 분석까지의 정교함에 달려있다.”
마티니아이오 이선규 대표는 브랜드브리프와의 인터뷰를 통해 CRM 마케팅 실무에 필수적인 체크포인트로 ▲정확한 행동 데이터 분류를 위한 ‘이벤트 택소노미 설계’ ▲전환율을 높이는 실시간 ‘개인화 전략’ ▲성과를 측정하는 ‘증분 분석’의 중요성을 강조했다.
특히 QA 과정과 조직 내 역할 분담(R&R)의 체계화가 정교한 마케팅 운영의 핵심이라며, 실무 노하우와 함께 고객사의 디지털 전환을 돕는 마티니의 전문성을 밝혔다.
마티니는 KFC·쏘카·오늘의집 등 다양한 업계에서 실질적인 성과를 내며 CRM 자동화와 데이터 기반 마케팅 고도화를 이끌고 있다.
마티니 아이오는 어떻게 성공적인 CRM 마케팅을 진행할까? (25.03)
마티니의 김찬희 CRM 마케터는 'Grow with Braze 2025'에서 이유식 브랜드 베베쿡과의 협업 사례를 통해 F&B 산업에서의 CRM 전략을 소개했다. 생후 일자 기반의 맞춤형 상품 추천으로 재구매율을 높이고, 개발 리소스의 한계를 CRM 전략으로 보완한 실행 사례를 공유했다.
특히 베베쿡의 핵심 과제였던 리텐션과 고객당 평균 매출(ARPU) 증대를 장바구니 금액 기반 혜택 메시지 등으로 효과적으로 해결한 전략을 강조했다.
김 마케터는 고객 행동 분석과 개인화 전략을 통해 짧은 시간 안에 고객과의 신뢰를 구축하고 실질적인 성과로 이어지는 CRM 마케팅 실행법을 구체적으로 풀어냈다.
마티니 아이오, 아태 지역 핵심 마케팅 컨퍼런스서 실무 전략 공유 (25.03)
풀퍼널 마케팅 전문 기업 마티니아이오(이하 마티니)가 오는 19일 브레이즈(Braze) 주최 마케팅 컨퍼런스 ‘그로우 위드 브레이즈 서울’에 한국 파트너로 참여한다.
이번 행사에서는 AI 기반 마테크 전략, 고객 충성도 제고, 통합 채널 설계, 실시간 인게이지먼트 가이드 등 총 3개 주제로 다양한 인사이트가 공유될 예정이다.
마티니는 이선규 대표가 ‘브레이즈를 200% 활용하는 CRM 체크리스트’ 세션을 통해 실무 전략을, 김찬희 매니저와 베베쿡 김도균 전무가 F&B 산업 내 재구매 전략을 발표한다.
이선규 대표는 “빠르게 변화하는 마케팅 환경에서 마티니의 전문성과 현장 경험이 기업 성장을 돕는 핵심 자산”이라며 브레이즈의 국내 유일 솔루션 파트너로서의 참여 배경을 설명했다.
한편 마티니는 롯데온, 무신사, KFC, 두나무, 기업은행 등과 협업하며 설립 3년만에 매출 100억, 영업이익 흑자를 달성한 바 있다.
마티니 아이오, ‘그로우 위드 브레이즈 서울’서 CRM 실무 전략 공개(25.03)
마티니아이오가 글로벌 CRM 플랫폼 브레이즈(Braze)의 컨퍼런스 ‘Grow with Braze – Seoul’에 국내 공식 파트너로 참여한다.
이번 행사에서 마티니는 자사의 CRM 전문성을 바탕으로 실무 중심의 세션 두 개를 운영한다. 이선규 대표는 ‘Braze를 200% 활용하는 CRM 체크리스트’를, 베베쿡 김도균 전무 및 마티니 김찬희 매니저는 F&B 업계 사례 기반의 재구매 전략을 공유할 예정이다.
이 대표는 빠르게 발전하는 마케팅 산업 속에서 마티니가 쌓아온 기술 내재화 및 고객 맞춤형 전략 역량을 강조하며, 브레이즈의 국내 유일 솔루션 파트너로서 책임감을 밝혔다.
마티니는 CRM 컨설팅부터 퍼포먼스 캠페인까지 풀퍼널 마케팅을 수행하며 다양한 업계와 협업해왔다. 설립 3년 만에 매출 100억 원을 달성하며 빠른 성장세를 이어가고 있다.
마티니 아이오, 브레이즈 커넥션즈 서울서 CRM 마케팅 핵심 노하우 공유 (24.11)
풀퍼널 마케팅 전문기업 마티니아이오(이하 마티니)가 지난 5일 열린 ‘브레이즈 커넥션즈 서울 2024’에서 KFC 사례를 중심으로 CRM 마케팅 실무 노하우를 공유해 호응을 얻었다.
이번 행사는 브레이즈 주최, 마티니·AB180·CJ올리브네트웍스 후원으로 진행됐으며, 글로벌 행사인 FORGE 라스베이거스 2024에서 발표된 브레이즈 최신 업데이트도 국내 최초로 소개됐다.
마티니는 솔루션 도입부터 고도화, 성과 분석에 이르는 CRM 전 과정을 설명하며, 국내외 참석자들에게 실질적인 인사이트를 전달했다.
이선규 대표는 “철저한 분석과 최적화된 솔루션 설계로 성장을 지원하는 풀스택 마케팅을 제공하는 것이 마티니의 원칙”이라고 강조했다.
마티니는 퍼포먼스, CRM, PA, BI 등 전 분야에서 전문성을 보유한 마케팅 파트너로, 설립 2년 만에 업계 선도 기업으로 자리매김하며 다수 브랜드의 성장을 지원하고 있다.
애피어-마티니아이오, AI 솔루션 통한 마케팅 ROI 극대화 협력 (24.11)
글로벌 AI SaaS 기업 애피어(Appier)가 풀퍼널 마케팅 전문기업 마티니아이오(이하 마티니)와 전략적 파트너십을 체결했다.
이번 협업을 통해 애피어는 AI 기반 마케팅 솔루션 ‘AIQUA’, ‘BotBonnie’, ‘AIRIS’를 중심으로 개인화된 고객 여정 최적화를 지원하며, 한국 시장 내 입지를 강화할 계획이다.
마티니는 마케팅 분석, 솔루션 도입·운영, CRM 마케팅까지 전 과정을 아우르는 풀퍼널 마케팅 기업으로, 이번 파트너십을 통해 AI 기반 마테크 솔루션 역량을 더욱 확장할 수 있게 됐다.
마티니 아이오가 알려주는 풀퍼널 마케팅의 핵심 인사이트는 (24.07)
마티니가 31일 코엑스에서 열린 ‘모던 그로스 스택 2024’에서 실전 중심의 CRM 전략과 디지털 마케팅 인사이트를 공유했다.
이건희 팀장은 ‘우리 잘하고 있는 건가?: CRM 마케터들이 궁금해하는 고민과 해결 방안’ 세션에서 개인화 전략과 MMP·PA 연계법 등 실무 노하우를 전했다.
공동 세션에서는 쏘카·AB180과의 협업 사례를 소개하고, 이재철 팀장이 앰플리튜드·버거킹과 함께 버거킹의 디지털 전환 전략을 공유했다.
행사 현장에는 마티니 부스도 운영되어 실시간 컨설팅과 경품 이벤트로 업계 관계자들과 소통을 이어갔다.
이선규 대표는 “3개 세션을 통해 마티니의 전문성과 실무 경험을 나눌 수 있어 의미 있었다”며 앞으로도 다양한 기회를 통해 성장을 함께하겠다는 뜻을 밝혔다.
마티니는 데이터 기반 전략부터 실행까지 전 과정을 아우르는 풀퍼널 마케팅 전문 조직입니다.
앞으로도 축적된 실무 경험과 인사이트를 바탕으로, 고객사의 비즈니스 과제를 함께 고민하고 해결해 나가며 지속 가능한 성장을 만들어가는 든든한 마케팅 파트너가 되겠습니다. 😊

[Review] 브레이즈 실전 부트캠프

이번 Braze 부트캠프는 실무 중심의 전략적 사고와 실행력을 함께 익힐 수 있도록 Braze 자격증 취득을 위한 이론 세션과 Braze 실전 가이드 세션으로 구성되었습니다.
많은 분들이 함께해 주셔서 더욱 뜻깊은 시간이었는데요, Braze를 보다 효과적으로 활용하고 싶으셨던 분들께 실질적인 인사이트를 드릴 수 있어 더욱 의미 있었습니다.
Braze 부트캠프 세션이 궁금하시다면 아래 내용을 통해 자세히 확인해보세요! 🔽
Session 1. Braze Certified Practitioner Bootcamp

Session 2. 유저 경험을 바꾸는 Braze 실전 가이드

브레이즈 부트캠프, 어떻게 진행되었을까요?

세션 1은 Braze 본사에서 오신 Sang Kim(김상우) 님의 강의로 진행되었습니다.
이 강의는 실제로 Braze 본사에서도 자격증 취득을 위한 속성 과정으로 사용되는 커리큘럼이라고 해요.
세션 1 리뷰 : Braze 배우기

첫 번째 세션은 Braze의 전반적인 기능을 빠르게 습득할 수 있도록 구성된 자격증 대비 강의로, 아래와 같은 커리큘럼으로 진행되었습니다.

