
February 4, 2026

MCP(Model Context Protocol)는 AI가 외부 데이터를 활용할 수 있도록 연결해 주는 개방형 표준 프로토콜입니다. 쉽게 말해, AI 도구가 실시간으로 필요한 데이터를 가져와 활용할 수 있게 만드는 기술입니다.
앱스플라이어는 이 기술을 활용해 자연어만으로 마케팅 데이터에 바로 접근 가능한 MCP를 선보였습니다. Claude, ChatGPT 같은 AI 도구와 앱스플라이어를 연결하면, 캠페인 성과 분석부터 오디언스 관리, 딥링크 문제 해결까지 질문만으로 처리할 수 있습니다.
또한 앱스플라이어 MCP는 기술적 배경과 관계없이 누구나 필요한 데이터를 즉시 확인할 수 있도록 지원합니다. 사용자가 직접 질문하든, AI 에이전트에게 작업을 맡기든, 대기 시간 없이 명확한 정보와 실행 결과를 바로 받아볼 수 있습니다.
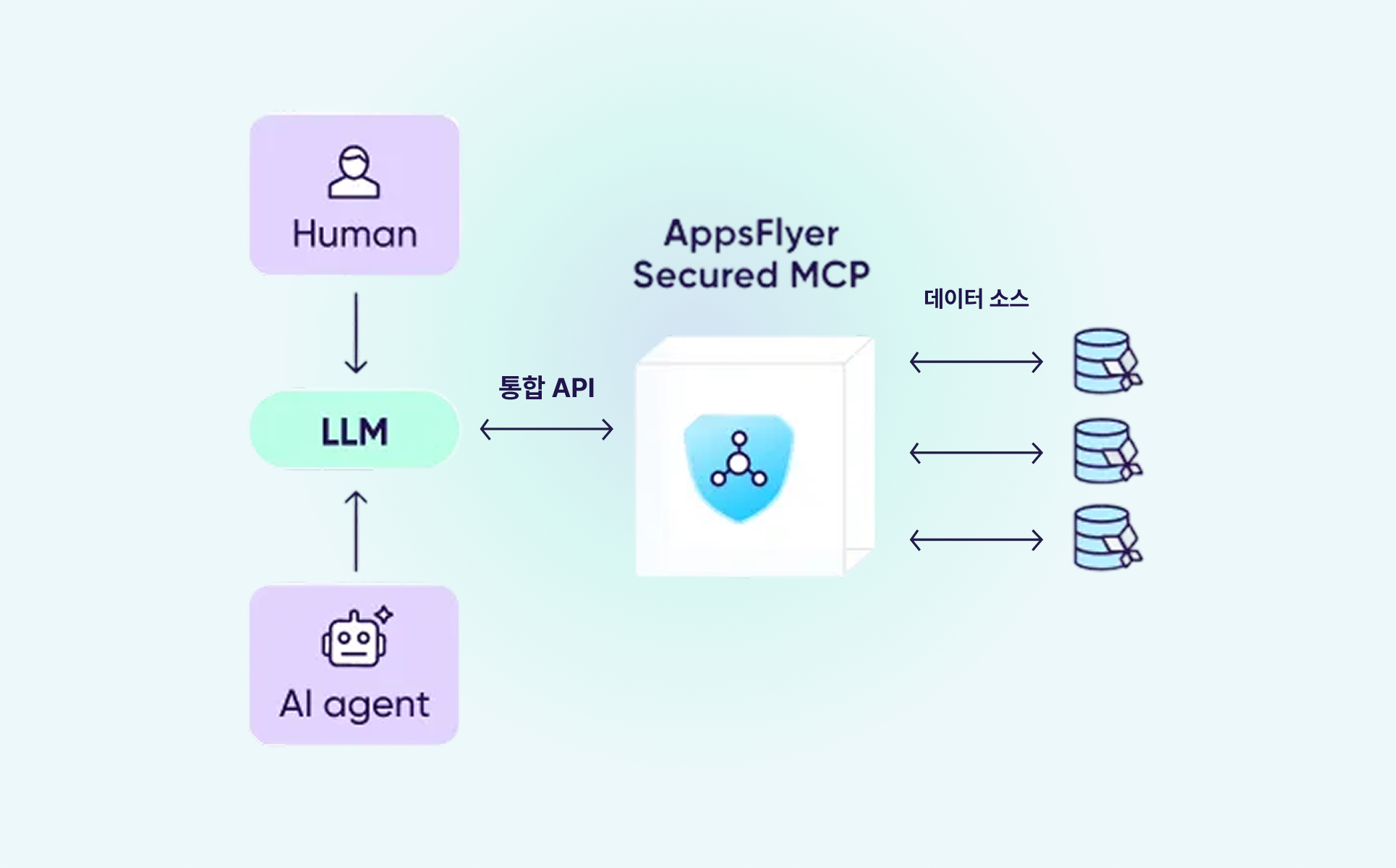
앱스플라이어 MCP는 Claude, ChatGPT, Gemini 같은 사용자가 선호하는 LLM(Large Language Model) 도구와 앱스플라이어를 연결합니다. 사용자가 질문을 입력하면 MCP가 자동으로 필요한 데이터를 찾아 이해하기 쉬운 형태로 보여줍니다. 어트리뷰션, 분석, 오디언스, OneLink(원링크) 등 앱스플라이어의 모든 기능을 자연어로 바로 활용할 수 있습니다.
또한 앱스플라이어는 7,000개 이상의 주요 브랜드가 신뢰하는 풍부하고 정확한 데이터를 제공하기 때문에 개인정보 보호를 철저히 준수하며 마케터가 필요한 인사이트를 즉시 확인하고 빠르게 의사결정을 내릴 수 있도록 돕습니다.
앱스플라이어 MCP는 개방형 구조로 설계되어 있어, 원하는 방식으로 커스터마이징할 수 있습니다. 미디어 믹스를 최적화하는 AI를 만들거나, 오디언스를 자동으로 관리하는 시스템을 구축하거나, 내부 도구에 MCP를 연결하는 등 복잡한 설정 없이도 필요한 기능을 유연하고 자유롭게 구현할 수 있습니다.
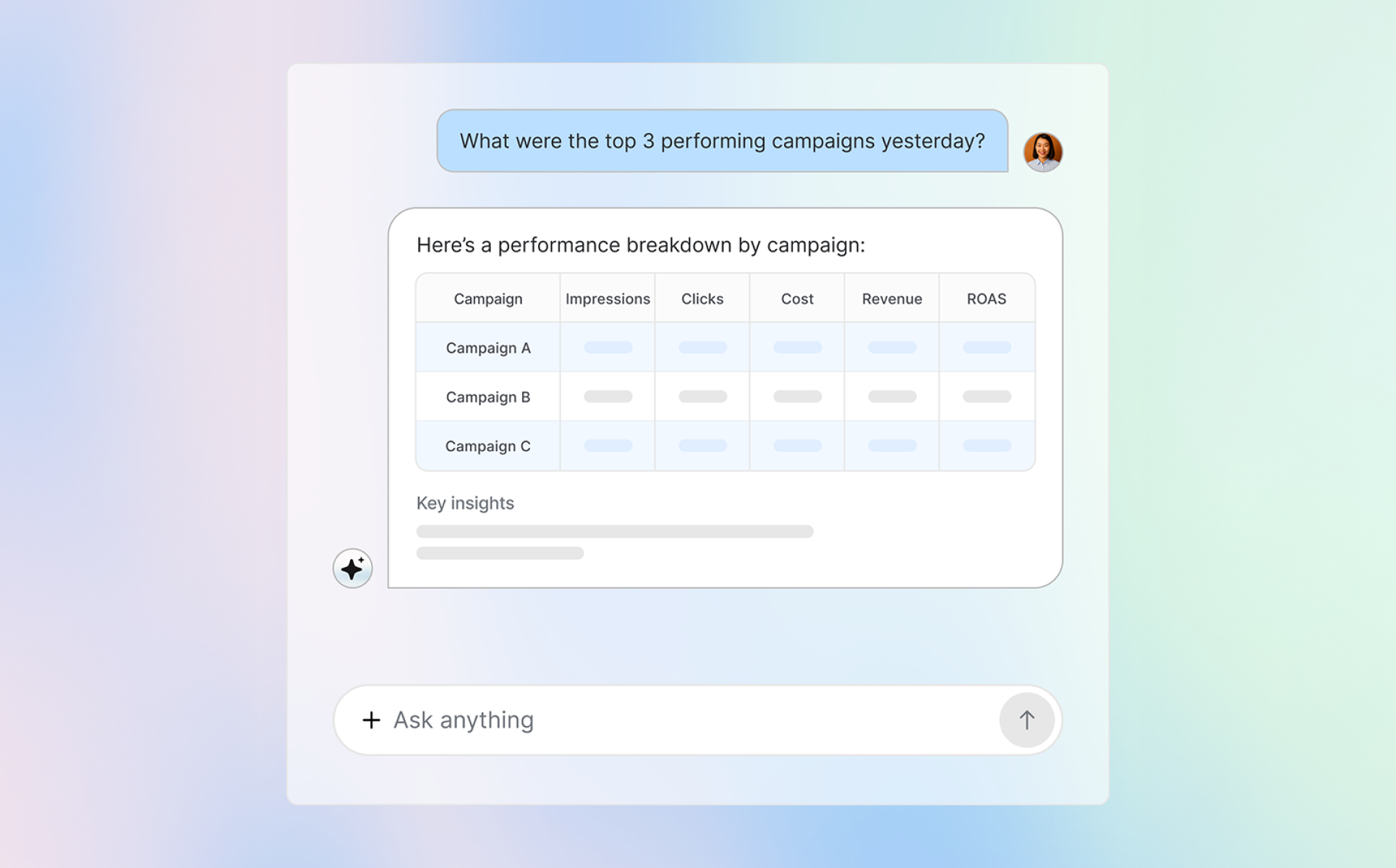
채널별 ROAS를 확인하고 싶거나, 어떤 캠페인이 가장 높은 LTV를 만드는지 알고 싶을 때 앱스플라이어 MCP를 활용해 보세요. 질문만 입력하면 필요한 데이터를 바로 확인할 수 있습니다.
앱스플라이어 MCP는 사람이 직접 질문하거나 AI 에이전트가 자동으로 작업하는 방식 모두 지원합니다. Growth, CRM, 제품, 마케팅 팀 등 어떤 팀이든 별도의 설정이나 개발 작업 없이 필요한 인사이트를 바로 확인할 수 있습니다.
앱스플라이어 MCP는 앱스플라이어의 어트리뷰션 기술을 기반으로 만들어졌습니다. 모든 데이터는 개인정보 보호 규정을 철저히 준수하며, 설계 단계부터 암호화와 보안을 적용했습니다.

