
February 4, 2026

MCP(Model Context Protocol)는 AI가 외부 데이터를 활용할 수 있도록 연결해 주는 개방형 표준 프로토콜입니다. 쉽게 말해, AI 도구가 실시간으로 필요한 데이터를 가져와 활용할 수 있게 만드는 기술입니다.
앱스플라이어는 이 기술을 활용해 자연어만으로 마케팅 데이터에 바로 접근 가능한 MCP를 선보였습니다. Claude, ChatGPT 같은 AI 도구와 앱스플라이어를 연결하면, 캠페인 성과 분석부터 오디언스 관리, 딥링크 문제 해결까지 질문만으로 처리할 수 있습니다.
또한 앱스플라이어 MCP는 기술적 배경과 관계없이 누구나 필요한 데이터를 즉시 확인할 수 있도록 지원합니다. 사용자가 직접 질문하든, AI 에이전트에게 작업을 맡기든, 대기 시간 없이 명확한 정보와 실행 결과를 바로 받아볼 수 있습니다.
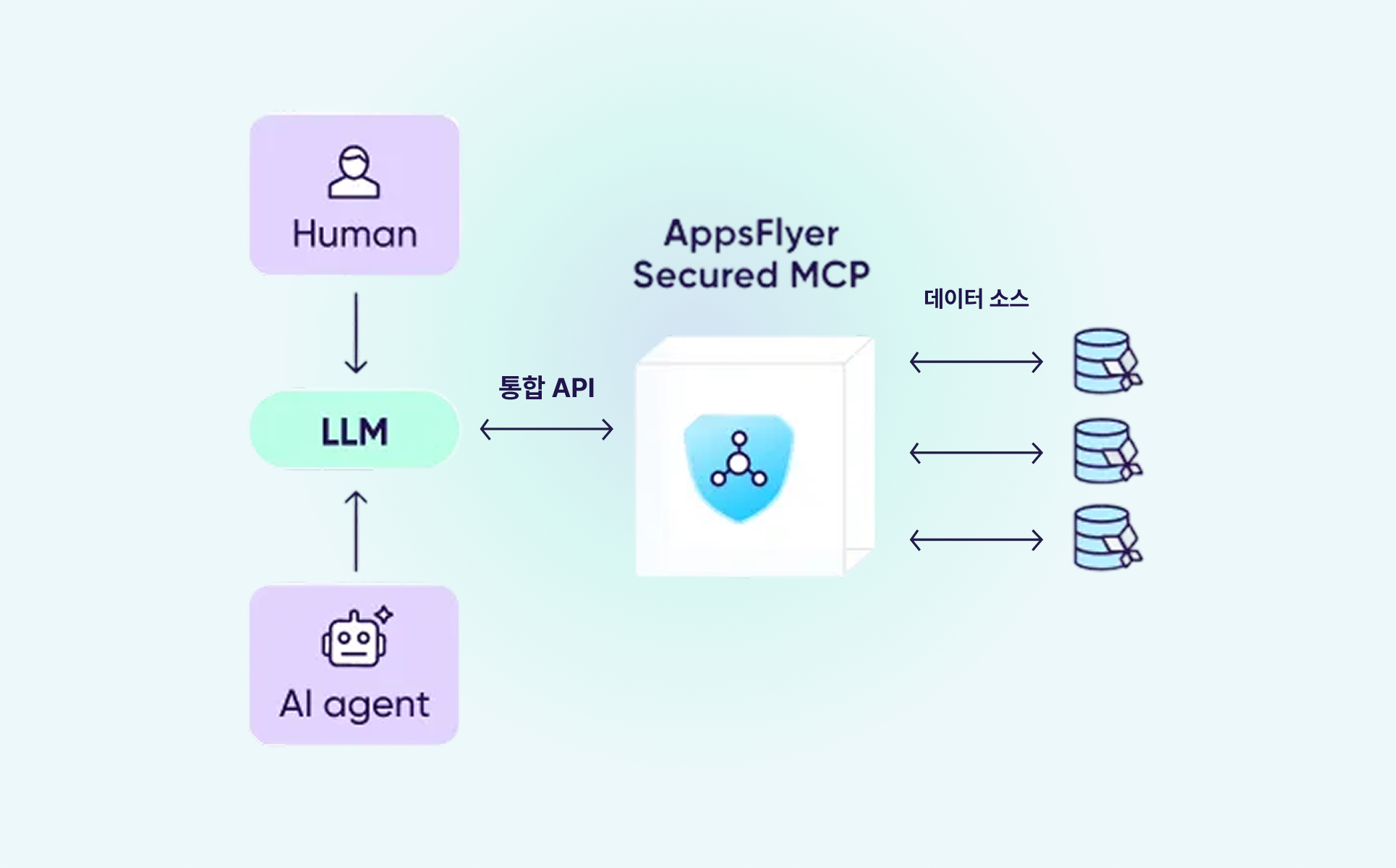
앱스플라이어 MCP는 Claude, ChatGPT, Gemini 같은 사용자가 선호하는 LLM(Large Language Model) 도구와 앱스플라이어를 연결합니다. 사용자가 질문을 입력하면 MCP가 자동으로 필요한 데이터를 찾아 이해하기 쉬운 형태로 보여줍니다. 어트리뷰션, 분석, 오디언스, OneLink(원링크) 등 앱스플라이어의 모든 기능을 자연어로 바로 활용할 수 있습니다.