세션1 에서는 Braze에서 데이터가 어떻게 통합되고 흐르는지, 그리고 이를 실제 마케팅 사용 사례에 어떻게 적용할 수 있는지에 대해 살펴보았습니다.
또한 세분화 도구를 활용해 타겟 메시징을 위한 고객 세그먼트를 설정하는 방법, 크로스 채널 메시징 전략, Braze 사용자 데이터를 기반으로 실시간 개인화 메시지를 구성하고 캠페인을 설계하는 방법에 대해 알아보는 시간을 가졌습니다.
마지막으로 Braze 대시보드를 활용해 캠페인 성과를 분석하고 리포트하는 방법까지 다루며 세션이 마무리되었고, 각 섹션이 끝날 때마다 복습 퀴즈를 통해 내용을 점검했습니다.

강의의 마지막은 Braze Certification 자격시험 응시로 마무리되었는데요,
실전에서 바로 활용 가능한 지식과 자격 취득까지 한 번에 경험할 수 있었던 알찬 시간이었습니다.
세션 2 리뷰 : 실전에서 Braze 사용하기

두 번째 세션은 마티니에서 CRM팀을 이끌고 있는 이건희 COO님이 '마티니가 제안하는 CRM 체크리스트’를 중심으로, 실전에서 Braze를 효과적으로 활용하는 방법을 다뤘습니다. 주요 커리큘럼은 다음과 같았습니다.

첫 번째로 다룬 이벤트 택소노미는 캠페인 실행을 위한 핵심 설계 요소입니다. 데이터를 어떻게 수집하고 구조화할지에 대한 방향을 제시하며, 자동화·개인화·분석 등 CRM의 모든 흐름에 영향을 주는 ‘재료’로써의 중요성을 강조했습니다.
이어진 자동화 파트에서는 자동화 캠페인을 구축해야하는 이유를 시작으로, 실제 구축 프로세스를 1단계부터 7단계까지 상세히 설명하며 기본기를 탄탄히 다졌습니다.

개인화 세션은 Braze의 핵심 기능인 개인화 태그, Liquid, Connected Content를 중심으로 진행되었습니다.

마지막으로 왜 CRM에 분석이 필요한지, 그 분석을 선행적 분석과 후행적 분석으로 나누어 어떻게 진행해야하는 지 세세하게 나눠 설명하며 성공적인 CRM을 위한 Braze 실전 가이드 세션을 마무리했습니다.
(늦은시간까지 열정적으로 강의에 집중해주셔서 감사합니다 🔥)

이번 Braze 부트캠프는 Braze 본사에서 진행하는 공식 자격 과정을 기반으로, 실제 자격 시험까지 함께하며 참가자분들의 Braze 실무 역량을 한층 끌어올리는 시간이었습니다.
또한 마티니는 8,000개 이상의 캠페인 운영 경험을 바탕으로, CRM 전략의 A to Z를 누구보다 명확하고 실용적으로 전달하며 CRM 성과를 높이는 핵심 노하우를 전했습니다.
앞으로도 마티니는 Braze 솔루션 파트너로서, 현장에서 바로 적용할 수 있는 인사이트와 전문성을 바탕으로 더 많은 기업들이 CRM을 통해 실질적인 성장을 이룰 수 있도록 함께하겠습니다.
다음 Braze 부트캠프에서도 더 깊이 있는 실전 전략으로 찾아뵙겠습니다! 😊

MZ 그로스 매니저의 택소노미 설계 꿀팁 대방출(1) (ft. 버거킹)
Intro. 택소노미는 어렵고 복잡하다.
“택소노미요? 쭉 훑어봤는데 막 어렵지는 않더라고요. 빨리 끝내고 앰플리튜드 배우고 싶어요.”
입사 1주일 차, 입사 동기에게 실제로 했던 말이다. 택소노미의 개념적 이해는 어렵지 않았다. 평소 Python 코딩을 해왔기에 익숙한 개념들이 많았기 때문이다. 이벤트는 Class, 프로퍼티는 매개변수와 유사했다. 예를 들어, 아래는 brand, model, year를 매개변수로 받아오는 Car 클래스를 정의한 코드다.
class Car: # Car라는 클래스를 정의
def __init__(self, brand: str, model: str, year: int):
self.brand = brand
self.model = model
self.year = year
# Car 클래스에는 brand, model, year의 3가지 매개변수가 필요하다
택소노미 스키마 역시 이와 매우 유사한 형태를 띤다. 하나의 이벤트를 정의할 때 여러 프로퍼티를 필요로 하고, 이는 데이터 분석의 기본 단위가 된다. "택소노미, 쉽네?"라고 생각했다.
그러나 그건 내가 택소노미의 표면만을 보았기 때문이었다. 실제로 설계를 시작하자 복잡한 이벤트 간의 관계, 속성 간의 상호 의존성, 퍼널의 다양성, 그리고 각기 다른 상황에서 어떤 이벤트를 발생시켜야 하는지에 대한 고민들이 쏟아져 나왔다. 택소노미는 단순한 데이터 구조 설계가 아니라 비즈니스 로직과 사용자 행동을 체계적으로 모델링하는 과정이었다.
사실, 버거킹은 마티니에서 이미 2023년에 한 차례 앰플리튜드 택소노미를 구축한 경험이 있었다. 하지만 이후 앱이 계속해서 리뉴얼되면서 기존 택소노미와 실제 어플 사용경험이 점점 맞지 않게 되었다. 그 결과, 2025년을 맞아 새롭게 택소노미를 리뉴얼할 필요가 생겼다. 버거킹 측에서는 원하는 이벤트 목록을 추가하여 약식의 택소노미를 제공해 주었고, 이를 바탕으로 2025년 버전의 이벤트 패스와 택소노미를 새롭게 설계해야 했다. 그러나 이 과정에서 가장 큰 난관이 있었다. 버거킹과의 직접적인 인터뷰가 불가능했다. 즉, 내가 가진 정보는 제한적이었고, 단순히 제공된 문서만으로는 버거킹의 데이터 분석 및 비즈니스 로직 니즈를 100% 이해하는 것이 어려운 상황이었다. 그 결과, 작은 결정 하나를 내릴 때마다 "이게 정말 맞는 방식일까?"라는 고민을 끊임없이 해야 했다.
그렇게 머리가 터질 것 같은 열흘간의 '버거킹 택소노미' 설계를 거치고, 팀장님을 붙들고 질문 폭격을 쏟아낸 끝에, 나는 택소노미 설계를 위한 몇 가지 실무적인 팁을 정리할 수 있었다. 나처럼 처음 택소노미를 구축하려는 사람들에게 작은 도움이 되길 바라며, 내가 직접 부딪히며 배운 교훈들을 재미있게 공유하려 한다.
1. 이벤트 패스 및 택소노미 전반
우선적으로 해야 할 일은 이벤트 + 이벤트 프로퍼티를 고려한 이벤트 패스 및 이벤트 택소노미를 작성하는 것이다.
이벤트 패스는 고객사의 웹사이트나 앱을 직접 사용해보면서 분석에 유용한 정보를 담고 있을 이벤트를 찾아 마인드맵 형태로 작성하는 과정이다. 이는 고객이 경험하는 유저 여정을 체험하며 퍼널의 연결성을 파악하는 행위이며, 각 페이지에서 어떤 이벤트가 발생하고, 어떤 정보를 수집해야 할지를 개괄적으로 이해하는 데 도움을 준다.