캠페인 성과를 실시간으로 확인하고, ROI를 비교할 수 있습니다. 채팅창에서 직접 확인하거나, AI 에이전트를 활용해 성과 모니터링부터 최적화, 작업 실행까지 자동으로 처리하세요.
오디언스가 어떻게 나뉘고 활용되는지 한눈에 확인할 수 있습니다. 질문만으로 오디언스 현황을 조회하거나 실시간 성과를 분석할 수 있으며, 중복된 오디언스를 찾아내고 개선 방안을 제안하는 AI를 직접 만들 수도 있습니다. 필요하다면 여러 채널의 오디언스 정보를 자동으로 동기화하거나 작업을 실행할 수도 있습니다.
대화형 인터페이스로 OneLink 템플릿과 링크 동작을 간편하게 점검하거나, 에이전트를 활용해 링크 상태를 지속적으로 모니터링할 수 있습니다. 문제가 있는 링크를 자동으로 찾아내고, 모든 캠페인이 올바르게 운영되도록 관리할 수 있습니다.
앱 설정이나 구현 방법이 궁금할 때 질문만으로 바로 확인할 수 있습니다. AI 어시스턴트가 설정 오류를 찾아내 해결 방법을 알려주거나, 상황에 맞는 가이드 문서를 자동으로 보여줍니다.
앱스플라이어 MCP는 AI 기반 마케팅을 향한 중요한 첫걸음입니다. 사람의 창의성과 AI의 분석 능력이 결합되면, 마케터는 더 나은 의사결정을 내릴 수 있습니다.
MCP는 캠페인 분석, 오디언스 확인, 딥링크 관리 같은 마케터들의 핵심 업무를 지원하고 있으며, 추후 예측 분석과 에이전트 기반 자동화까지 확대 될 예정입니다. 데이터 기반으로 더 빠르고 정확한 의사결정을 내리고 싶다면, 지금 바로 앱스플라이어 MCP를 경험해 보세요.

|
앱스플라이어 도입을 고민중이라면?마티니는 앱스플라이어 도입부터 실무 활용까지 전 과정을 지원하는 풀퍼널 마케팅 에이전시입니다. 지금 아래 버튼을 눌러, 마티니와 만나보세요. |

January 9, 2026

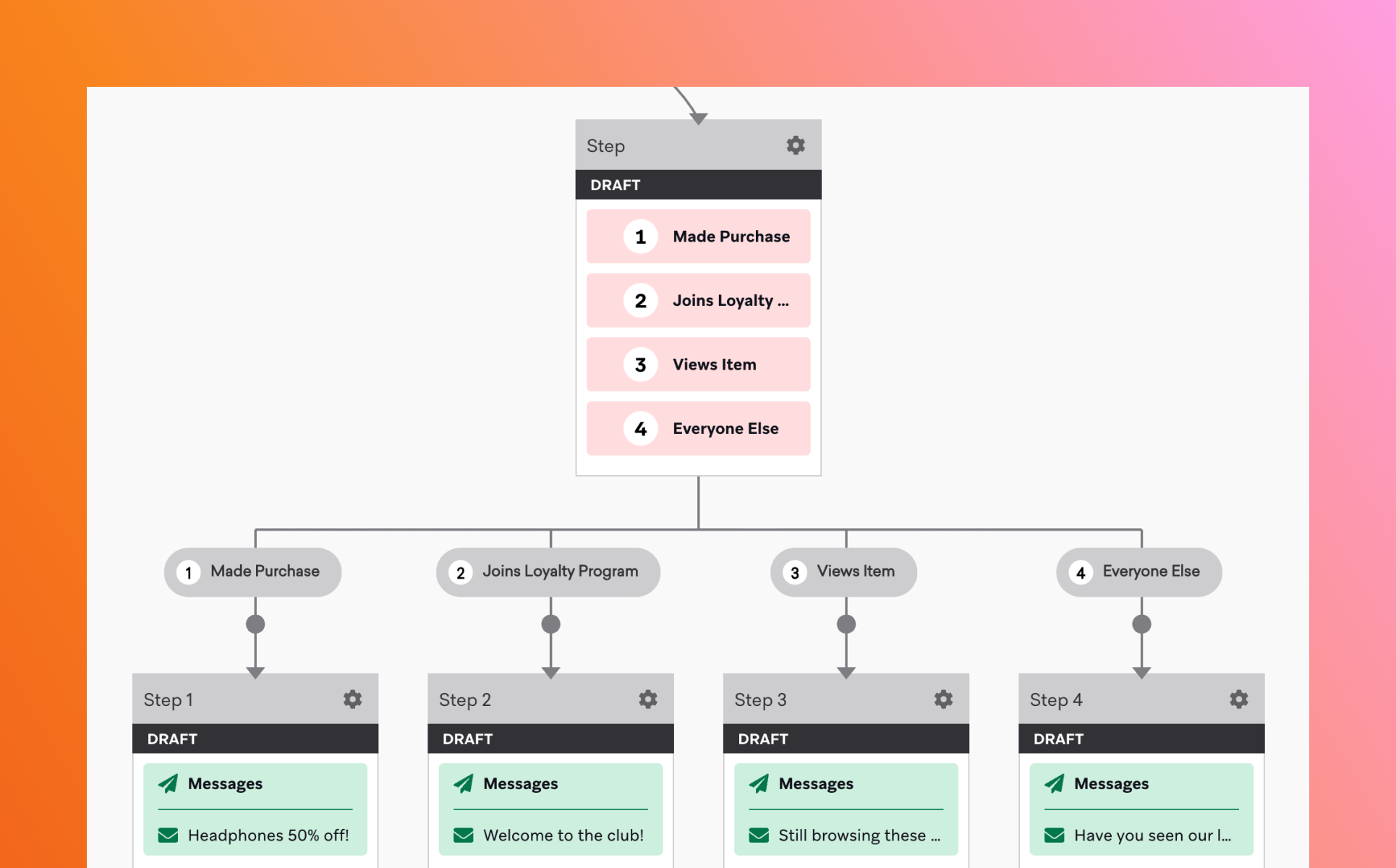
브레이즈 캔버스(Canvas)는 고객의 행동과 속성을 기준으로 개인화된 메시지 흐름을 설계하는 고객 여정 오케스트레이션 도구입니다. 단일 캠페인이 하나의 캠페인을 특정 조건에 따라 발송하는 데 초점을 맞춘다면, 캔버스는 고객의 행동에 따라 여러 메시지와 채널을 유기적으로 연결합니다.
예를 들어, 회원가입 후 7일까지의 유저 저니 설계, 첫 구매까지의 지속적인 구매 유도 메시지 발송 등 단일 순간에 그치지 않고 지속되는 기간 동안 유저 저니에 따라 메시지를 보낼 수 있습니다.
캔버스를 활용하면, CRM 마케팅을 ‘단발성 메시지 발송’에서, 지속적인 고객 경험 관리로 확장할 수 있습니다.
특히 고객 행동이 빠르게 변화하는 환경에서는, 잘 설계된 캔버스가 마케터의 반복적인 운영 부담을 크게 줄여줍니다.


브레이즈 캔버스는 크게 진입 조건(Entry), 액션(Step), 분기(Split)으로 이루어져 있습니다.
해당 속성을 잘 활용하면, CRM 마케터는 하나의 캔버스 안에서 다양한 시나리오를 운영할 수 있습니다. 그뿐만 아니라 고객의 입장에서도 ‘자연스러운 경험’이 가능해져 더 높은 전환 성과를 기대할 수도 있습니다.
브레이즈 캔버스는 강력한 도구이지만, 설계 목적이 명확하지 않으면 오히려 캠페인 운영이 복잡해질 수 있습니다. 하나의 캔버스에는 하나의 목표를 두고, 온보딩•전환•리텐션 등 목적별로 캔버스를 분리해 설계하는 것이 효과적입니다.
또한, 지나치게 많은 분기와 조건은 운영 중 오류나 누락을 유발할 수 있습니다. 초기에는 단순한 구조로 시작하고, 성과와 데이터를 기반으로 점진적으로 고도화하는 방법이 안정적입니다.
마지막으로 데이터 반영 시점을 고려하여 적절한 대기 시간과 조건을 설정해야 합니다.
캔버스는 한 번 만들고 끝나는 것이 아니라, 운영 후 지속적으로 점검하고 개선해야 성과로 이어집니다.
|
|
브레이즈, 믿을 수 있는
|

January 6, 2026
CRM 마케팅의 중요성이 높아지면서, 많은 기업에서 브레이즈(Braze)를 활용해 CRM 마케팅을 진행하고 있습니다. 간단하게는 푸시 메시지 발송부터, 깊게는 캠페인 자동화까지. 브레이즈는 많은 CRM 마케터들에게 익숙한 도구가 되었습니다. 하지만 실제로 현장에서 듣는 이야기는 조금 다릅니다.
“기능은 많은데, 어디까지 쓰고 있는지 모르겠다”
”이 정도면 잘 쓰고 있는 건지 감이 안 온다”
브레이즈를 사용하는 것과 잘 ‘활용’하는 것은 다른 문제이기 때문입니다.
마티니는 이러한 고민에서 출발해, 브레이즈 활용도를 자가진단 해볼 수 있는 질문을 마련했습니다. 자가진단의 목적은 단순히 점수를 매기는 것이 아니라, 현재 우리 팀의 CRM 운영이 어느 단계에 와 있는지, 그리고 다음 단계로 나아가기 위해 무엇이 필요한지를 스스로 인식할 수 있도록 돕는 데 있습니다.
실제로 자가진단에 참여한 기업들을 살펴보면, 캠페인과 자동화는 잘 운영되고 있지만, 데이터 활용, AI 기능, 신규 채널(RCS 등)은 아직 충분히 활용되지 못하고 있는 경우가 많았습니다.

브레이즈를 사용하고 있다면, 이제는 ‘얼마나 잘 활용하고 있는지’를 점검해야 할 시점입니다. 지금 바로 우리 팀의 브레이즈 활용도를 진단해 보세요.
자가진단 점수 구간에 따라 현재 브레이즈 활용도가 어느 수준인지 쉽게 확인해볼 수 있습니다. 결과 페이지에서는 현재 활용 단계에 따른 제안도 함께 확인해볼 수 있습니다.
마티니가 정리한 브레이즈 활용 인사이트와 실제 사례를 통해, CRM을 한 단계 더 고도화하는 방법을 확인해 보세요.
.png)
August 21, 2024
지난 편에서는 각 솔루션별 데이터 수집 방법(바로가기)에 대해서 알아보았습니다.