또한 앱스플라이어는 7,000개 이상의 주요 브랜드가 신뢰하는 풍부하고 정확한 데이터를 제공하기 때문에 개인정보 보호를 철저히 준수하며 마케터가 필요한 인사이트를 즉시 확인하고 빠르게 의사결정을 내릴 수 있도록 돕습니다.
앱스플라이어 MCP는 개방형 구조로 설계되어 있어, 원하는 방식으로 커스터마이징할 수 있습니다. 미디어 믹스를 최적화하는 AI를 만들거나, 오디언스를 자동으로 관리하는 시스템을 구축하거나, 내부 도구에 MCP를 연결하는 등 복잡한 설정 없이도 필요한 기능을 유연하고 자유롭게 구현할 수 있습니다.
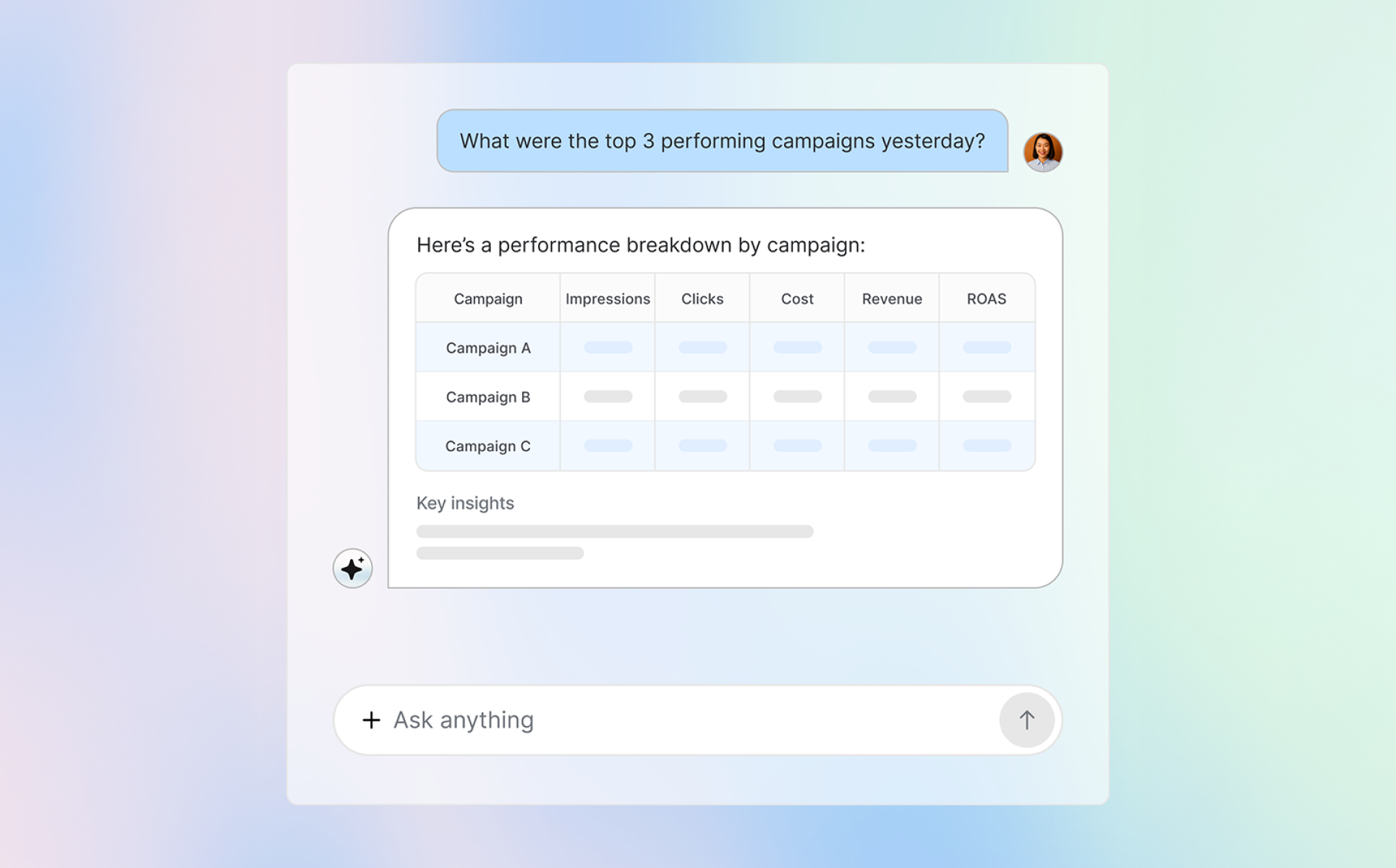
채널별 ROAS를 확인하고 싶거나, 어떤 캠페인이 가장 높은 LTV를 만드는지 알고 싶을 때 앱스플라이어 MCP를 활용해 보세요. 질문만 입력하면 필요한 데이터를 바로 확인할 수 있습니다.
앱스플라이어 MCP는 사람이 직접 질문하거나 AI 에이전트가 자동으로 작업하는 방식 모두 지원합니다. Growth, CRM, 제품, 마케팅 팀 등 어떤 팀이든 별도의 설정이나 개발 작업 없이 필요한 인사이트를 바로 확인할 수 있습니다.
앱스플라이어 MCP는 앱스플라이어의 어트리뷰션 기술을 기반으로 만들어졌습니다. 모든 데이터는 개인정보 보호 규정을 철저히 준수하며, 설계 단계부터 암호화와 보안을 적용했습니다.