이벤트 택소노미는 이벤트 스키마 설계서와 동일한 의미를 갖는다. 즉, 이벤트를 어떤 기준으로 쌓아서 볼 것인지 정의하는 문서이다.
문제는 날이 갈수록 구매 퍼널이 다양해지고 유저 여정이 복잡해지는 등 앱의 절차가 점점 더 복잡하고 무거워지고 있다는 점이다. 그러나 이 모든 퍼널에 대하여 이벤트를 계속해서 추가할 수는 없다. 새로운 이벤트가 지나치게 많아지면 데이터 분석이 어려워지고, 이벤트 프로퍼티가 불필요하게 늘어나면서 데이터의 일관성이 깨질 수 있기 때문이다. 또한 이벤트 패스와 택소노미를 작성할 때 고려해야 할 부분이 너무 많다. 예를 들어
이 모든 요소를 고려하면서 설계를 진행하다 보면, 무엇이 우선순위인지, 어디까지 초기에 디테일하게 구상해야 하는지 갈피를 잡기가 어려워진다. 그렇다면, 효율적인 택소노미 설계를 위해서는 어떻게 해야 할까?
1.1. 전체 그림을 먼저 보기 (사실 힘들다)
처음 이벤트 패스를 작성할 때 나는 처음부터 완벽하게 정리하고 싶었다. 오류나 빈 곳을 발견하고 나중에 고치는 것이 더 피곤한 일이라고 생각했기 때문이다. 그래서 처음부터 모든 화면을 다 들어가 보고, 설정, 멤버십, 쿠폰, 프로모션 등 버거킹 앱 내의 모든 이벤트를 고려하려 했다.
하지만 이렇게 모든 요소를 한 번에 설계하려고 하면 일이 지나치게 복잡해지고 진행 속도가 늦어진다. 중요한 것은 우선 고객의 유저 경험에서 굵직한 이벤트만 먼저 파악하는 것이다.
이 당연한 흐름을 먼저 기억했다면, 해당 전환이 일어나는 주요 화면을 중심으로 캡처하고 뼈대를 만들었을 것이다. 이후에 디테일을 보완하면 충분했다.
주요 이벤트 패스를 작성하는 것은 글을 쓸 때 개요를 먼저 정하는 것과 같다. 개요 없이 글을 쓰면 무조건 중구난방으로 튀게 되어있다. 이벤트 패스와 택소노미 역시 마찬가지다. 전체 그림을 볼 수 있어야 다른 곳으로 빠지지 않고 효율적인 설계를 할 수 있다. 만약 처음부터 세부 이벤트와 각 이벤트에서 수집하는 모든 프로퍼티를 고려한다면, 눈 앞에 거대한 나무에 가로막혀 전체 숲을 보지 못하고 길을 헤매게 될 것이다. 세부적인 이벤트에 매몰되지 말고 전체 흐름을 봐야 한다!
1.2. 퍼널 분리를 통한 이벤트 패스 간소화
사실 이 장은 1.1과 연결된 내용이다. 앞서 이야기했듯이, 이벤트 패스를 작성할 때 가장 먼저 해야 할 일은 메인 퍼널을 정의하고 그리는 것이다.
버거킹의 경우, 주문으로 이어지는 퍼널이 정말 많았다.
- 메인홈 하단 주문하기 버튼을 통한 주문
- 배너를 통한 전환
- 쿠폰을 통한 전환
- 과거 주문 히스토리 기반으로 한 전환
- 추천 시스템을 통한 전환
각 퍼널별로 유입할 수 있는 경로도 다양했다. 예를 들어, 배너 클릭만 해도 5군데 이상에서 유입 가능했고, 무한 반복의 사이드 제품 추천시스템도 있었다. 이 모든 퍼널을 하나의 이벤트 패스 안에 그려 넣는다면? 패스가 지나치게 복잡해지고 직관성이 떨어질 것이다. 처음에 내가 작성한 1차 버전의 이벤트 패스는 정말 끔찍했다. 선들이 얽히고설켜 있고, 순환구조까지 포함되어 혼돈 그 자체였다. 그래서 내린 결론은 퍼널을 분리하고, 연결 지점만 정의하는 것이었다.
🍔 버거킹 프로젝트 - 메인퍼널과 서브퍼널의 분리
1. 우선 메인 퍼널을 정의한다: 홈화면 → 매장 선택 → 버거 선택 → 장바구니 → 결제

2. 다른 구매 퍼널을 별도의 페이지에 따로 정의하고, 메인 퍼널로 합류하는 지점을 설정한다.
- 예시: banner_clicked → event_detail_viewed → 주문하기 버튼 클릭 시 메인퍼널로 합류

3. 반복해서 퍼널별로 개별 페이지를 제작하고, 메인 퍼널과의 연결성을 시각적으로 정리한다.

이렇게 구매 전환 퍼널들을 분리하니 복잡했던 경로도 훨씬 단순화되었다.
또한, 지나치게 세세하게 이벤트 패스를 만들 필요는 없다. 사이트 내 모든 페이지를 캡처할 필요는 없으며, 유의미한 이벤트가 발생하는 화면만 정리하는 것이 훨씬 효과적이다. 예를 들어, 버거킹의 제품 추천 시스템은 무한 루프(?)를 형성한다. 고객이 장바구니에 제품을 담으면, 사이드 제품을 팝업으로 추천하고 이를 장바구니에 담으면 또다시 사이드를 추천하는 형식이다.

이러한 사이드 추천 페이지를 다 표현할 것인가? 언제까지, 몇 번째 추천까지 표현할 것인가. 반복되거나 무의미한 화면은 무시하는 것이 효율적인 이벤트 패스이다!
1.3. 이벤트 패스와 택소노미 시트는 유기적 관계
앞서 내가 이벤트 패스가 글의 개요 역할을 한다고 했으니, “이벤트 패스를 먼저 완성하고 나서 택소노미 시트를 작성하면 되겠다”고 생각했을 것이다. 나 역시도 그렇게 생각하였고, 서둘러서 이벤트 패스를 완성하고자 했다. 그러나 얼마 가지않아 또다시 문제에 직면하게 되었다.
예를 들어, 버거킹의 Main 퍼널에서는 후기 이벤트가 앞선 이벤트의 거의 모든 프로퍼티를 상속한다. 즉, order_completed 이벤트 하나만 해도 40개가 넘는 프로퍼티를 포함해야 했다.
“대체 어떤 프로퍼티들이 상속되고, 새로 추가되는거지?”
이 질문은 계속해서 반복되었고, 이벤트 패스만 보고는 도무지 답을 내릴 수 없었다. 특정 이벤트에서 어떤 프로퍼티를 유지하고, 어디서 새로운 프로퍼티를 추가해야 하는지 등이 정리되지 않으니 택소노미가 구체화되는 느낌을 받을 수가 없었다. 그래서 내린 결론은 이벤트 패스와 택소노미 시트를 병행하며 작업하는 것이었다.

이벤트 패스를 작성하면 전체적인 사용자 플로우를 한눈에 볼 수 있지만, 개별 이벤트가 수집해야 하는 데이터까지 파악하기는 어렵다. 반면, 택소노미 시트를 작업하면 각 이벤트별 데이터 정의를 체계적으로 정리할 수 있지만, 전체적인 흐름 속에서 프로퍼티의 연결성을 파악하기 어렵다. 결국, 두 작업은 병행되어야만 했다.
🍔 버거킹 프로젝트 - 이벤트패스/택소노미시트 병행 작업
1. 이벤트패스를 통해 주요 이벤트를 퍼널 순서대로 정의
2. 도출된 이벤트들을 우선적으로 시트에 정리 - [Event List] 시트

3. 시각적인 이벤트 패스를 확인하며, 이벤트 별 프로퍼티 정의 - [Event별 Property] 시트
: 프로퍼티의 상속을 고려하며, 이벤트의 순서대로 프로퍼티 추가

4. 프로퍼티가 정의될 때 프로퍼티 상세 내용 고려 - [Event Property 상세] 시트
: 프로퍼티의 타입, 예시 값 추가

5. 택소노미 시트 보완: 프로퍼티 간 중복/누락 여부 점검 및 일관성 유지
6. 업데이트된 정보를 반영하여 이벤트 패스 조정 : 변경된 이벤트를 반영, 불필요한 프로퍼티 제거
물론, 택소노미 시트가 최종적으로 완성해야 할 결과물이지만, 두 과정이 결코 따로 분리된 것이 아니라는 것을 상기했으면 좋겠다. 이벤트 패스는 택소노미 시트 제작에 도움을 주고, 또 다시 택소노미 시트는 이벤트 패스의 완성 및 구조화를 도와준다.
(2부에서 계속)
관련 블로그글 링크
2부 : MZ 그로스 매니저의 택소노미 설계 꿀팁 대방출(2) (ft. 버거킹)
3부 : MZ 그로스 매니저의 택소노미 설계 꿀팁 대방출(3) (ft. 버거킹)
%20(1).png)
[Review] Braze 활용 가이드부터 F&B 리텐션 전략까지 CRM의 모든 것 | GWB 2025
Martinee x GWB Seoul 2025


3월 19일, 콘래드 서울 그랜드볼룸에서 글로벌 CRM 솔루션 기업 Braze가 주최한 ‘Grow With Braze Seoul 2025’가 성황리에 개최되었습니다.
마티니는 지난해에 이어 올해도 연사로 참여해, 실무에서 마주하는 CRM 마케팅의 고민과 이를 해결해온 마티니만의 노하우를 공유했습니다.
이번 세션에서는 Braze를 보다 효과적으로 활용하기 위한 'Braze를 200% 활용하는 CRM 체크리스트', 그리고 베베쿡과 함께 F&B 업계의 재구매율을 높이기 위한 CRM 전략을 소개했습니다.
Braze 도입부터 실무 활용, 성과를 만들어낸 실제 사례와 인사이트까지, CRM 마케팅의 실전 전략이 가득 담긴 시간 아래서 확인해보세요!
Braze 더 잘 활용하고 싶은데.. 지금 잘 사용하고 있는건가?
: Braze를 200% 활용하는 CRM 체크리스트

CRM 마케팅, 잘 하고 있는지 궁금하셨다면?
마티니가 Grow With Braze에서 공유한 [Braze를 200% 활용하는 CRM 체크리스트] 세션에서는 CRM 성과를 높이기 위한 실무 중심의 세 가지 핵심 포인트를 소개했습니다.
✅ Check 01. 수집
CRM의 시작은 데이터 수집입니다.
어떤 데이터를 어떤 구조로 수집할지 정리한 이벤트 택소노미(Taxonomy) 문서를 기반으로, 이벤트 데이터를 수집하는 것이 중요합니다.

✅ Check 02. 분석
수집된 데이터를 바탕으로 인사이트를 도출해야 합니다.
선행 분석을 통해 재구매 주기, 첫구매까지의 소요 시간, 연관 구매 상품을 확인하고,
후행 분석을 통해 증분 분석과 A/B Test 등을 통해 실제로 전환을 일으키는 요소를 찾아내어 캠페인 성과를 측정합니다.

✅ Check 03. 활용
이제 데이터를 기반으로 고객과의 커뮤니케이션을 실행에 옮길 차례입니다.
Braze의 개인화 기능(태그, Liquid, Connected Content)을 활용해 고객 맞춤 메시지를 전달하고, 메시지를 카테고리화하여 운영 효율성을 높입니다.
또한 기획부터 발송, 분석까지의 프로세스에 맞춰 조직 내 역할과 책임(R&R)을 명확히 하는 것도 중요합니다.