1. Third Party 데이터 수집 자동화
2. 수집된 데이터 전처리하기
3. 시각화하기
이번에는 수집된 데이터를 활용하여 어떻게 전처리 해야 되는지 알아보겠습니다.
각 데이터 셋들은 분석하려는 차원(dimension)을 기준으로 집계(group by)를 통해서 동일한 형태로 전처리한 후 조인 연산을 통해 데이터를 통합하는 과정이라고 생각하시면 됩니다.
마케팅 성과를 분석하기 위해서 필요한 데이터 다음과 같습니다.
Dimension : 날짜(일별), 유입소스(GA4 = utm_source, Appsflyer = Media_source), 캠페인
Metric : 구매수, 매출, 인스톨 수
GA4가 웹, 앱 모두 트래킹을 할 수 있지만 WEB은 GA4, APP은 MMP로 성과를 합쳐서 보실 겁니다.
GA4, Firebase는 앱과 웹 내 고객 행동 분석에 주로 쓰이는 툴이고 MMP 는 광고 성과를 측정하는 툴이니깐요
그러면 이렇게 됩니다.
<GA4 데이터 집계> - WEB
Dimension : 날짜(일별), 세션 소스, 캠페인
Metric : 구매수, 매출
<MMP 데이터 집계> - APP
Dimension : 날짜(일별), Media_source, 캠페인
Metric : 구매수, 매출, 인스톨 수
집계된 두개의 테이블을 UNION 다시 한번 집계를 해줍니다.
이렇게 하면 집계된 웹앱 데이터 통합이 되었습니다. (MMP 데이터 전처리 과정은 생략)
Dimension : 날짜(일별), Media_source, 캠페인
Metric : 구매수, 매출, 인스톨 수
브레이즈 커런츠(braze currents)데이터는 유저 인게이지먼트 데이터입니다.
여기에는 유저별로 어떻게 우리 서비스로 참여를 하고있는지를 기록한 데이터들이 기록되어 있으니 메시지 발송 수단별로 노출, 클릭 성과들이 들어있습니다. 하지만 우리는 성과(구매) 판단은 MMP, GA4로 해야 하므로 서로 다른 데이터들을 어떻게 통합해서 볼지를 알아보겠습니다.
커런츠 데이터는 아래와 같이 구성이 되어있습니다.

위와 같은 데이터를 일자, 메세지 발송 타입, 캠페인 or 캔버스별 발송수, 노출수, 클릭수 데이터를 집계를 하기 위해서는 유니크한 ID를 나타내는 차원 데이터를 만들어 줘야 합니다.
동일한 유저라도 캠페인, 캔버스, 베리에이션 등 다양한 형태로 타겟이 될 수 있으므로, 아래와 같이 유니크한 차원 데이터를 만들기 위해 새로운 아이디를 생성합니다. (해당 아이디는 발송 타입별로 카운트하기 위해 활용됩니다.)
차원의 이름은 원하시는대로 명명하시면 되고 저는 user_id_dispatch_id 이렇게 명명하였습니다.
-- 태블로 계산식
IFNULL([User Id],'') + '-' +
IFNULL([Campaign Id],'') + '-' +
IFNULL([Message Variation Id],'') + '-' +
IFNULL([Canvas Id],'') + '-' +
IFNULL([Canvas Variation Id],'') + '-' +
IFNULL([Canvas Step Message Variation Id],'') + '-' +
IFNULL([Dispatch Id],'')
다음으로 캠페인 단위로 성과를 집계할 예정이기 때문에 캠페인 차원을 만들어줘야 합니다.
왜냐하면 브레이즈에는 캠페인과 캠버스로 나뉘는데 campaign_name 값이 존재하면 canvas_name 이 빈값이고 거꾸로 canvas_name 값이 존재하면 campaign_name이 빈값이기 때문입니다.
-- 태블로 계산식
IFNULL([Campaign Name],[Canvas Name])
{send_type}_click 이런 식으로 차원 이름을 명명하고 아래와 같은 태블로 계산식으로 차원을 만들어줍니다.
이렇게 되면 email_click, push_click, in_app_message_click 이벤트별로 ID(user_id_dispatch_id)를 생성됩니다.
-- 태블로 계산식
{ FIXED [user_id_dispatch_id],[Event Type] : COUNTD(IF CONTAINS([Event Type], 'inappmessage_click') THEN [user_id_dispatch_id] END)}
최초에 S3에 적재된 currents 데이터(avro 파일)를 DW에 적재할 때 파일별 Event 구분을 위해 Event_Type 칼럼을 생성하였습니다. (이전 글을 참고해 주세요)
['users.messages.email.Open.avro',
'users.messages.email.Click.avro',
'users.messages.pushnotification.Send.avro',
'users.messages.inappmessage.Click.avro',
'users.messages.email.Delivery.avro',
'users.messages.pushnotification.Open.avro',
'users.messages.inappmessage.Impression.avro']
-- 태블로 계산식
IF CONTAINS([Event_Type], 'email') then 'email'
elseif CONTAINS([Event_Type], 'push') then 'push'
elseif CONTAINS([Event_Type], 'inappmessage') then 'iam' end
이제 집계를 위한 전처리는 완료되었습니다(세세한 전처리 과정은 생략됨)
이제 위에서 만들었던 차원을 가지고 집계를 합니다.
일자별, send_type, campaign/canvas, device_category 별 오픈, 클릭, 노출, delivery 데이터는 아래와 같이 집계되었습니다.

통합된 GA4 / MMP 데이터와 커런츠 데이터를 통합해야 되는 과정이 또 남았습니다.
어떻게 이 두 데이터를 엮어야 될까요?
조인키를 위에서 집계한 차원 데이터로 잡고 Full Outer Join으로 데이터를 조인합니다.
이유는 특정 날짜에 브레이즈 커런츠 데이터는 존재하는데 성과 데이터(GA4, MMP) 데이터가 존재하지 않는다면 매칭될 수 없으니 누락이 되어버립니다. 거꾸로 성과 데이터(GA4, MMP) 데이터가 존재하는데 브레이즈 커런츠 데이터가 존재하지 않을 경우 누락이 되어버리기 때문입니다.
광고 성과 데이터 전처리하는 예시를 통해 Full Outer JOIN 이 어떻게 데이터를 처리되는지 예시를 통해 잠깐 확인해 보겠습니다
2024년 1월 1일 twitter 채널의 e 캠페인에서 비용이 1000원 소진했습니다. 그런데 GA4, MMP 데이터에는 해당 광고 채널의 캠페인에서 전환이 아예 일어나질 않았습니다. 하지만 비용이 발생했기 때문에 이 데이터를 버릴 수는 없겠죠? 무조건 살려야 됩니다.
거꾸로 광고 데이터에서 비용은 발생하지 않았는데 Attribution Window로 인해 전환이 발생했습니다. 이것도 버릴 수 없겠죠?
이 두 데이터에서 LEFT JOIN 또는 RIGHT JOIN을 수행하게 되면 조인키에 대응하지 않은 데이터는 매칭이 안되어 누락이 되어 버립니다. 이를 방지하기 위해서 INNER, LEFT OUTER, RIGHT OUTER 조인 집합을 생성하는 FULL OUTER JOIN을 수행합니다.
결과를 보면 각 테이블의 모든 데이터들이 출력이 되는 걸 알 수 있습니다.

본론으로 돌아와서!
Full Outer Join을 수행하기 전에 앞서 GA4, MMP 데이터를 합친 후 우리는 CRM 데이터만 필요하기 때문에 CRM 데이터만 필터를 합니다.
이제 Braze Current 데이터와 성과 데이터(GA4, MMP)를 날짜, 유입소스명, 캠페인명을 조인키로 두고 Full Outer Join 을 수행합니다.(분석하고자 하는 차원데이터가 추가로 더 있다면 추가로 필요한 차원도 조인키로 활용하시면 됩니다.)
이와 같은 방식으로 Paid 성과 데이터를 전처리 할 때도 위와 같은 방법으로 수행하면 됩니다.
데이터를 전처리 할 때 중요한 건 분석하고자 하는 결과물을 먼저 그려본 뒤에 결과를 도출하기 위해서 각 테이블을 어떻게 만들어 갈 것인지 생각하면서 만들어가면 됩니다. 실제로 전처리하다 보면 자잘하게 처리해야 되는 부분이 상당히 많습니다.
특히 데이터를 통합하기 위해서는 무엇보다 네이밍 컨벤션이 가장 중요한 점은 강조하지 않을 수 없습니다.
데이터 수집까지 잘했는데 캠페인 네이밍 컨벤션이 서로 다르다?.. 데이터 통합은 불가능합니다..
네이밍 컨벤션은 말 그대로 명명 규칙입니다.
위에서 언급한 대로 우리가 데이터 통합을 위해 차원 데이터를 조인키로 활용한다고 했었는데 캠페인 차원이 MMP, GA4, Braze or 광고 데이터가 모두 다르면 안 되겠죠? 아래와 같이 통일을 시켜야만 데이터를 연결할 수 있습니다.

여기까지 마케팅 데이터 수집부터 전처리 과정까지 알아보았습니다.
다음 글에서는 이 데이터를 활용해서 시각화 하는 방법을 살펴보겠습니다.

August 21, 2024

루커 스튜디오(Looker Studio)는 구글에서 제공하는 강력한 데이터 시각화 도구입니다. 다양한 데이터 소스를 연결하여 직관적인 대시보드를 만들 수 있으며, 이를 통해 복잡한 데이터를 쉽게 이해할 수 있습니다. 특히, 마케팅, 영업, 운영 등 다양한 분야에서 유용하게 활용될 수 있습니다. 루커스튜디오가 궁금한 분들은 해당 글을 참고해주세요.
인터랙티브 퍼널 차트는 사용자 행동을 단계별로 분석하여 시각적으로 표현하는 방식입니다. 특히, 마케팅 퍼널 분석에 유용하며, 고객이 제품이나 서비스를 구매하기까지의 과정을 시각화하여 각 단계에서의 전환율을 파악할 수 있습니다.
퍼널 분석에는 두 가지 전환율 분석 방식이 존재합니다:
이 두 가지 방식 모두 데이터의 절대값(absolute) 형태와 비율(rate) 형태로 나눠서 분석할 수 있습니다. 이를 통해 어떤 단계에 문제가 있는지 비교하면서 파악할 수 있습니다.
퍼널 분석을 통해 마케팅 전략의 효과를 검토하고 개선할 수 있는 인사이트를 얻을 수 있습니다. 예를 들어, 특정 단계에서 이탈율이 높다면 해당 단계의 문제점을 찾아 해결하는 방식으로 퍼널의 전반적인 전환율을 개선할 수 있습니다.
루커 스튜디오 인터렉티브 퍼널 분석 차트 만들기 | Looker studio
인터랙티브 퍼널 리포트를 작성하는 단계는 크게 데이터 준비, 바 차트 생성, 차트에 인터랙티브 기능 추가로 나눌 수 있습니다.
먼저, 데이터 소스를 연결한 후 필요한 데이터를 정리합니다. 예시는 GA4 데모 데이터를 활용 하였습니다.
계산된 필드와 매개변수 설정이 필요합니다.
아래 이미지에 활용할 매개변수 2가지를 만들어봅시다.