캠페인 성과를 실시간으로 확인하고, ROI를 비교할 수 있습니다. 채팅창에서 직접 확인하거나, AI 에이전트를 활용해 성과 모니터링부터 최적화, 작업 실행까지 자동으로 처리하세요.
오디언스가 어떻게 나뉘고 활용되는지 한눈에 확인할 수 있습니다. 질문만으로 오디언스 현황을 조회하거나 실시간 성과를 분석할 수 있으며, 중복된 오디언스를 찾아내고 개선 방안을 제안하는 AI를 직접 만들 수도 있습니다. 필요하다면 여러 채널의 오디언스 정보를 자동으로 동기화하거나 작업을 실행할 수도 있습니다.
대화형 인터페이스로 OneLink 템플릿과 링크 동작을 간편하게 점검하거나, 에이전트를 활용해 링크 상태를 지속적으로 모니터링할 수 있습니다. 문제가 있는 링크를 자동으로 찾아내고, 모든 캠페인이 올바르게 운영되도록 관리할 수 있습니다.
앱 설정이나 구현 방법이 궁금할 때 질문만으로 바로 확인할 수 있습니다. AI 어시스턴트가 설정 오류를 찾아내 해결 방법을 알려주거나, 상황에 맞는 가이드 문서를 자동으로 보여줍니다.
앱스플라이어 MCP는 AI 기반 마케팅을 향한 중요한 첫걸음입니다. 사람의 창의성과 AI의 분석 능력이 결합되면, 마케터는 더 나은 의사결정을 내릴 수 있습니다.
MCP는 캠페인 분석, 오디언스 확인, 딥링크 관리 같은 마케터들의 핵심 업무를 지원하고 있으며, 추후 예측 분석과 에이전트 기반 자동화까지 확대 될 예정입니다. 데이터 기반으로 더 빠르고 정확한 의사결정을 내리고 싶다면, 지금 바로 앱스플라이어 MCP를 경험해 보세요.