한 번 사고 또 사게 만드는 CRM 전략
: F&B, ‘이렇게’ 하면 재구매율이 올라갑니다

마티니와 베베쿡이 함께한 세션에서는 작년 이 자리에서 Braze 도입을 결정한 베베쿡과 마티니의 CRM 전략 여정이 공유 되었습니다.
F&B 산업은 마티니가 가장 많은 인사이트를 쌓아온 분야 중 하나입니다. 마티니는 F&B 산업의 핵심 특성을 ‘고빈도 & 저가 구매 모델’로 파악했습니다. 자주 구매하지만 단가가 낮은 구조이기 때문에 고객을 얼마나 자연스럽게 다시 오게 만들고, 구매를 이어가게 유도하는지가 핵심인 것이죠. 따라서 업셀링과 크로스셀링을 유도할 수 있는 CRM 전략이 반드시 필요합니다.
목표 1: 한 번 들어온 고객의 리텐션 증대
✅ 첫 구매 유도 전략
이유식이라는 제품 특성상 아이의 생후일자에 따라 필요한 제품이 달라집니다.
마티니는 ‘생후일자 기반 개인화’ 전략을 통해 고객의 정보를 바탕으로 맞춤형 상품을 추천했고, 이를 통해 높은 전환율을 이끌어냈습니다.
단, 해당 메시지는 수신 동의한 고객에게만 발송 가능했기 때문에 모수 확보도 필수 과제였습니다.
이에 따라 “아이의 생일은 언제인가요?”와 같은 참여형 캠페인을 기획하여 수신 동의를 유도하고 메시지 도달률을 높였습니다.

✅ 2회차 구매 유도 전략
- 첫 구매 제품을 기반으로 한 이미지 개인화 인앱 메시지
- 고객의 반응 시점에 맞춘 Push 메시지 발송
이러한 전략을 통해 고객의 다음 구매를 자연스럽게 유도하고, 리텐션을 강화할 수 있었습니다.

목표 2: 행동 기반 상품 추천 & ARPU 증대
- “무료배송까지 얼마 남지 않았어요” 인앱 메시지
- Best 간식 상품 추천
- 일정 금액 이상 구매 시 혜택 제공
이러한 장바구니 기반 혜택 전략을 통해 평균 객단가(AOV)가 목표 이상을 기록하며 높은 캠페인 성과를 달성했습니다.

💡 마티니가 전하는 F&B CRM 실전 인사이트
Insight 1. 개발이 어렵다면 CRM 기능만으로 대체 구현할 수 있는 방법을 먼저 고민해보세요.
Insight 2. 이미 기획된 캠페인도 지속적인 디벨롭이 필요합니다.
Insight 3. 완전히 새로운 혜택이 아니어도 괜찮습니다. 기존 혜택을 적절히 노출만 해도 충분히 업셀링이 가능합니다.
CRM은 마티니와 함께
마티니는 CRM, 그로스, 퍼포먼스 분야의 전문가들이 모여 유기적으로 협업하며 다양한 문제를 하고 있습니다.
마티니의 Braze 체크리스트와 F&B 전략 내용이 흥미로우셨다면, 마티니를 만나보세요. 👉 마티니 만나보기
데이터·프로덕트 분석, KPI 대시보드 설계와 제작, 데이터 파이프라인 활용, CRM 택소노미(Taxonomy) 및 프로모션 설계, MMP 설치와 점검, 퍼포먼스 마케팅 미디어 믹스까지, 각 분야의 전문가들이 모여있는 Martinee와 함께 비즈니스 성공을 실현해보세요.

CRM 마케터라면 알아야 할 4가지 필수 프로그램
CRM 마케터의 업무는 캠페인 기획부터 메시지 발송, 성과 분석까지 폭넓게 이루어집니다.
따라서 업무를 효율적으로 진행해야 하는데요, 이때 활용하기 적절한 4가지 필수 업무 툴을 소개합니다.
CRM 마케터의 필수 프로그램
- Whimsical
- Chat GPT
- VSC
- Tableau Prep
Whimsical
캠페인 기획 및 시각화
윔지컬(Whimsical)은 마인드맵, 플로우차트 등 시각적 도식화를 쉽게 만드는 화이트 보드 프로그램입니다.
CRM 캠페인을 진행하기 위해서는 목표 달성을 위해 어떤 타겟에게 언제, 어떤 메시지를 발송할지 계획하는 기획 단계가 필요한데요. 윔지컬은 캠페인 기획 시 활용하기 좋은 프로그램이죠.
1.캠페인 도식
캠페인 기획에는 타겟/발송시점/메시지 채널/문구 등 다양한 요소가 필요합니다.
윔지컬을 활용하면 색상과 도형으로 요소를 구분해 직관적인 캠페인 도식을 만들 수 있습니다.

예를 들어 왼쪽 캠페인 도식에서는 [타겟]은 ‘초록색 사각형’, [발송 시점]은 ‘파란색 마름모’, [메시지 채널]은 ‘노란색 사각형’으로 구분했습니다. 오른쪽 캔버스 도식에서는 간단하게 도형의 형태만으 각 step을 구분하고 있습니다.
캠페인 기획안을 텍스트만으로 정리하는 것보다, 도식화하는 것이 더 한눈에 이해하기 쉬워 캠페인 기획 관련 커뮤니케이션이 더 원활해집니다.
2. 개발 로직 설명
CRM 마케터는 생각보다 개발팀과 협업할 일이 많습니다. 이처럼 서로 업무 이해도가 낮은 타 부서와 커뮤니케이션할 때 윔지컬로 시각화하면 오해를 줄이고 소통을 원활하게 할 수 있습니다. 커뮤니케이션에서 곤란했던 적이 있다면 한번 사용해보세요!

3. 자동화 CRM 로드맵
여러 캠페인을 운영하는 경우, 유저들이 앱/웹 내에서 어떤 시점에 어떤 메시지를 받게 되는지 정리하는 것이 중요합니다.
이는 윔지컬에 유저 Journey를 그려 CRM 캠페인을 한판에 정리할 수 있습니다.
X축은 유저 Journey, Y축은 캠페인 목표로 설정하여 캠페인을 적절한 위치에 그려보는 방법도 있고 유저 앱/웹 맵을 그려 캠페인을 정리하는 방법도 있습니다. 각자 적합한 방법을 택해서 그려보세요.


VSC
코드 작성 및 수정
VSC (Visual Studio Code)는 코드 작성과 미리보기 기능을 제공하는 코드 편집기입니다. Braze에서도 liquid, HTML, SQL 코드를 활용하면 더 정교한 고객 관리가 가능합니다. 이때 VSC를 적극 활용해볼 수 있죠.
1. liquid 코드 작성 및 Preview
liquid 코드로 세밀한 타겟팅 및 개인화 문구를 설정할 때, VSC에서 결과값 preview를 확인하며 정합성을 검증할 수 있습니다.

2. HTML 코드 작성 및 Preview
In app message 작성 시 HTML코드를 활용한다면 기본 템플릿 이상의 디자인과 기술을 구현해낼 수 있습니다. VSC를 사용하면 코드 구조를 쉽게 확인하고, 이미지 preview까지 볼 수 있습니다.

3. SQL 코드 작성
Braze에서는 Query Builder 내 SQL 분석을 해 캠페인 성과를 심화적으로 분석할 수 있습니다. Braze의 기본 입력 창은 좁아 긴 코드의 경우 가독성의 한계가 있으므로, VSC에서 SQL을 먼저 작성하고 검토하면 훨씬 편리해집니다.

Chat GPT
코드 및 문구 작성
요즘 AI 챗봇을 활용하지 않는 분야가 없죠. CRM 마케터도 ChatGPT를 적극 활용하고 있습니다.
1. 코드 작성 및 수정
바로 위 VSC 파트에서 CRM 마케터도 코드 작성 업무가 적지 않다는 점을 확인하셨을텐데요. 코드 작성 시 논리 검증 및 오류 수정을 ChatGPT에 맡길 수 있습니다. 특히 경우에 따라 코드 작성이 길어지고 어려울 때, ChatGPT에 요청하면 빠르게 해결책을 찾을 수 있습니다.
단, liquid와 HTML의 기본 개념을 알고 있어야 ChatGPT를 더욱 효과적으로 활용할 수 있습니다. 기초 지식을 기반으로 원하는 바를 명확하게 질문해야 AI의 도움을 더 정확하게 받을 수 있죠.
이 점을 꼭 유의하세요!

2. 문구 작성
많은 분들이 잘 아시다시피 캠페인마다 메시지 문구를 작성해야 합니다. Chat GPT를 활용한다면 Push, IAM, LMS, 카카오톡 메시지 채널에 맞는 짧고 강렬한 문구를 빠르게 생성할 수 있습니다. 이것과 관련된 방법은 이전 글인 생성형 AI 조련법을 참고해보세요.
Tableau Prep
데이터 가공 및 병합
마지막으로는 Tableau Prep이 있습니다. Tableau Prep은 데이터를 결합·변형·정리해주는 데이터 가공 툴입니다.
캠페인 발송까지 완료했다면 이제 성과를 분석해야 하는데요. 이를 Tableau Prep으로 간단히 진행할 수 있습니다.
예를 들어 Braze에서는 Canvas와 Campaign의 report csv 파일을 다른 컬럼 구성으로 별도로 제공하고 있습니다. Campaign과 Canvas를 하나의 시트로 통합하여 관리하기 위해 Tableau Prep를 활용하여 불필요한 컬럼을 제거하고 필드명을 통일하여 두 파일을 병합할 수 있습니다.