Drop-off type

Value type
데이터 혼합을 이후에 활용할 예정입니다. 데이터 혼합에서 매개변수 사용을 위해서는 매개변수를 측정기준으로 아래와 같이 변경하는 작업이 필요합니다.

앞서 살펴봤던 매개변수의 계산된 필드 변환을 포함하여 3가지 측정기준을 만들어 줍니다.
Drop-off type dim

Value type dim

Funnel step order #
GA4의 전자상거래 5개 이벤트를 선택하고 해당 단계의 순서를 지정하는 이벤트를 만들어줍니다.
Looker Studio 코드 1
CASE
WHEN 이벤트 이름 = "add_to_cart" THEN 1
WHEN 이벤트 이름 = "add_shipping_info" THEN 2
WHEN 이벤트 이름 = "begin_checkout" THEN 3
WHEN 이벤트 이름 = "add_payment_info" THEN 4
WHEN 이벤트 이름 = "purchase" THEN 5
ELSE NULL
END

GA4 – Checkout steps
앞서 정의한 5개 외 나머지 이벤트는 Null로 처리 되었습니다. 해당 이벤트는 분석에 활용하지 않을 예정이므로 필터를 이용하여 제외 처리를 해줍니다. 해당 필터는 이후 단계에서 활용하도록 하겠습니다.

퍼널 분석을 위해선 직전단계와 다음 단계 사용자의 차이를 구해야합니다. 다만 루커스튜디오는 단일 소스로 해당 계산을 하기가 어렵기 때문에 데이터 혼합의 교차 조인을 활용하여 단계별 유저 차이를 구하는 식을 만들 수 있습니다.


데이터 준비가 완료되면, '차트 추가' 메뉴에서 바 차트를 선택합니다. 바 차트를 생성한 후, X축과 Y축에 표시할 데이터를 설정합니다.
3.4.1 설정 탭
Abs users
Looker Studio 코드 2
IF(
Values type dim = "Absolute values"
,
Total users
,
null
)
Abs exited users
Looker Studio 코드 3
IF(
Values type dim = "Absolute values"
,
IF
(
Drop-off type dim = 'Funnel drop-off'
,
IF(Ref Funnel step order = 1 AND Funnel step order != 1, (Ref Total users - Total users),null)
,
IF(Ref Funnel step order = Funnel step order - 1, (Ref Total users - Total users),null)
)
,
null
)
% active
Looker Studio 코드 4
IF(
Values type dim != "Absolute values"
,
IF
(
Drop-off type dim = 'Funnel drop-off'
,
CASE
WHEN Funnel step order = 1 THEN 1
WHEN Ref Funnel step order = 1 AND Funnel step order != 1 THEN (Total users ) / Ref Total users
ELSE NULL
END
,
CASE
WHEN Funnel step order = 1 THEN 1
WHEN Ref Funnel step order = Funnel step order - 1 THEN (Total users ) / Ref Total users
ELSE NULL
END
)
,
null
)
% drop off
Looker Studio 코드 5
IF(
Values type dim != "Absolute values"
,
IF
(
Drop-off type dim = 'Funnel drop-off'
,
IF(Ref Funnel step order = 1 AND Funnel step order != 1, (Ref Total users - Total users)/Ref Total users,null)
,
IF(Ref Funnel step order = Funnel step order - 1, (Ref Total users - Total users)/Ref Total users,null)
)
,
null
)
3.4.2 스타일 탭

인터랙티브 퍼널 리포트는 다양한 마케팅 시나리오에서 유용하게 활용될 수 있습니다. 예를 들어, 고객의 구매 여정을 단계별로 분석하여 각 단계에서 발생하는 이탈율을 파악하고, 이를 개선하기 위한 전략을 세울 수 있습니다.
또한, 특정 마케팅 캠페인의 성과를 분석할 때도 퍼널 리포트를 사용하면 각 채널별로 고객의 반응을 비교할 수 있습니다. 이를 통해 어떤 채널이 가장 효과적인지 파악하고, 마케팅 예산을 효율적으로 분배할 수 있습니다.

August 14, 2024


[Martinee X Braze]
Braze Personalization Master Class Advanced는 Braze 도입을 고민하고 계시거나 도입 후 잘 활용하고 싶으신 고객사를 대상으로 Braze 개인화 기능인 Personalization 활용 노하우를 공유하는 교육 세미나입니다.
브레이즈 개인화 기능, 여러분도 잘 활용할 수 있습니다.
“Braze 도입은 했는데.. 어디서부터 어떻게 해야 하지?”
“Braze 개인화, 더 깊고 세부적으로 사용하려면 개발이 필요하지는 않을까?”
Braze 개인화 기능, 여러분도 개발없이 전문가처럼 매우 세부적으로 활용할 수 있습니다.
이번 세션에서는 Braze 개인화 단계 중 Liquid와 Connected Contents를 활용하여 심화 켐페인 실습을 진행하여 충분히 실무에 활용할 수 있도록 하였으며,
성공적인 CRM 캠페인을 위한 다양한 CRM 캠페인 사례들을 함께 확인해봅니다.


마티니는 버거킹, 오늘의집, 무신사, KFC, 쏘카, 알라미(딜라이트룸), 발란, 칼하트, LG전자, 넷마블, 크래프톤, 머스트잇, 동원F&B, 이랜드폴더, 네오위즈, IBK기업은행, 밀리의서재 이외에도 다양한 고객사와 여정을 함께하고 있습니다.
실무에 바로 적용할 수 있는 활용 노하우, 마티니와 함께한 고객사들이 만족하는 이유입니다.

지난 브레이즈 부트캠프에 참여해주신 분들의 생생한 후기를 확인해보세요.
“ 실제 사용 사례에 대해 많이 들을 수 있어서 좋았고 브레이즈 시현 과정을 볼 수 있어서 좋았습니다. “
“ 라이브 데모를 통해 어떻게 활용하는지 상세하게 알 수 있었습니다. “
“CRM 고도화에 Braze가 어떻게 기여할 수 있을지에 대한 궁금증을 해소할 수 있었습니다. “
“Braze 개인화를 위한 Liquid의 개념과 구조 설명이 있어서 이해하기 좋았습니다. “



Braze Personalization Master Class | 이건희 연사, Martinee CRM Team Lead
Braze Automation Master Class
Braze Data Analytics Master Class
2024년 8월 26일 월요일 오후 7시 - 9시
서초구 서초대로 38길 12 마제스타시티 타워2, 12층 마티니 오피스

📢 혜택 1. Martinee CRM 커뮤니티 초대
📢 혜택 2. 마티니 CRM POC 추첨 무료 1회 제공
CRM 캠페인의 성과와 비즈니스 개선을 마티니와 함께 이뤄보세요!

August 6, 2024

행사명 : Maritnee 2024 Recap 행사
장소: 서울 서초구 서초대로38길 12 마제스타시티 타워2 12F
일시: 2024년 8월 20일 화요일 오후 3시
대상:


MGS 2024에서 진행했던 마티니 & AB180 & Snowflake의 세션을 한 번에 확인해보세요.
CRM과 그로스 마케팅을 바탕으로 마티니가 직접 경험하고 이끌었던 실제 성공 사례, AB180의 마케터를 위한 SKAN 활용법과 Snowflake의 마케팅 데이터 클라우드로 비즈니스 성장을 가속화하는 방법을 공유합니다.
MGS 2024 현장에서 공유해드린 마케팅 인사이트와 성공 사례에 대해 확인할 수 있는 기회를 놓치지 마세요!

15:00 - 15:15 Martinee Marketing Intelligence 2024 | 이선규 Martinee CEO
15:15 - 15:45 버거킹도 Amplitude를 쓴다고? 어떻게 쓰는데? | 이재철 Martinee Growth Team Lead
15:45 - 16:15 "우리 잘하고 있는건가?": CRM 마케터들이 궁금해하는 고민과 해결방안 | 이건희 Martinee CRM Team Lead
16:15 - 16:25 Break Time
16:25 - 16:55 iOS 마케터를 위한 SKAN 100% 활용하기 | 한예선 Airbridge & AB180 Business Development Manager
16:55 - 17:25 감'이 아닌 '데이터'로 : Snowflake로 데이터 기반 인사이트 발견하기 | 이수현 Snowflake Tech Evangelist
17:25 - 18:00 Networking & QnA

- 자리가 한정되어 있어 별도로 선정 안내를 드릴 예정입니다.
- 주차권 제공 가능하며 리셉션 데스크 문의바랍니다.
- 참석자분들에게 간단한 음식이 제공됩니다.

August 2, 2024


7월 31일, 코엑스 그랜드볼룸 & 아셈볼룸에서 AB180이 주최한 국내 최대 마케팅 컨퍼런스 MGS 2024가 개최되었습니다.
23년에 이어 마티니가 참여한 MGS 2024에서는 CRM 마케팅에서의 고민과 마티니가 경험하며 체득한 해결방안과 인사이트와 더불어 버거킹의 Amplitude 도입부터 세부적인 단계별 과정을 소개드리고 쏘카와 함께 Braze를 활용한 크로스 셀링 전략과 초개인화 CRM 마케팅 성공 사례를 3개의 발표 세션을 통해 공유하는 자리였습니다.
MGS 2024에서 진행했던 마티니 세션들을 살펴볼까요?