이처럼 캠페인 기획부터 세팅, 분석 시 활용하는 Whimsical, VSC, Chat GPT, Tableau Prep을 소개해드렸습니다.
CRM 마케팅에는 다양한 업무가 요구되는 만큼 효율적으로 소화하는 것도 중요해지는데요,
이번에 소개한 프로그램을 실무에 적극 활용해보세요!

[종료] 그로스 캠프 4기 OPEN


















안내사항
- 참가 인원이 한정되어 있어 별도 참석 확정 연락을 드릴 예정입니다.
- 실습이 포함된 교육으로 개인 노트북 지참이 필요합니다.
- 주차권 제공 가능하며 리셉션 데스크로 문의 부탁드립니다.
- 참석자분들에게 간단한 음식이 제공될 예정입니다.
강의 취소/환불 규정
1. 취소/환불 규정
강의 당일 기준 1일 전까지 취소/환불 신청 시 100% 취소/환불이 가능합니다.
구매자가 단순 변심 등 본인의 사정으로 인해 환불을 신청할 경우에도 강의 1일 전까지 취소/환불이 가능합니다.
강의 당일(0시 기준)에는 취소/환불이 불가능합니다.
패키지의 경우 구매자가 이후 강의를 수강하지 아니하여도 결제 PG사 환불 규정에 따라 부분 및 일부 금액 환불이 불가능합니다.
패키지 부분 환불을 요청하는 구매자의 경우 다음 마티니 부트캠프 무료 수강권을 제공해드립니다.
2. 취소/환불 수수료
결제수단에 따라 환불 수수료가 부과될 수 있습니다.
취소/환불 수수료는 결제수단에 따라 다르게 적용 및 공제됩니다.
결제수단, 환불 신청 시점에 따라 환불 방식은 결제취소 또는 환불신청으로 다를 수 있습니다.
취소/환불 수수료는 결제수단에 따라 다르게 적용 및 공제됩니다.
취소/환불 수수료 공제에 대한 세금계산서 또는 현금영수증을 희망하는 경우 고객센터로 문의 바랍니다.
3. 취소/환불 방식
신용카드 환불의 경우 결제 PG사에서의 환불 처리가 완료되고 카드사를 통해 결제 승인이 취소되면 환불이 완료됩니다.
결제 당일 이후 결제 취소 시 카드사를 통한 결제 승인 취소 확인은 3~7일 가량 소요될 수 있으며, 이는 카드사 마다 다를 수 있습니다.
(시행일) 본 약관은 2024 년 03월 26일 부터 시행됩니다.
Contact
마티니와 함께 데이터 분석 기반의 그로스 마케팅을 경험해보세요!

CRM 마케터를 위한 생성형 AI 조련법

사실 나는 카피 작성에 소질이 없다. 인턴 시절, 소재 기획이 가장 어려운 업무였다.
그런데 CRM 마케팅도 소재 기획과 카피 작성이 포함되지 않나?
맞다. 하지만 콘텐츠 마케팅에 비하면 상대적으로 중요도가 조금 낮은 것 같다.
카피도 중요하지만, 유저 여정에서 적절한 시점에 넛지하는 것이 더 핵심이라고 생각한다. 이 부분이 흥미로워 CRM 마케팅을 선택했지만, 새로운 캠페인의 푸시 이미지와 문구를 기획하고, LMF 테스트를 위해 여러 버전의 푸시 문구를 작성하는 등 크리에이티브 작업은 끝이 없다.
카피를 잘 못 쓰는데 카피 작성을 어떻게 할 수 있을까?
생성형 AI를 활용하면 가능하다.
물론 생성형 AI가 100% 만족스러운 결과를 제공하는 것은 아니다. 어딘가 부족한 느낌이 들거나, 아무리 상세히 설명해도 내가 원하는 뉘앙스가 아닌 엉뚱한 답변을 주는 경우가 많다. 그럼에도 불구하고, 카피 작성이 어려운 나 같은 CRM 마케터들에게 도움이 되길 바라며, 생성형 AI를 효과적으로 활용하는 방법을 공유하고자 한다.
1. 서비스 학습시키기
가장 먼저 해야 할 일은 내가 담당하는 서비스에 대한 정보를 생성형 AI에게 학습시키는 것이다.
"새 옷 살 건데 추천 좀 해주세요!"라고 옆자리 동료가 말을 걸어왔을 때, 스타일이나 TPO를 모르면 적절한 추천을 해주기 어려운 것처럼, AI도 마찬가지다.
예를 들어, "패션 커머스의 푸시 카피 작성해 줘!"라고만 요청하면, 서비스 톤 앤 매너와 맞지 않는 문구나 지나치게 일반적인 표현이 나올 수 있다.
원하는 결과물을 얻기 위해서는 AI에게 서비스의 핵심 정보와 스타일을 충분히 제공해야 한다.
먼저 서비스의 특징과 톤 앤 매너를 AI에게 학습시킨다.
서비스 소개서/설명서가 있는 경우 해당 문서를 업로드해도 좋고, 서비스 페이지의 화면을 캡쳐하거나 앱스토어/플레이스토어에 업로드된 앱 디스크립션 및 앱 스크린샷을 활용할 수도 있다.

이전에 CRM 캠페인을 진행한 적이 있다면, AI에게 문구 및 성과를 전달하는 것도 큰 도움이 된다.
과거 성과가 좋았던 카피와 그렇지 않은 카피를 구분하여 제공하면 AI가 유저들의 특성까지 고려하여 문구를 작성해 줄 수 있다.
추가로, 아래와 같이 지양해야 하는 표현들과 유저 호칭 사용 시 주의점도 이 단계에서 미리 설명하면 좋다.
절대 사용하면 안 되는 표현들 : 할인율을 직접 표기하면 안 된다거나, 브랜드명은 제외하고 상품명만 노출시켜야 한다는 등의 가이드라인을 명확하게 제공해야 한다.
유저 호칭에 대한 주의사항 : "{{name}}님"이 아니라 "{{name}} 고객님", "{{name}} 사장님" 등으로 표현해야 하는 경우 AI가 이를 혼동하지 않도록 안내해주어야 한다.
2. 프롬프트 작성 & 카피 뽑아내기
서비스를 잘 학습시켰다면, 이제 카피를 뽑아내기 위한 프롬프트를 작성해 보자.
AI에게 원하는 결과를 얻기 위해서는 명확하고 구체적인 프롬프트를 작성해야 한다.
단순히 "푸시 카피 작성해 줘"라고 요청하는 것이 아니라, 다음과 같은 요소를 포함하면 보다 원하는 결과에 가까운 응답을 받을 수 있다.
1. 캠페인 목적
2. 발송 채널
3. 발송 타겟
4. 소구점 및 유의사항
5. 추가 요청사항
.png)
위의 예시와 같이 추가 요청사항에 별다른 말이 없는 경우, 문구를 1개만 작성해 준다.
여러 문구를 작성하게끔 시키고 그중에서 마음에 드는 문구만 골라 사용하고 싶다면, 추가 요청사항에 N개의 예시를 작성해 달라고 기재하는 것을 잊지 말자!
.png)
3. 여러 생성형 AI 사용하기
예시로 ChatGPT를 사용하였지만, 이 외에도 다양한 생성형 AI가 있다.
사용하던 AI에서 원하는 답변을 얻지 못하였다면 다른 생성형 AI를 사용하는 것도 하나의 방법이다.
생성형 AI마다 특징이 조금씩 다르기에, 동일한 내용을 학습시키고 프롬프트를 작성해도 답변은 다르게 출력된다.
.png)
Claude에서 1-2단계 ChatGPT와 동일한 자료로 AI를 학습시키고, 동일한 프롬프트를 사용해 출력한 결과이다. (GPT보다는 조금 더 우리가 많이 접한 푸시 문구와 비슷하지 않은가?)
위와 같이 여러 AI마다 스타일이 조금씩 다르기에, 결과물을 비교하며 원하는 요소들을 조합하면 더욱 효과적인 카피를 작성할 수 있다.
cf) 생성형 AI별 특징
ChatGPT : 문맥 이해도가 높고 자연스러운 카피를 생성하는 데 강점이 있음.
Gemini : 보다 창의적인 표현을 만들어내는 데 유리함.
Claude : 세부적인 조정이 가능하고 브랜드 톤 앤 매너 반영이 뛰어남.
소제목에도 쓰여있듯이 완벽하지는 않지만, 위와 같이 생성형 AI를 조련하면 카피 작성에 들어가는 리소스를 대폭 줄일 수 있다.
그렇다고 너무 의존하지는 말고, AI를 보조 도구로 활용하며 여러 레퍼런스를 수집하고 분석해야 한다.
필자의 경우, 도메인에 관련 없이 거의 모든 앱의 Push를 수신하며 인상적인 캠페인이 있으면 캡쳐를 꼭 해두고 있다. 아이디어가 필요할 때 스크린샷 폴더에서 레퍼런스를 찾아보는 것도 매우 큰 도움이 되기에 CRM 마케터라면 알림창이 Push로 가득차겠지만 꼭 수신동의를 해두자!
이 글이 AI를 효과적으로 조련하고, 효율적으로 CRM 카피를 작성하는 데에 도움이 되기를!
*글의 원문은 최영아님의 브런치스토리 에서도 읽어보실 수 있습니다.