마티니 CRM팀은 KFC, 이랜드 폴더, 콘텐츠웨이브, 뮤직카우, 레브잇, 발란, 딜라이트룸 알라미, 오늘의집, 버거킹 등 무수히 많은 국내 유명 기업과 함께 협업하며 Braze를 200% 활용하고 CRM 인사이트를 확장시켜 왔는데요.
지금까지 수많은 CRM 캠페인을 실행하고 경험하고 겪었던 CRM 마케팅에서의 고민들과 그에 따른 마티니만의 해결방안을 CRM팀 리더 건희님이 발표 세션에서 공유해드렸습니다.
개인화
개인화로 어떤 걸 할 수 있어요?
➡️ 개인화의 3단계 Level과 함께 마티니가 실제 적용해본 CRM 사례를 바탕으로 개인화로 가능한 부분을 설명해드렸습니다.
분석
CRM 성과 어떻게 분석하는 것이 좋을까요?
➡️ 증분 분석과 PA 솔루션 활용으로 오로지 마케팅 활동이 만들어준 ‘진짜’ 성과를 찾는 방법을 알려드렸습니다.
연계활용
PA나 MMP랑 연계하면 뭘 할 수 있나요?
➡️ 각 솔루션의 역할과 CRM 솔루션과의 연동 케이스들을 기반으로 PA 및 MMP 솔루션과 연동 활용 시 가능한 점들을 설명드렸습니다.
테스트
모수가 너무 적은데 의미 있을까요?
➡️ 모수 크기 계산과 카이 제곱 검정식을 바탕으로 적절한 모수와 전환율을 확인하는 방법을 공유해드렸습니다.
도입
Braze 도입, 어느 정도 걸려요?
➡️ 도입 시작부터 첫 캠페인 런칭 기준 도입기간과 컨설팅 유무에 따른 비교을 통해 소요 기간을 알려드렸습니다.
기술적 구현
개발 지원을 못 받아서 못 하는게 많아요.
➡️ 개발 의존도를 낮춰주는 Braze의 3가지 강력한 주요 기능을 소개해드리며 개발 지원없이 가능한 CRM을 사례를 통해 설명해드렸습니다.



마티니는 버거킹의 Amplitude 도입부터 사용, 그리고 Braze 연계 활용까지 함께 하였는데요.
온오프라인이 모두 중요한 버거킹의 경우 디지털 플랫폼 활용도가 높기에 Amplitude 도입을 5단계의 체계적인 절차를 바탕으로 진행하였고 그에 따른 각 단계별 키 포인트들을 공유해드렸습니다.
1. Planning
5. Go-Live
활용 단계에서는 구매 횟수별 고객 특성과 구매 시간대별 고객 특성 2가지로 나누어 쿠폰 사용 패턴을 분석한 과정과 AARRR 지표 설계에 따른 세부 기준, 유저 코호트와 같은 지표 분석 과정, 가설 도출부터 A/B 테스트 설계까지 버거킹과 함께한 상세한 내용들을 설명해드렸습니다.
고객 행동 중 구매 시간대에 따라 고객의 특징이 다르게 나타난다는 점을 확인할 수 있었고 얼마나 차이가 있는지 Amplitudfe 코호트 차트 기능을 활용하여 분석하였습니다.
분석한 내용을 바탕으로 Braze에서 약 48개의 코호트 그룹을 나누어 최적 시간대와 메시지 테스트를 진행하여 결과적으로 성과를 개선시킬 수 있었습니다.




쏘카는 기존 카셰어링에서 작년부터 숙박 서비스까지 비즈니스를 확장시키며 마티니와 함께 Braze를 잘 활용하여 체계적인 캠페인 관리 시스템을 구축해왔습니다.
해당 세션에서는 우천 시 서비스 이용이 활발해지지 않는 서비스 특성을 고려한 쏘카만의 캠페인 사례와 숙박 서비스로 범위를 확장하며 각 타겟의 반응을 확인하며 메시지 발송 대비 전환률을 상승시킨 전략들을 확인할 수 있었습니다.
CRM 마케팅에서 개발 지원없이 섬세한 캠페인 전략을 구사하기가 어려울 수 있는데요. 쏘카가 마티니와 함께 개발자 도움 없이 Braze Connected Content 기능을 활용하여 초개인화 메시지를 구현했던 과정도 상세하게 설명해드렸습니다. 기술 구현이 필요한 항목을 점검하고 오픈데이터와 Braze Liquid 및 Connected Content 기능을 활용한 케이스를 공유하며 어떻게 크로스셀링 전략을 성공적으로 이끌었는지 공유해드린 시간이었습니다.
놓치면 후회하는 마티니와 쏘카의 CRM 협업 사례, 8월 13일 Recap 행사에서 확인하실 수 있습니다.


이번 MGS 2024에서는 마티니가 부스를 운영하여 풀스택 마케팅 도입 컨설팅 서비스에 대해 상담 서비스를 제공해드리고 보다 자세하게 설명드릴 수 있도록 하였습니다.
캡슐 뽑기를 통해서 마티니 스티커와 에코백 굿즈를 나눠드렸습니다.
마티니는 세 가지 분야의 전문가들이 모여 유기적으로 협업하며 다양한 문제를 해결하고 있습니다.
버거킹과 쏘카 사례에서 보여드린 것처럼 데이터·프로덕트 분석, KPI 대시보드 설계와 제작, 데이터 파이프라인 활용, CRM 택소노미(Taxonomy) 및 프로모션 설계, MMP 설치와 점검, 퍼포먼스 마케팅 미디어 믹스까지, 각 분야의 전문가들이 모여있는 마티니와 함께 비즈니스 성공을 실현해보세요.


July 29, 2024
쿠키(Cookie)란 사용자가 웹사이트를 방문할 때마다 웹 브라우저를 통해 인터넷 사용자의 컴퓨터나 다른 기기에 설치되는 기록 정보 파일을 뜻합니다. 이는 퍼포먼스 마케팅의 필수도구로써 마케팅 활동의 세부적인 추적, 개인화 및 최적화를 가능하게 했습니다.
퍼포먼스 마케팅에서 구체적인 쿠키의 기능은 다음과 같습니다.
1. 사용자 행동 추적
2. 개인화
3. 리타겟팅
4. A/B 테스트 및 최적화
하지만 데이터 보호 규정을 시작으로 데이터 보호를 강화하기 위한 전세계의 흐름이 있었고, 애플을 시작으로 구글 폭스 등 많은 웹 브라우저 회사들이 쿠키 제공 중단을 선언헀습니다.
쿠기 제공이 중단된다면, 기존의 쿠키를 이용해 진행하던 기능들을 더 이상 진행할 수 없게 됩니다. 그 결과 각 매체의 효율이 감소하고 신규 고객을 획득하는데 필요한 비용이 증가할 것으로 예상됩니다. 구글이 쿠키의 지원 중단 시점을 2025년으로 연기했다고는 하지만, 마케터들은 선택이 아닌 필수로 기존 광고 방식에 변화가 필요한 상황입니다.
쿠키 리스 상황에서 발생하는 여러 문제들에 대비하기 위해 진행할 수 있는 여러 방법들이 있습니다. 그 중 고객사에서는 현 상황에서 다양한 매체를 활용하기보다 최고의 효율을 낼 수 있는 매체를 선별해서 효율이 좋은 매체에 집중하고자 합니다. 이를 위해 각 광고매체의 성과를 실시간으로 모니터링할 수 있는 대시보드가 필요했습니다.

태블로를 통해 다양한 광고채널에 분산되어 모니터링이 어려웠던 지표들을 태블로를 통해 하나의 대시보드에서 관리함으로써 어느 채널의 어떤 광고가 효율이 좋은지를 빠르게 파악하고, 이를 통해 어떤 채널에 더 예산을 증가하거나 감소해야 할지에 대한 의사결정을 하는데 활용할 수 있습니다.
대시보드를 제작하기 위한 과정은 크게 환경점검, 데이터 수집, 데이터 저장, 데이터 시각화의 4단계로 구분할 수 있습니다.

첫 번째 환경 점검 단계는 대시보드 구축을 위한 대시보드 기획단계입니다. 이 단계에서는 데이터의 출처를 정의하고, 데이터 소스부터 시각화툴인 태블로까지 이어지는 데이터 파이프라인을 그립니다. 최종적으로 대시보드에서 어떤 데이터를 대시보드에 구현하고, 이를 어떤 방식으로 시각화할지에 대한 대시보드 기획단계라고 할 수 있습니다.

해당 광고성과 대시보드를 구현하기 위해서는 광고채널로부터 나오는 광고데이터를 데이터 소스로 정의하고, 이를 통합하는 과정이 필요합니다. 이를 위한 첫 번째 단계로 Meta, Google Ads등 여러 광고 채널에서 나온 데이터를 ETL툴인 Funnel io에서 통합합니다. 이후 MMP인 에어브릿지의 데이터를 통합해 이를 하나의 구글 스프레드시트 적재합니다. 최종적으로 태블로를 통해 시각화하는 방식으로 데이터 파이프라인을 구현했습니다.

해당 스텝으로 데이터 파이프라인을 구현했을 때의 장점은 어디서부터 데이터가 들어오게 되고, 문제가 발생했을 때 문제 발생원인을 직관적으로 확인가능하다는 점입니다.
두 번째 데이터 수집 단계는 실질적으로 필요한 데이터를 정의하는 단계입니다.
UTM 및 parameter를 기반한 광고성과 추적을 위한 계층 구조인 네이밍 컨벤션(Naming Convention)을 정의하고 이를 통해 광고의 위계질서를 설정합니다. 해당 데이터를 통해 광고성과 데이터 정의하고 수집할 수 있습니다.

네이밍 컨벤션(Naming Convention) 정의를 완료했다면, 이를 토대로 데이터 스키마를 작성해야 합니다. 데이터 스키마란 데이터베이스의 구조와 제약조건에 관해 기술한 것을 뜻합니다. 데이터 이름 및 형태(ex. 숫자/문자)에 대해 정의함으로써 향후 데이터 스키마 하나만 확인해도 어떤 데이터 형태인지 파악할 수 있도록 합니다.
세 번째 데이터 저장 단계는 네이밍 컨벤션(Naming Convention)과 데이터 스키마를 통해 정의한 데이터를 저장하는 단계입니다.
광고성과 확인 시, 데이터의 정확성을 확보하고, 다양한 광고채널의 기여도를 정확하게 측정하기 위해 미디어 데이터 뿐만 아니라 MMP 데이터를 함께 확인해야 합니다. 이를 위해 미디어(메타, 구글애즈,..)와 MMP의 소스를 조인하는 과정이 필요합니다. 이를 위해 키값을 정의하고, 해당 키값을 기준으로 데이터를 조인합니다.

마지막 데이터 시각화 단계는 정의된 데이터를 바탕으로 대시보드를 구현하는 단계입니다.
대시보드 구현에 앞서 퍼포먼스마케터들과 협의를 진행합니다. 실제 최종 대시보드를 사용할 퍼포먼스마케터들과의 논의를 통해 대시보드의 형태 및 기능을 구체화할 수 있습니다.

마지막으로 확정된 기획안을 토대로 태블로를 통해 최종 대시보드를 구현하면 대시보드 제작과정이 마무리됩니다.


July 19, 2024


KPI 대시보드 템플릿을 활용하여 비즈니스 주요 지표를 확인하며 데이터 기반 의사결정에 활용할 수 있습니다. 매출, 이익, 구매수 등 특히 지역별 구매 관점의 분석을 통해 실행 가능한 인사이트를 제공합니다.
1. 스프레드시트 사본 만들기

2. 루커스튜디오 사본 만들기 클릭


3. 리소스 → 추가된 데이터 소스 관리 클릭

4. 작업 → 수정 클릭

5. 루커스튜디오와 스프레드시트 연동 승인 진행

6. 앞서 사본을 만들었던 파일 찾아서 연결

7. 데이터 새로고침하면 데이터 확인이 됩니다.


July 18, 2024
프로모션 분석은 마케팅 캠페인의 일환으로 진행된 다양한 프로모션 활동들의 효과를 평가하고 측정하는 과정입니다. 이 과정을 통해 기업은 프로모션 활동이 소비자의 구매 결정, 브랜드 인식, 시장 점유율 등에 미치는 영향을 분석할 수 있습니다. 프로모션 분석을 위해 판매 데이터, 소비자 행동 데이터, 온라인 트래픽 데이터 등 다양한 데이터 소스를 활용할 수 있습니다.
프로모션 분석은 기업이 자원을 효율적으로 배분하고, 마케팅 목표를 달성하기 위해 필수적인 과정입니다. 이를 통해 기업은 다음과 같은 이점을 얻을 수 있습니다.
개별 프로모션 분석과 통합 프로모션 분석을 함께 수행함으로써, 보다 정교하고 효과적인 마케팅 전략을 개발할 수 있으며, 이는 최종적으로 기업의 성장과 수익성 향상에 기여하게 됩니다.
1. 전체적인 마케팅 전략의 효율성 평가
개별 프로모션 분석을 통해 특정 프로모션의 성공 여부를 파악할 수 있지만, 통합 프로모션 분석을 함께 수행하면 여러 프로모션 간의 상호작용과 그 영향을 이해할 수 있습니다. 이는 전체 마케팅 전략의 효율성을 평가하는 데 중요합니다.
2. 다채널 프로모션 전략의 최적화
현대 마케팅은 다양한 채널을 통해 이루어집니다. 개별 프로모션 분석과 통합 분석을 병행함으로써, 각 채널의 성과를 정확히 파악하고, 채널 간 시너지를 극대화하는 전략을 수립할 수 있습니다.
3. 고객 행동의 종합적 이해
고객은 다양한 프로모션에 노출되며, 이러한 노출이 고객의 구매 결정에 복합적으로 작용합니다. 개별 프로모션 분석과 통합 분석을 결합함으로써, 고객 행동의 더 깊은 이해를 도모할 수 있습니다.
4. 마케팅 자원의 효율적 배분
통합 프로모션 분석을 통해 얻은 인사이트는 마케팅 자원의 효율적인 배분을 가능하게 합니다. 각 프로모션의 효과를 개별적으로뿐만 아니라 전체적인 관점에서 평가함으로써, 예산을 더 효과적인 프로모션에 집중할 수 있습니다.
5. 장기적 마케팅 전략 수립
개별 프로모션의 성공은 단기적인 성과에 초점을 맞출 수 있지만, 통합 프로모션 분석은 장기적인 관점에서 마케팅 전략을 수립하는 데 도움을 줍니다. 다양한 프로모션의 장기적인 영향력과 지속 가능성을 평가할 수 있습니다.
6. 경쟁 우위 확보
통합 프로모션 분석을 통해 시장 내 경쟁 상황과 자사의 위치를 종합적으로 이해하고, 경쟁 우위를 확보할 수 있는 전략을 수립할 수 있습니다. 이는 경쟁사 대비 우위를 점하는 데 중요한 역할을 합니다.
고객사에서는 프로모션 분석 진행 시 앰플리튜드를 통한 단일 프로모션 위주의 분석만을 진행했었습니다.

앞서 언급했듯이 단일 프로모션 분석만 진행하게 된다면 결과적으로 장기적인 효과나 전체적인 마케팅 전략과의 연계성이 부족해지는 문제가 있습니다.
이러한 문제를 해결하기위해 프로모션을 통합적으로 확인하는 것에 대한 필요성이 대두되었습니다. 먼저, 통합 프로모션 분석을 위해 1차적으로 앰플리튜드를 통해 얻은 개별 프로모션별 데이터를 스프레드시트에서 취합해 프로모션들끼리 비교하며 인사이트를 도출했습니다.

하지만 시트를 통해 프로모션을 비교 분석하는 것에는 크게 2가지 정도의 한계가 있었습니다.첫째, 프로모션이 진행될 때마다 데이터를 확인하고, 직접 시트에 옮기는 작업을 해야 하기 때문에 자동화가 어렵다는 점입니다.둘째, 시트에 텍스트로만 적혀있다보니 해당 데이터가 무엇을 의미하는지 직관적으로 인지하기가 어렵다는 점입니다.이러한 한계를 극복하기 위해 고안한 것이 전체 프로모션을 한눈에 파악할 수 있는 대시보드를 구현하는 것이었습니다.
대시보드는 태블로(Tableau)를 사용하여 구현했습니다.

태블로는 데이터를 분석하고 시각적으로 표시할 수 있는 비즈니스 인텔리전스(BI)툴입니다. 태블로를 통해 대시보드를 제작했을 때의 장점은 다음과 같습니다.
1. 여러 raw 데이터 통합: 태블로는 스프레드시트, 데이터베이스, 클라우드 서비스 및 빅데이터 플랫폼과 같은 다양한 데이터 원본들을 원활하게 통합됩니다. 이러한 통합을 통해 다양한 소스의 데이터를 연결 가능하게 하여 데이터 사일로를 해결하고 포괄적인 분석을 가능하게 합니다.데이터 사일로(Data Silo*)**란? 서로 분리되어 기업의 다른 부서에서 액세스할 수 없는 데이터 스토리지 및 관리 시스템을 의미하며, 이는 전사관점의 의사결정을 방해하고, 비효율성이 증가시킵니다.
2. 실시간 데이터 시각화: 태블로는 라이브 데이터베이스 및 스트리밍 데이터를 비롯한 다양한 데이터 원본에 연결하여 실시간으로 데이터 업데이트할 수 있습니다. 이 기능을 사용하면 변경되는 데이터를 빠르게 모니터링하고 분석하여 빠른 의사 결정을 위한 시기적절한 통찰력을 제공할 수 있습니다.
3. 다양한 시각화 옵션: 태블로는 막대 차트, 선 차트, 산점도, 지도 등을 포함하여 다양한 시각화 옵션을 제공합니다. 정보를 효과적으로 전달하기 위해 데이터에 가장 적합한 시각화 유형을 선택할 수 있습니다.
4. 대화형 대시보드: Tableau를 사용하면 사용자가 직접 데이터를 탐색하고 상호 작용할 수 있는 고도의 대화형 대시보드를 만들 수 있습니다. 사용자는 세부 정보를 드릴다운하고, 데이터를 필터링하고, 임시 분석을 수행하여 데이터 탐색의 깊이를 향상할 수 있습니다.
통합 프로모션 분석을 위해 정의한 스케치입니다. 해당 스케치는 피그마(Figma)를 통해 작업했습니다. 스케치를 피그마로 제작한 이유는 여러가지가 있는데, 그 중 가장 중요한 이유는 피그마가 다양한 디자인 도구와 기능을 제공하기 때문에 원하는 디자인을 쉽고 효율적으로 제작할 수 있기 때문이었습니다.

스케치 대시보드를 기준으로 필요한 데이터를 정리해보면 데이터는 크게 3가지로 분류할 수 있습니다.
1. 프로모션 데이터
2. 매출 데이터
3. CRM 데이터
프로모션명, 진행일자, 분류, 컨셉 등 프로모션 진행 관련 기본 정보 및 프로모션 관련 아이템 정보가 프로모션 데이터에 해당하며, 각 프로모션에 관련된 실제 결제 정보가 매출 데이터에 해당합니다. 마지막으로 유저들에게 발송된 메시지의 발송일 및 캠페인명, 발송수 등이 CRM 데이터에 해당합니다.


다음으로 앞서 정리한 데이터를 좀 더 구체적으로 정리합니다. 각 항목별 필요한 정보가 정확히 무엇인지, 해당 데이터는 형태로 관리되어야 하는지를 비롯해 각 데이터를 연결하기 위해 어떤 컬럼을 키값으로 사용해야 하는지 등을 파악하여 정리합니다.

이때 테이블 색상에 차이를 두어 각 데이터가 어떤 소스에서 관리되는지 직관적으로 파악할 수 있도록 합니다.

필요 데이터 정의를 완료했다면, 데이터 추출을 위해 해당 데이터에 대해 알맞은 형태로 적재를 요청하는 단계가 필요합니다. 효율적인 작업을 위해 원하는 이벤트 및 세부 항목(*이벤트 프로퍼티, 유저 프로퍼티, 적재형식, 적재기준일, 요청사유 등) 관련 내용을 최대한 상세하게 기입합니다.

원하는 이벤트 및 세부 항목을 작성한 다음에 해당 내용을 정확히 어떤 형태로 적재되기 원하는지를 보여주는 샘플을 함께 작성합니다.

이제 데이터 연결을 진행해야 합니다. 해당 프로젝트에는 구글 스프레드시트, 엑셀 파일, 구글 클라우드(빅쿼리)의 소스가 사용되었습니다. 저는 그 중 ‘구글 클라우드’에 초점을 맞추어 데이터 연결과정에 대해 설명하려고 합니다.

구글 클라우드를 사용한 이유는 무엇일까요? 그 이유는 앰플리튜드(Amplitude)에 있는 매출 데이터를 연결하기 위함입니다. 앰플리튜드는 그 자체로 사용성이 높이며, 매출 데이터를 비롯하여 많은 데이터를 손쉽게 확인할 수 있는 툴입니다.
하지만 지금과 같이 더 많은 내용을 확인하기 위해서는 다른 로데이터와 결합을 해서 데이터를 확인하는 과정이 필요합니다. 이 때, 앰플리튜드에서 태블로로 데이터를 바로 전달할 수는 없습니다.