나에게 가장 적합한 CRM 솔루션은 무엇일까?
CRM 자동화 솔루션, 뭐가 이렇게 많아?
지난 수 년간 CRM 마케팅이 디지털 마케팅의 주요 패러다임으로 자리 잡으면서, 해외의 CRM 자동화 솔루션들이 한국 시장에 진출했다. 또, 국내의 여러 CRM 자동화 솔루션들이 등장하여 적극적인 마케팅 활동을 펼치고 있다.
CRM 자동화 솔루션은 마테크 시장에서 점점 포화 상태에 이르고 있으며, 그만큼 솔루션을 구매해야 하는 마케터나 의사결정권자들의 결정도 어려워지고 있다.
이번 글에서는 CRM 솔루션들을 비교해보고, 우리 회사에 가장 적합한 CRM 솔루션을 찾기 위한 고려사항들을 이야기하려 한다.
[참고]
이 글은 아래의 CRM 자동화 솔루션들을 대상으로 합니다.
- 브레이즈 (Braze)
- 원시그널 (OneSignal)
- 인사이더 (Insider)
- 아이쿠아 (AIQUA)
CRM 자동화 솔루션을 선택할 때 고려해야 할 점
1. 서비스 특성
첫 번째 고려사항은 내가 일하고 있는 자사 서비스의 특성이다.
비슷해보이는 CRM 툴들 사이에서도 다른 특성들이 있으며, 각 특성들이 우리 서비스의 특성과 얼마나 어울리는지 살펴봐야 한다.
판매하는 프로덕트의 관여도, 타겟 유저의 특성, 상품의 수량, 수익 모델, 매출을 내는 유저의 비중, 재구매율을 비롯한 주요 지표들이 서비스 특성에 포함될 수 있다.
예시1) 고관여 vs 저관여
고관여 제품은 유저 설득에 시간이 오래 걸리고, 설득을 위해 보내야 하는 메시지도 많다.
반면 저관여 제품을 유저 설득에 시간이 상대적으로 적게 소요되지만, 그 짧은 시간안에 설득해내야 한다는 다른 유형의 챌린지가 있다.
고관여 제품
• 정보성 메시지
가격이 비싼 만큼 유저들은 자신의 결정이 가질 리스크를 낮추려 한다. 정보성 메시지를 통해 이런 리스크를 낮추는 것 만으로도 구매전환율을 높일 수 있다.
• 높은 수준의 개인화
높은 수준의 개인화를 통해 본인이 고려하고 있는 제품을 반복적으로 노출시켜야 한다. 소셜프루프, 가격 변동 정보 등을 활용하여 유저로 하여금 "구매하는 것이 올바른 선택인 것 같은 느낌"을 주어야 한다.
• 긴 고객 여정에 적합한 단계별 메시지
구매에 오랜 시간이 걸리는 만큼, CRM으로 터치할 시간도 많이 주어진다. 다양한 채널과 메시지를 활용하여 유저에게 단계별 메시지를 발송하여 전환율을 높일 수 있다.

저관여 제품
• 꾸준한 쿠폰 플레이, 할인 등 프로모션
값이 저렴한 저관여 제품일수록 유저들이 오히려 가격에 더 민감하게 반응한다. 가전은 비싸도 좋은 걸 사서 오래쓰고자 하지만, 물이나 휴지는 그렇지 않다. 가격 경쟁력을 갖추기 위한 쿠폰 플레이와 할인을 꾸준히 진행해야 한다.
•프로모션 참여 유도: 게이미피케이션
"꾸준한 프로모션"을 진행하다보니, 프로모션을 진행해도 유저들의 참여율이 낮아질 때가 있다. 이 경우 게이미피케이션이나 프로모션의 한정성을 강조하여 프로모션의 참여율을 높여야 한다.
• 크로스세일
저관여 제품은 상대적으로 크로스세일이 용이하다. 마트 계산대에 껌이나 캔디 같은 제품이 놓여 있는 이유이기도 하다. 짧은 구매여정 속에서도 크로스세일을 유도하여 구매당 단가를 높일 수 있다.


예시2) 상품의 수, 고객의 수
상품이 많을 수록, 고객의 수가 많을 수록 할 수 있는 CRM 시나리오의 종류도 다양해지는 편이다.
상품이 많다면 여러 상품별 구매 데이터를 활용한 AI 상품추천(Recommendation), 크로스세일이 더욱 힘을 받는다. 상품이 많으니 카테고리, 브랜드 등의 부가적인 데이터도 활용하기 용이하며, 데이터가 많으니 기능의 성능도 올라간다.
고객이 많다면 유저 세그멘테이션(User Segmentation)이나 유저 클러스터링(User Clustering)을 적극적으로 활용할 수 있다. 유저가 많은만큼 유저 집단별 특성을 명확하게 확인할 수 있다.
반대의 경우엔 위와 같은 부가 기능들의 중요도가 상대적으로 떨어진다.
상품 추천 로직을 만들었는데, 추천하는 상품이 다 똑같은 상품들일 수 있고, 유저 세그멘테이션을 진행했는데 세그먼트 당 유저 모수가 몇 명 되지 않을 수도 있다.
상품의 수, 고객의 수가 많지 않다면 위와 같은 마케팅 전략들의 영향력이 줄어든다. 그리고 쿠폰, 혜택 등의 프로모션이 CRM 성과에 기여하는 비중이 커진다.
CRM 자동화 솔루션들이 프로모션을 짜주지는 않으니, 상대적으로 가벼운 솔루션을 찾는 것이 가성비를 높이는 것도 방법일 수 있다.
예시3) BM
BM에 따라서도 취할 수 있는 전략이 달라진다.
여러 브랜드의 제품을 파는 이커머스 플랫폼의 경우, 플랫폼보다 내가 판매하는 '브랜드'의 충성도에 의해 서비스를 이용할 가능성이 크다.
극단적인 예시가 플랫폼과 나이키의 관계다. 대부분의 플랫폼에서 나이키 제품은 판매량 최상위권을 차지한다. 유저는 나이키를 살 건데, 여러 쇼핑몰을 찾아다니며 나이키를 제일 싸게 파는 곳을 찾을 뿐인 것이다.
(그래서 이런 브랜드들은 분석에서 제외하고 보기도 한다.)
이런 브랜드의 충성도를 활용하여, 메시지에 유저가 관심을 보인 브랜드를 개인화한다면 전환율을 높일 수 있다.

F&B의 경우 재구매가 용이하다. 가격이 저렴하기도하고, 업종 자체가 '먹는 것'이기 때문이다. 그러나 유저에겐 선택지가 너무 많다. 보편적인 재구매주기를 찾고, 재구매주기를 단축시키기 위한 메시지가 유효할 수 있다. 또, 주문 프로세스에서의 크로스세일 유도를 통해 판매액을 높일 수도 있다.
교육, 여행처럼 오랜 기간 지속되는 서비스를 제공하는 경우, 구매 이후의 유저 경험이 더욱 중요하다.
사실 이런 서비스는 고객이 니즈가 없으면 판매를 유도하기 어렵다. 유저는 영어를 배울 각오를 하고, 휴가를 내고 해외 여행을 갈 계획을 세워야지만 구매한다.
그래서 구매이후 이용/경험을 돕는 지속적인 메시지를 통해 유저에게 긍정적 구매 경험을 심어주어야 한다. 긍정적 경험을 통해 재구매 전환율을 높이는 것이다.

2. CRM 솔루션별 강점 파악

내가 처한 환경을 고려했으니, 이젠 각 솔루션별 특징을 확인해볼 차례다.
CRM 자동화 솔루션들은 CRM 메시지 자동화뿐만 아니라 성과를 높일 수 있는 다양한 기능들을 제공하고 있으며, 이런 기능들이 각 솔루션들에게 차이점을 준다.
브레이즈 (Braze)
Braze의 경우 강력한 개인화 기능을 가지고 있다. Liquid, Connected Content와 같은 높은 수준의 개인화를 사용할 수 있는 기능들이 있다. 그 밖에도 Canvas내 다양한 종류의 스텝들을 통해 유저와의 관계를 구축할 수 있으며, 범용적인 마테크 연동성, 다양한 AI 기능들도 장점으로 꼽을 수 있다.
기능들이 다양하고 파워풀한만큼, 실행할 수 있는 시나리오가 가장 많은 솔루션이 아닐까 싶다.
원시그널 (OneSignal)
OneSignal의 강점은 '가성비'라고 볼 수 있다. 기본 SDK설치에 10분이 채 걸리지 않는 가벼운 설치에 가격도 상대적으로 저렴한 편이며, 초심자가 사용하기에 난이도도 상대적으로 쉬운 편이다.
설치와 비용, 활용이 가볍다고 해서 기능이 부족한 것은 아니다. 개인화를 위한 Liquid를 제공하며, Braze의 Connected Content 기능과 유사한 Custom Data 기능도 있다.
CRM 마케팅이 익숙치 않거나, 서비스 특성상 진행할 수 있는 CRM 시나리오가 명확한 경우 적합하다.
인사이더 (Insider)
Insider는 웹 환경에서의 '높은 자유도'와 '상품추천'이 강점이다. 앱 내 웹뷰 영역도 포함이다.
웹 환경에서 다양한 배너, 소셜프루프, 게이미피케이션, 인브라우저 메시지 등을 사용할 수 있다. 템플릿도 굉장히 다양해서 노코드로 여러 CRM 시나리오를 구현할 수 있다.
자사 서비스에 웹 영역의 중요도가 높고, 커스터마이징의 자유도를 원한다면 좋은 선택지가 될 수 있다.
아이쿠아 (AIQUA)
AIQUA는 AI에 강점이 있다. AI를 개발한 애피어(Appier)는 자신들을 'AI 회사'라고 칭할 정도로 AI에 많은 투자를 하고 자신이 있다. AI를 활용한 카피라이팅, 상품추천, 이탈/구매 예측, 타겟팅뿐만 아니라, CRM 시나리오 제작까지 가능하다.
CRM 솔루션의 기본적인 기능들과 더불어, AI를 활용해 CRM 마케팅 효율을 강화하고 싶은 경우 적합하다.
3. 그 밖에 참고하면 좋을 사항들
그 밖에도 아래의 사항들을 함께 참고해보면 좋다.
• 타 솔루션과의 연동성
Product Analytics, MMP 등 다양한 마테크 솔루션과의 CRM 솔루션을 연계 활용하고자 한다면, 내가 사용하는 마테크 솔루션들과의 연동이 지원되는지 살펴보면 좋다.