태블로로 데이터를 전송하기 위해서는 앰플리튜드의 로데이터를 가공하여 알맞은 형태로 테이블을 가공해주는 선행작업이 필요합니다. 앰플리튜드와 연동이 가능할 뿐만아니라 태블로와의 연동도 가능해야 하며 무엇보다 앰플리튜드로부터 전달받은 로데이터를 가공할 수 있는 플랫폼이여야합니다.
이 작업을 수행할 수 있는 플랫폼은 무엇일까요? 저희는 이러한 요건을 모두 고려할 때 해당 작업을 수행하기에 가장 적합한 것이 Google BigQuery라고 판단했고, 이를 활용하기로 했습니다.

앰플리튜드는 기본적으로 빅쿼리로 데이터를 바로 내보내는 기능을 제공합니다. 우선 해당 기능을 활용해 앰플리튜드 데이터를 빅쿼리에 내보내는 작업을 진행했습니다.

해당 방법을 통해 데이터를 받아올 경우, 이벤트 프로퍼티가 분리된 표 형식으로 넘어오는게 아니라 json이라는 괄호 안에 키와 값형태로 구성돼 있는 포맷(*”{”~”}”)으로 데이터가 불러와지는 문제가 발생했습니다.
태블로는 표 형태의 데이터 프레임을 인식하므로, 태블로에 데이터를 연결하기 위해서는 앰플리튜드 로데이터를 전처리하는 과정이 필요했습니다.

해당 데이터를 전처리하기 위해서는 로데이터의 형태를 파악해야 했습니다. 데이터를 확인한 결과, 텍소노미에 따라 로데이터의 구조가 다를 수 있음을 확인했습니다.
구매 이벤트의 경우 아이템 수량이 1개일 경우에는 값으로, 2개 이상일 경우에는 배열로 이벤트 프로퍼티 데이터가 들어오는 구조였습니다.
{"item_brand":"A",
"item_category":"JAJL",
"item_id":"99999",
"item_name":"GARAGEJACKET",
"item_price":"198000",
"order_id":"20240310105120687",
"total_order_items_quantity":1
…}{"item_brand":["B","C"],
"item_category":["LFOT","반팔 셔츠"],
"item_id":["88888","77777"],
"item_name":["TRAVEL COMB","CUSTOM SHIRT"],
"item_price":[18000,113000],
"total_order_items_quantity":2}
따라서 데이터 전처리를 위해서는 각 케이스별로 다른 전처리과정을 거쳐야했습니다. 아이템 수량이 1개일경우는 JSON의 값을 파싱하는 처리를 하고, 2개 이상일 경우에는 JSON의 배열을 파싱하는 처리를 진행했습니다.
해당 내용을 처리하는 쿼리문 다음과 같습니다. 케이스별로 결과 테이블이 도출되면, 두 테이블을 유니온하여 한 테이블로 합치는 작업을 진행했습니다.
WITH single_item_orders AS (
SELECT event_time, user_id,
JSON_VALUE(event_properties, '$.order_id') AS order_id,
JSON_VALUE(event_properties, '$.item_category') AS item_category,
JSON_VALUE(event_properties, '$.item_brand') AS item_brand,
JSON_VALUE(event_properties, '$.item_name') AS item_name,
JSON_VALUE(event_properties, '$.item_id') AS item_id,
JSON_VALUE(event_properties, '$.item_price') AS item_price
FROM amplitude_test.EVENTS_353961
WHERE event_type='total_items_order_completed'
AND JSON_VALUE(event_properties,'$.total_order_items_quantity')='1'
),
multi_item_orders AS (
SELECT event_time, user_id,
JSON_VALUE(event_properties,'$.order_id') AS order_id,
item.item_category, item.item_brand, item.item_name, item.item_id, item.item_price
FROM amplitude_test.EVENTS_353961,
UNNEST(
ARRAY(
SELECT AS STRUCT
item_category, item_name, item_id, item_price, item_brand
FROM
UNNEST(JSON_VALUE_ARRAY(event_properties,'$.item_id')) AS item_id WITH OFFSET AS pos
JOIN UNNEST(JSON_VALUE_ARRAY(event_properties,'$.item_category')) AS item_category WITH OFFSET AS pos_cat ON pos = pos_cat
JOIN UNNEST(JSON_VALUE_ARRAY(event_properties,'$.item_brand')) AS item_brand WITH OFFSET AS pos_br ON pos = pos_br
JOIN UNNEST(JSON_VALUE_ARRAY(event_properties,'$.item_name')) AS item_name WITH OFFSET AS pos_name ON pos = pos_name
JOIN UNNEST(JSON_VALUE_ARRAY(event_properties,'$.item_price')) AS item_price WITH OFFSET AS pos_price ON pos = pos_price
)
) AS item
WHERE
JSON_VALUE(event_properties,'$.total_order_items_quantity')!='1'
)
-- 아이템 수량= 1인 경우의 결과와 아이템 수량= 2 이상인 경우의 결과를 합치기
SELECT *
FROM single_item_orders
UNION ALL
SELECT *
FROM multi_item_orders;
해당 작업을 완료한 결과는 다음과 같습니다.

UNNEST()함수를 포함한 단계를 거쳐 데이터 전처리를 진행할 경우 JSON을 데이터 프레임 형태, 즉 테이블 형식으로 바꾸는 것은 가능했습니다.
좀 더 직관적으로 UNNEST()함수를 이해하기 위해 예시를 들어보겠습니다. name이라는 컬럼은 값이지만, preferred langauge는 배열일 경우 빅쿼리는 테이블을 왼쪽처럼 인식합니다. 즉 값으로 구성된 행에 배열로 구성된 행을 묶어두는 구조인데요, 이 묶어둔다라는 것을 nest된 상태라고 하고, 값을 배열에 맞춰서 풀어주는 행위를 unnest라고 합니다.

하지만 UNNEST()함수를 사용할 경우 단점이 있었습니다.이 함수는 배열 내 각 요소를 별도의 행으로 확장하는 기능을 제공하기 때문에 비정규화된 데이터나 중첩된 데이터 구조를 다룰 때 필수적입니다. 그러나 비용관리의 관점에서 주의가 필요하다는 단점이 있습니다. UNNEST() 함수는 배열 내의 각 요소를 별도의 행으로 확장하기 때문에 배열에 많은 요소가 포함되어 있을 경우, 결과 데이터 세트의 크기가 급격히 증가할 수 있습니다. 이는 쿼리 처리 시간을 늘리고 처리해야 할 데이터 양이 증가함으로써 비용이 증가하는 원인이 될 수 있으며, 처리한 데이터 양에 따라 비용이 청구되는 빅쿼리에서는 쿼리 비용의 증가로 이어질 수 있습니다.
실제 프로젝트를 진행하면서 해당 쿼리문을 사용해 약 한달 간 매 시간마다 업데이트 되도록 쿼리를 돌려본 데이터 업데이트를 진행한 결과, 총 8GB를 사용해 월 40만원 가량의 비용이 소진되었습니다. 따라서 비용 효율성 측면을 고려해 전처리를 클라우드 SQL구문이 아닌 파이썬 코드로 처리하도록 우회했습니다.
앰플리튜드의 데이터를 빅쿼리로 바로 내보내는 것이 아니라 앰플리튜드 서버를 호출하여 데이터를 받아오는 방식으로, 빅쿼리에서 로우 데이터를 쌓은 후 이를 전처리하는 방식 대신 전처리를 완료한 후 가공된 데이터를 빅쿼리에 쌓는 방식으로 변경했습니다.
즉, 기존 Amplitude → Bigquery → Tableau의 단계에서 데이터 전처리를 위해 Google Cloud Storage를 추가한 Amplitude → Google Cloud Storage → Bigquery → Tableau 단계로 진행됩니다.

이 작업을 위해서는 우선 앰플리튜드와 Google Cloude Storage를 연결하는 작업을 진행해주어야 합니다. 먼저 Cloud Storage에서 고객사 프로젝트 관련 Bucket을 생성합니다.


다음으로 IAM 및 관리자 → 서비스 계정을 클릭하여 새로운 서비스 계정을 생성합니다.

서비스 계정을 생성한 후, 해당 서비스 계정에 해당하는 이메일을 확인합니다.

키 → 키 추가를 클릭하여 키를 생성합니다.


IAM 및 관리자 → 역할을 클릭하여 새로운 역할을 생성합니다. Send Amplitude Event Data to Google Cloud Storage(문서링크)를 참고해서 역할에 다음 5개의 권한을 부여해줍니다.

앞서 생성한 버킷으로 돌아가서 권한을 클릭한 후 액세스 권한 부여를 클릭합니다.

서비스 계정에서 추가한 새로운 계정에 해당하는 이메일을 입력한 후, 역할을 지정해줍니다.이때 역할은 1.저장소 기존 버킷 소유자와 2.역할 만들기를 통해 생성한 역할, 총 2개를 부여해줍니다.

해당 작업까지 완료했으면 앰플리튜드에서 Google Cloude Storage를 연결하는 작업을 진행해주어야 합니다. 앰플리튜드 Data → Destination에서 Google Cloud Storage를 클한 후 GCS로 보낼 데이터를 선택합니다.

서비스 계정 생성에서 생성한 JSON키 파일을 Service Account Key에 업로드 한 후, 하단의 Bucket Name에 구글 GCS에서 생성한 버킷 이름을 입력해줍니다.

해당 과정을 성공적으로 마치면 Google Cloud Storage Bucket에 데이터가 들어옵니다.

연동이 완료되면 다음과 같이 생성됩니다.

앰플리튜드는 export API라는 서비스를 제공하므로 이 API를 호출하여 데이터를 불러올 수 있습니다. 파이썬의 request모듈로 API요청을 보내는 함수를 구현하고, 다음으로 데이터 전처리 모듈은 pandas모듈을 활용하여 JSON 포맷을 테이블 형식의 데이터 프레임으로 전처리했습니다. 1차 시도당시 빅쿼리로 진행했던 조건문을 프로그래밍 언어로 대체한 것입니다. 마지막으로 빅쿼리 클라이언트 라이브러리를 설치하여 전처리한 테이블을 빅쿼리로 업로드하는 함수를 구현했습니다.
내용을 요약하면 다음과 같습니다.
1. 앰플리튜드
2. GCS
3. GCF
ㅤ: 버킷에 객체가 생성될 때마다 객체 데이터를 전처리한 후, 빅쿼리에 로드하는 함수 구현
해당 작업을 완료하면, 최종적으로 빅쿼리에 데이터가 정상적으로 저장되며, 태블로에 연결해서 시각화할 수 있습니다.