• 고객지원 / 기술지원
처음부터 마테크 솔루션들의 기능을 100% 활용하기는 매우 어려운 일이다.
내가 원하는 수준의 고객지원 / 기술지원을 받을 수 있는지 체크해보아야 한다.
* 보통 마테크는 고객지원과 기술지원이 따로 구성되어 있다.
• 컨설팅, 대행 등의 도움을 받을 수 있는지
CRM 시나리오를 구현하고, 마케팅 목표를 달성하기엔 마테크 솔루션들의 지원 만으로는 부족할 수 있다. 솔루션 사용을 돕지만, 비즈니스 성장을 위한 마케팅을 지원하진 못하기 때문이다.
어떠한 형태든 마케팅에 어려움을 겪고 있다면, 비즈니스를 성공시키는 마케팅을 위한 컨설팅 / 대행 서비스를 통해 도움을 받는 것이 좋다.
마티니(Martinee)에서는 이 글에서 언급된 모든 솔루션들의 컨설팅 / 대행 서비스를 제공한다.
가성비를 결정하는 것은 파일럿
다들 알다시피 가성비는 가격대비 '성능'의 비율을 의미한다.
가격은 솔루션 가격을 의미할 것이고, '성능'은 무엇을 기준으로 판단해야할까?
앞서 설명한 솔루션별 기능과 장점들도 성능에 포함되지만, 솔루션을 사용하는 사용자의 영향이 더 크다고 본다.
결국 성능을 결정하는 가장 큰 요인은 파일럿인 것이다.

많은 회사들과의 미팅, 컨설팅을 통해 솔루션 없이도 높은 수준의 CRM을 실행하는 곳도 발견한 반면, 그냥 CRM 솔루션으로 무분별한 메시지만 발송하는, 소위 '앱푸시 발사대'로만 사용하는 경우도 많이 보았다.
자신의 도메인에 적합한 솔루션을 선택하고, CRM 마케팅을 꾸준히 개선시키고 학습하는 마케터가 CRM 마케팅 솔루션의 가성비를 결정하는 키를 쥐고 있다.

[Review] 브레이즈 자동화 & 데이터 분석 활용 마스터 클래스
마티니와 Braze 자동화 정복하기


마티니만의 Braze 활용 노하우를 알려드리는 올해 마지막 Braze Master Class가 12월 12일 (월) 오후 7시 마제스타시티 타워2 마티니 오피스에서 진행되었습니다.
이전 클래스에서 개인화 기능 활용법을 알려드렸다면 이번에는 자동화 캠페인을 구축하는 방법과 Braze 데이터를 분석하고 활용하는 방법들을 공유해드렸습니다.
어떤 것들을 배웠나요?
ROI를 높이는 자동화 캠페인




CRM 캠페인을 자동화 하면 효율적인 비용과 리소스 활용이 가능합니다. 자동화 캠페인을 구축하지 않으면, 캠페인 성과 개선 기회 또한 놓칠 수 있습니다.
자동화 했을 때, 그렇지 않을 때보다 Opt-in, 구매 전환 등의 성과가 크게 차이나기에 CRM 마케터라면 반드시 구축해야 하는 중요한 과정입니다.
Braze로 자동화 캠페인을 구축하는 프로세스는 다음과 같습니다.
[캠페인 아이데이션 → 기술 검토 → 상세 기획 → 기술 구현 → 세팅 → QA → 런칭]
캠페인 아이데이션을 완료하면 바로 구현 가능한지 이벤트 택소노미나 API 및 기타 개발사항을 검토합니다.
예를 들어 유저가 장바구니에 담은 상품의 가격 하락 알림을 보낸다면, 유저가 장바구니에 담은 item_brand가 Event Property로 수집되어 있는지 점검해야 합니다. 또 Connected Content & Liquid를 통해 현재 가격과 하락 금액을 계산해야 합니다.
모든 점검이 완료되면 트리거, 액션, 메시지의 상세한 내용과 함께 도식화하여 아이디어를 구체화합니다. 이후 기술 구현 단계에서 미발송 및 오발송 케이스는 없을지 확인하면 세팅 준비가 완료됩니다.
*기술 구현 단계에서 개인화를 진행합니다.
세팅 단계에서는 타겟, 트리거 등의 조건을 다시 확인하고 테스트 하며 이슈가 없는지 체크합니다. 당일 행사에서는 런칭 이후 캠페인 관리를 위한 노하우까지 공유드렸습니다.
Braze 데이터, 이렇게 분석해요


캠페인 성과를 측정할 때 아래 Braze의 Analytics 기능을 잘 활용하면 CRM 캠페인으로만 얻은 순수 수익(전환)을 확인 할 수 있습니다.
- Repert Builder : 빠르게 성과를 확인하기 위해 활용하고 주로 모니터링 목적으로 활용합니다.
- Engagement Report : 데이터를 추출하고 가공하기 적합하며 시트나 시각화 솔루션에서 데이터를 가공하고 활용할 때 유용합니다.
- Query Builder : 쿼리를 활용하기 때문에 상세한 데이터 분석이 가능하고 기본 리포트에서 확인할 수 없는 상세항목을 확인하기 유용합니다.
분석은 CRM 캠페인 런칭 전후인 선행 분석과 후행 분석으로 나뉩니다.
선행적 분석은 재구매 주기, 회원가입, 첫구매까지 소요시간 그리고 연관 구매 등의 상황에서 진행하고 후행적 분석은 증분분석으로 캠페인 순수 성과를 확인할 때 진행합니다.
세션에서 각 분석의 적용 예시와 함께 설명드렸습니다.
Braze의 Currents를 활용할 경우, PA 솔루션과 연동하여 대시보드화 하거나 DW를 활용한 상세 분석 등 더욱 디테일하게 분석이 가능합니다.
개발 문제 없이 Braze 활용하기


CRM 캠페인을 기획하고 라이브 하다 보면 개발 문제가 생기기 마련입니다. 개발이 필요한 항목인데, 리소스가 없어서 개발이 지연되고 그로 인해 캠페인 라이브도 지연되는 경우가 가장 대표적인 예시입니다.
Braze의 Liquid, Connected Content, Webhook, Query Builder, Catalog와 같은 기능을 잘 활용하면 기존의 개발 이슈로 인한 한계들을 보완할 수 있습니다.
이번 세션에서는 개발자의 도움 없이 데이터를 수집하는 방법, 소셜프루프 등 별도 API 개발이 필요한 항목을 Braze만으로 구현하는 방법, Recommendation을 활용하는 방법 등을 설명드렸습니다.
고민이 있을 땐 CRM 커뮤니티에서!
세션 이후 Braze 활용 관련 질의응답 시간에 API 캠페인과 Attribution 관련 질문을 해주셨는데요.
이처럼 Braze 활용 관련해서 캠페인을 준비하거나 진행하면서 생기는 고민 및 문제점들을 언제든지 편하게 질문하고 소통할 수 있는 CRM 커뮤니티에 여러분을 초대합니다!
Braze뿐만 아니라 CRM 마케팅을 하면서 생기는 이슈들을 공유하고 어려운 부분을 해소해드리고자 마련하였으니 많은 참여 바랍니다.
👉지금 바로 신청하기!
2024년을 마무리하며..
마티니와 Braze는 2023년부터 Braze 활용에서의 어려움을 해결해드리고자 Braze 활용법을 공유해드리는 교육 세미나를 진행해왔습니다.
올해는 네 번의 Braze Master Class를 진행했고, 컬리, 홈플러스, 올리브영, 동원, 오늘의집 등 주요 기업에서 온 200여명의 참석자분들이 행사에 참석신청해주셨습니다.
적극적으로 세션에 참석해주신 모든 분들께 감사의 말씀 드립니다.
내년에도 Braze 솔루션 파트너사 마티니가 여러분들께 어디에서도 얻을 수 없는 Braze 활용 교육을 전달해드릴 예정이니, 많은 관심과 참여 부탁드립니다.