통합 프로모션 대시보드이므로 프로모션 간의 비교가 가능하도록 하는 것이 최우선순위 목표였습니다. 하지만 통합 프로모션 대시보드 내에서 개별 프로모션의 성과 및 관련 내용도 바로 파악이 가능하도록 대시보드를 구성하고자 했습니다.
프로모션 리스트 부분에서 프로모션 성과들을 직관적으로 비교해서 확인할 수 있도록 했으며, sales summary내의 각 KPI의 프로모션 평균값을 제공하여 프로모션의 평균값과의 비교가능하게함으로써 프로모션 간의 비교 분석이 가능하도록 대시보드를 구성했습니다. 또한 프로모션 리스트에서 개별 프로모션 클릭 시 해당 프로모션에 해당하는 내용으로 필터링이되어 표현되게함으로써 개별 프로모션의 성과 역시 파악할 수 있도록 대시보드를 구성했습니다.
데이터를 태블로로 넘긴 후 ERP 기준 매출 데이터와 정합성을 확인하는 과정에서 매출액의 약 0.2%의 차이가 발생함을 확인했습니다. 이는 최종 매출액에서 반품 및 교환 비용을 고려하지 못했기 때문에 발생한 결과였습니다.
따라서 앰플리튜드의 반품 및 교환관련 이벤트인 return_completed의 return_paid_shipping(교환 및 환불금액)관련 항목을 추가하여 해당 금액을 반영해줌으로써 데이터 정합성을 맞췄습니다.

해당 대시보드를 사용하는 고객사는 프로모션의 분류를 크게 할인과 쿠폰 2가지로 구분하고 있습니다.
즉, 1차적으로 가격을 낮춰 세일가에 제품을 구매하는 ‘할인’ 프로모션과 쿠폰을 소지하고 있는 고객이 쿠폰을 직접 사용해서 제품을 구매하는 ‘쿠폰’ 프로모션이 존재합니다. 이때 쿠폰 프로모션의 경우 총 매출 관련 항목과 쿠폰 매출 관련 항목으로 구분해서 성과를 확인할 수 있지만, 할인 프로모션의 경우 쿠폰 관련값이 존재하지 않으므로 쿠폰 매출 관련 성과는 확인이 불가능합니다. 따라서 성과를 확인함에 있어서 쿠폰 프로모션의 경우에는 쿠폰 매출 관련 항목을 확인해야 하고, 할인 프로모션의 경우에는 총 매출 관련 항목을 확인해야 합니다.
이를 적용했을 때 Sales Summary를 확인함에 있어서 결제상품수, 결제건수, 구매고객수의 경우 할인 프로모션의 경우에는 총 매출액 관련 항목으로, 쿠폰 프로모션의 경우에는 쿠폰 매출액 관련 항목으로 구분해서 표현해주어야 합니다.

이를 위해 케이스를 나누고, 쿠폰 아이디가 존재할 경우 쿠폰 프로모션으로 판단해서 쿠폰 매출 관련으로 카운트 하고, 쿠폰 아이디가 존재하지 않을 경우 할인 프로모션으로 판단해서 총 매출 관련항목으로 카운트할 수 있도록 계산된 필드를 생성합니다.
SQL
-- 결제상품수 예시
{FIXED [Promotion name1],[Classification],[Coupon Id]:
SUM(IF [Classification]='쿠폰' and ([# COUPON ID_1]= [Coupon Id]
OR [# COUPON ID_2]= [Coupon Id] OR [# COUPON ID_3]= [Coupon Id])
THEN 1
ELSEIF [Classification]='할인' THEN 1
END)}
최종적으로 제작된 통합 프로모션 대시보드는 다음과 같습니다.

대시보드 작동예시를 좀 더 자세히 살펴보면 다음과 같습니다.
1. Promotion List

Promotion List 우측 분류 및 테마 필터를 클릭하여 해당하는 프로모션을 확인할 수 있습니다.

2.Sales(sales summary)
해당 프로모션의 총 매출액, 쿠폰 매출액, 결제 상품수, 결제 건수, 구매고객수 및 각 항목에 해당하는 일평균 액수를 확인할 수 있습니다.

3. Item datail
좌측의 브랜드별, 카테고리별, 상품별 차트를 클릭해 각 항목에 해당하는 상품의 일자별 판매 현황을 확인할 수 있습니다.


우측 막대그래프에 마우스를 오버하면, 각 일자별 총 매출 및 쿠폰 매출, 총 매출 대비 쿠폰 매출 비율을 확인할 수 있습니다.

4. Sale Trend & 5.CRM Info
4. Sale Trend에서 프로모션 기간 동안의 총 매출 및 쿠폰 매출, 해당 기간 동안 CRM이 발송된 날짜에 대한 정보를 확인할 수 있습니다.

5.CRM Info에서 해당 CRM에 대한 세부 정보를 확인할 수 있습니다.


July 17, 2024
업무 시간을 데이터 수집과 데이터 전처리에 시간을 쓰는 마케터와 데이터 수집 자동화된 환경에서 성과 분석과 기획에 더 많은 시간을 쓰는 마케터 누가 더 많이 성장할까요?
답은 알고 계실 거에요. 당연히 성과 분석과 기획에 더 많은 시간을 쏟는 마케터가 장기적으로 많은 성장을 하겠죠
회사 내에서 GA4, MMP(AppsFlyer), Braze를 사용하고 있는데 엑셀로 데이터 수집해서 가공하는 시간을 대부분을 사용하고 있다면.. 하루 빨리 마케팅 데이터 수집 자동화하고 BI 구축을 시도해보세요.
관련 주제는 내용이 많기도 해서 3개로 나눠서 발행할 예정입니다.
이번 편에서는 MMP(AppsFlyer), GA4, Braze 데이터 수집을 자동화 시키는 프로세스를 설명해보려고 합니다.
데이터를 적재하고 시각화까지의 프로세스를 간단하게 도식화하면 아래와 같습니다.

브레이즈 currents 는 유저의 engagement 이벤트의 실시간 데이터 스트림입니다. 이 데이터를 Avro 파일로 제공해서 BI 및 분석 할 수 있게 지원을 해주는 장점이 있습니다. 단점은 가격이..
브레이즈 어드민에서 아래처럼 어떤 데이터를 보낼지 선택해서 어디에 저장할지 S3, Cloud Storage, Azure Blob Storage 중 선택해서 적재를 시작합니다. (가이드 링크)

예를 들어 Amazon S3 적재를 시작하게 되면 아래처럼 이벤트 별로 폴더가 생성되어 분리 적재됩니다.
브레이즈 Currents 는 At-least-once delivery 정책으로 1시간 단위로 데이터를 적재합니다.

각 폴더 안에는 Avro 파일(각 파일의 Schema는 동일한 형태)이 들어 있는데 이 파일 내에는 이벤트를 구분하는 필드가 없습니다.
일단 여기서 필요한 이벤트 데이터들을 지정해서 합쳐야 되는데 여기서 문제가 있습니다.
그래서 파일 안에 어떤 이벤트의 파일인지 지정해줘야 합니다.
아래와 같이 Avro 파일 명을 확인하여 event_type 필드의 key 값을 추가 필요합니다.

앱 데이터를 측정하는 앱스플라이어도 마찬가지로 데일리 리포트를 만드려면 OS별, UA, RT(리타겟팅)별로 csv 파일을 12번 클릭해서 받아 정리해야 되지만 API 를 활용하면 충분히 자동화 할 수 있습니다.

다만 앱스플라이어 데이터를 어떻게 볼지 기준에 대한 합의를 유관 부서와 먼저 하시는 걸 권장드리고 대행사에게도 우리 기준으로 맞춰 달라고 요청을 해야 되겠죠?
이런 기준으로 데이터를 쌓고 있었는데 데이터를 집계하는 기준이 서로 차이가 있다면 .. 다시 작업해야 되는 불상사가 생길 수 있습니다.
이게 무슨 말이냐면 앱스플라이어 Media Source 중 SRN 매체들의 경우 개인정보 보호 이슈로 rawdata에 포함되지 않아서 집약형 데이터를 활용합니다.(가이드 링크)
그래서 SRN 매체를 사용 중이시라면 집약형 데이터를 활용해서 집계를 해야 하는데 집약형 데이터는 LTV 데이터라서 조회 시점마다 Total Revenue 값이 달라집니다. (관련글 보러가기 링크)

1/1 데이터를 1/7일에 조회했을 때랑 1/14일에 조회했을 때의 total revenue가 달라진다는 의미입니다. 이러게 되면 가장 최근에 조회한 일자일 수록 ROAS가 높게 나오겠죠?
또한 skan 리포트도 마찬가지로 SRN 매체 광고를 운영 중에 있다면 해당 리포트도 받아야겠죠? 이것도 마찬가지로 조회시점마다 성과 숫자가 달라질 수 있습니다
앱스플라이어 데이터 자동화 수집을 위해선 크게 3가지 api 가 필요하고 세부적으로는 인스톨과 인앱이벤트 데이터를 가져와야 합니다. (추후에 앱스플라이어 데이터를 전처리하는 방법에 대해서 포스팅 해보겠습니다.)
GA4 빅쿼리는 실무에서 쓰고 있는 조직이 있나 싶을 정도로 .. 사용하기가 좀 꺼려집니다. 원시 데이터라서 데이터 가공의 자유도가 엄청나게 높지만.. 집계를 하는 입장에서는 굉장히 머리 아픕니다. 정합성을 어디다가 맞춰야 되는지..

그래서 광고 데이터 성과를 집계할 때는 특별한 이유가 없다면 GA4 API 데이터를 소싱하는 게 정합성 의심의 여지가 없기 때문에 무조건 낫다고 봅니다.
GA4 데이터를 소싱할 때 진짜 진짜 주의해야 할 점이 바로 샘플링입니다.
샘플링 진짜 …. 데이터량이 많으면 더 심해집니다.

GA4 API 를 14일치만 호출해도 샘플링된 양이 상당합니다.

GA4 Query Explorer 에서도 조회해도 어드민이랑 큰 차이가 있어서 구글 측에 문의를 해보니 여기도 데이터 조회 일자 범위가 넓으면 샘플링이 적용된다고 합니다. 추후에 해당 이슈 해소하겠다고 합니다.

일단 우리는 샘플링 되지 않을 정도의 날짜 범위로 api 를 호출해서 적재를 하는 것이 좋습니다.
이번 편은 마케팅 데이터 수집 자동화에 대해서 알아보았고 다음 편에서는 인사이트 도출을 위한 데이터 전처리 방법에 대해서 알아보겠습니다!