Braze, 100% 활용하고 있을까?
CRM 마케팅이 중요해지면서 많은 기업들이 Braze를 도입하고 있다.
대부분 앱 푸시 발송과 개인화 마케팅을 위해 Braze를 사용하지만, 다양한 기능을 활용해 마케팅을 고도화하는 경우는 많지 않다.
아직 Braze 관련 학습 자료나 강의가 부족해 공식 문서에만 의존해야 하다 보니, 많은 마케터들이 Braze의 기능을 제대로 활용하지 못하고 있다.
이 글에서는 Braze를 제대로 활용하고 있는지 점검하고, 놓치고 있는 유용한 기능들을 소개하려 한다.
브레이즈 기본 기능만 사용하고 있는 건 아닐까?
아래 Braze 용어 중 내가 사용한 적이 있거나, 사용하지 않았더라도 들어본 용어가 있는지 확인해 보자.
(Braze 이용자라면 누구나 사용하는, 꼭 알아야 하는 기능은 빼두었다.)
- Frequency Capping
- Segment Extension
- Spacer
- Connected Content
- Query Builder
3개 이상 사용해 봤다면 Braze를 잘 활용하고 있는 셈이다.
하나도 사용해 보지 않았더라도 걱정하지 말자. 지금부터 각 기능의 활용법을 자세히 설명할 예정이다.
브레이즈 100% 활용하기
1. Frequency Cappping
Frequency Cappping이란 사용자가 받는 메시지 수를 제한해 피로감을 줄여주는 기능이다.
설정 예시
- 하루 최대 3개까지만 앱 푸시 발송
- 3일 동안 웹훅 최대 10개로 제한

위와 같이 채널별로 기간과 수신 횟수를 설정할 수 있고, Campaign이나 Canvas에 Tag를 추가하면 특정 캠페인에만 제한을 걸 수도 있다.
예를 들어 이벤트 태그가 있는 캠페인은 하루 1개만 발송하는 식이다.

"푸시가 너무 많이 와요", "인앱메시지가 자주 떠서 불편해요" 같은 VOC를 자주 받는다면 Frequency Capping을 적극 활용해보자. 사용자 경험도 개선하고 고객 만족도도 높일 수 있다.
2. Sement Extension
Braze에서 자주 쓰는 필터로 'X Custom Event Property In Y Days'와 'X Purchase Property In Y Days'가 있다. 실시간으로 반영된다는 장점이 있지만, 몇 가지 제한사항이 있다.
- 최대 30일까지만 조회 가능
- Data Point 차감
- 담당 CSM에게 필터 오픈을 요청해야 함
반면 Segment Extension은 아래와 같은 장점이 있다.
- 최대 2년(730일)까지 조회 가능
- Data Point 차감 없음
- 별도 요청 없이 바로 사용
예를 들어 일반 필터로는 '지난 30일간 패딩 구매자'만 찾을 수 있지만, Extension으로는 '지난 1년간 패딩 구매자' 세그먼트를 만들 수 있다.

단, Extension은 실시간 업데이트가 아닌 정해진 주기로 업데이트된다. 기존에는 매일 오전 12시마다 업데이트 되었는데, 최근 Weekly, Monthly 옵션이 추가됐다.

3. Spacer 활용하기
Webhook으로 카카오톡, 문자 메시지를 보내는 것 뿐만 아니라 빈 웹훅인 Spacer를 발송하여 A/B Test를 진행하거나, 성과를 측정하는 것도 가능하다.

Spacer 활용 사례
- A/B 테스트 정확도 높이기
- Canvas의 Control Variant는 Step을 추가할 수 없다는 한계가 있다. 이런 경우 일반 Variant에 Spacer를 넣어 대조군으로 활용하면 더 정확한 테스트가 가능하다.

- Attribute 변화 측정하기
- Braze는 기본적으로 Event의 Conversion만 측정 가능하다. 하지만 Spacer를 활용하면 Attribute 변화도 측정할 수 있다.
- 수신동의 전환율
- 브랜드 위시리스트 추가율
- 세팅 방법
- Attribute 값이 A로 변할 때 실행되는 Action Based 캠페인 생성
- 메시지 대신 Spacer 설정
- Target을 실 메시지 캠페인 수신자로 지정
- 이렇게 하면 Attribute가 변경될 때마다 Spacer가 발송되어 성과 측정이 가능하다.
- Braze는 기본적으로 Event의 Conversion만 측정 가능하다. 하지만 Spacer를 활용하면 Attribute 변화도 측정할 수 있다.
또한 잘못 설정된 Conversion 지표를 보완할 때도 유용하다.
4. Connected Content
Connected Content는 API를 통해 외부 데이터를 실시간으로 가져와 메시지에 활용하는 기능이다.
활용 가능한 데이터:
- Braze에 저장하지 않은 내부 데이터
- 보안상 민감한 정보
- 날씨, 환율 등 실시간 변동 데이터
이러한 데이터는 Braze에 저장되지 않아 보안성이 높고, 실시간 데이터로 더 정확한 개인화가 가능하다.
API Response 값을 메시지에 바로 사용하거나, Liquid 구문으로 메시지 발송 조건으로 활용할 수도 있다.
API 개발이 필요하지만, 활용하면 한층 더 다양한 개인화 메시지를 만들 수 있다.
Connected Content 사용 사례
1. Open API 활용 : 누구나 이용할 수 있는 Open API를 활용하여 다양한 캠페인을 진행할 수 있다.
- 날씨 API
- Braze에서 유저의 위치 정보를 수집하는 경우, 위•경도 정보로 유저가 위치한 곳의 날씨를 파악할 수 있다. 날씨는 물론 현재 온도, 체감 온도, 습도, 기압 등 다양한 기상 정보 확인이 가능하다.
- 글로벌 알람 앱 A사에서는 이러한 날씨 API를 활용하여 유저의 현재 날씨에 따라 메시지를 달리한 캠페인을 진행하였다.

- 공휴일 API
- 새해 첫날, 크리스마스와 같이 날짜가 고정되어 있는 공휴일은 Liquid를 통해 확인이 가능하지만 설, 추석 연휴처럼 매년 달라지는 공휴일은 매번 별도로 설정을 해주어야 한다.
- 공공데이터포털의 공휴일 API를 활용하면 공휴일 여부를 파악할 수 있으며, 이에 따라 메시지를 다르게 보내거나 미발송 처리를 할 수 있다.
2. 내부 API 활용 : 기개발된 API가 있다면 해당 API를 활용하여 다양한 캠페인 운영이 가능하다.
- 상품 재고 API
- 상품별 실시간 재고를 확인할 수 있는 API를 통해 상품 재고에 따른 메시지를 발송할 수 있다.
- 패션 커머스 W사에서는 구매 버튼 클릭 후 구매하지 않은 상품의 재고가 10개 미만으로 하락했을 때 품절 임박 메시지를 발송하였다.

- 상품 가격 API
- 상품별 현재 가격을 확인할 수 있는 API를 통해 특정 시점의 가격과 현재 가격을 비교할 수 있다.
- 패션 커머스 F사에서 장바구니/위시리스트 추가한 시점의 가격보다 현재 가격이 하락한 경우, 가격 인하 메시지를 발송하는 캠페인을 진행하였다.

- 쿠폰 정보 API
- 유저별 보유 쿠폰 정보를 확인할 수 있는 API를 통해 쿠폰 사용 유도 메시지를 발송할 수 있다.
- 패션 커머스 W사에서 유저가 사용하지 않은 쿠폰의 만료일이 1일 남은 경우, 쿠폰 만료 D-1 안내하는 자동화 캠페인을 운영하였다.
.png)
5. Query Builder
Query Builder는 SQL Query를 사용해 데이터를 출력하는 기능이다.
Campaign Analytics와 Engagement Report를 통해 캠페인 발송 수와 전환 수는 확인할 수 있지만, 유저가 어떤 상품을 구매했는지, 혹은 다른 이벤트가 발생했는지는 알 수 없다.
유저 행동을 더 자세히 분석하고 싶다면 쿼리빌더를 활용해보자. SQL에 익숙하다면 직접 쿼리를 작성할 수 있고, 그렇지 않다면 Query Template이나, AI Query Builder를 통해 쿼리를 생성하여 사용하면 된다.

Query Builder를 통해 N Day Retention과 같은 데이터도 확인할 수 있다.
N Day Retention 활용 사례 보러가기
어트리뷰트 데이터 테이블은 지원하지 않지만, 캠페인, 캔버스, 이벤트, 세션 정보 같은 유용한 데이터는 쉽게 추출할 수 있다. 다양한 분석을 원한다면 Query Builder를 적극 활용하자.
(단, Query Builder는 매월 사용할 수 있는 크레딧이 있으니, 쿼리 실행 시 크레딧이 줄어드는 점을 주의해야 한다!)
앞서 언급한 기능 외에도 Braze를 더 깊이 활용할 수 있는 방법은 많다.
실무로 바빠서 Braze를 자세히 살펴볼 시간이 없더라도, 틈틈이 다양한 기능을 활용해 보다 효율적이고 정교한 CRM 마케팅을 진행하길 바란다.
또한 기존 기능에 새로운 요소가 추가되거나 새로운 기능이 출시되니, 매월 업데이트되는 Braze Release Note를 확인하는 것을 추천한다.
*글의 원문은 최영아님의 브런치스토리 에서도 읽어보실 수 있습니다.