|
앱스플라이어 도입을 고민중이라면?마티니는 앱스플라이어 도입부터 실무 활용까지 전 과정을 지원하는 풀퍼널 마케팅 에이전시입니다. 지금 아래 버튼을 눌러, 마티니와 만나보세요. |

January 9, 2026

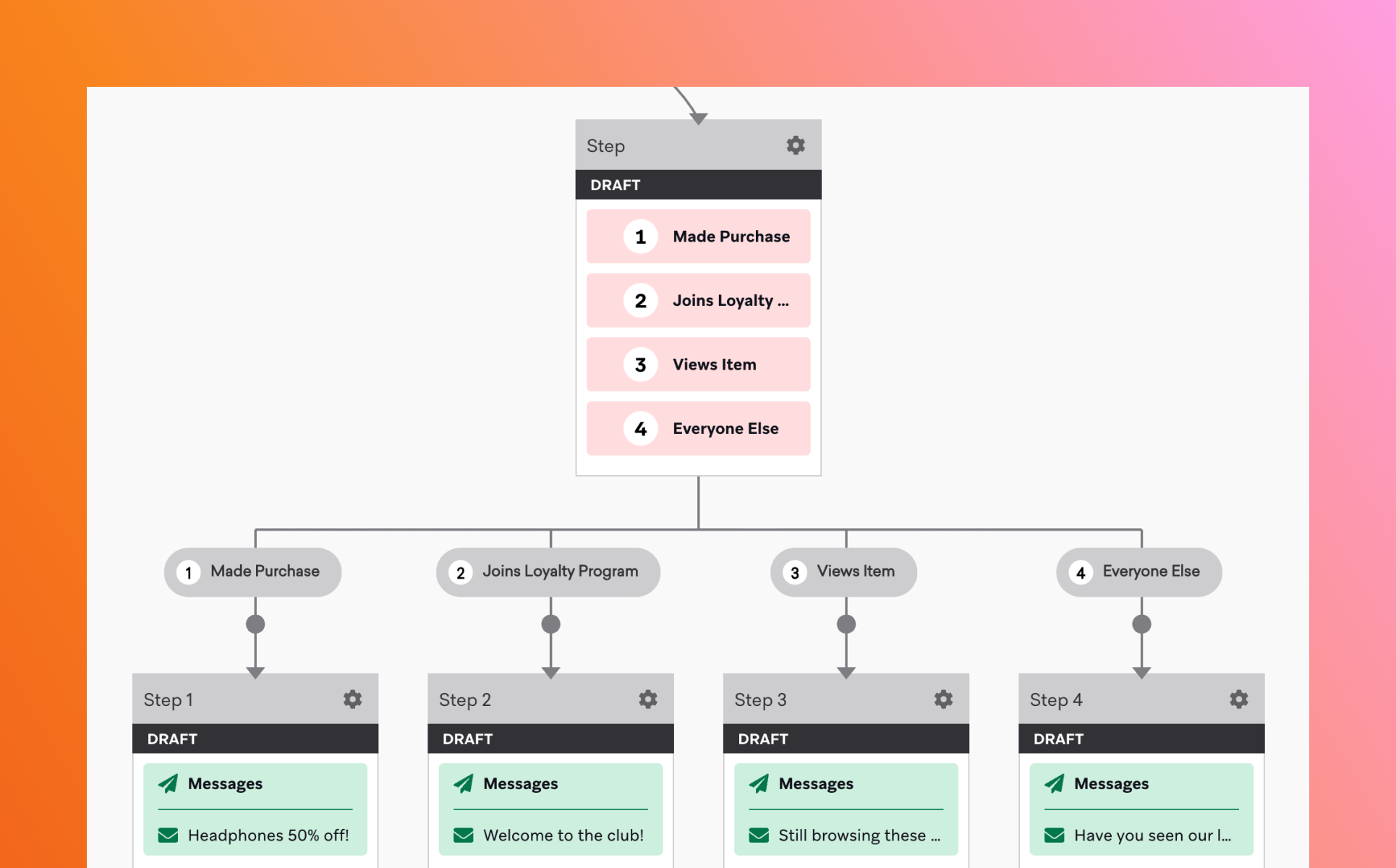
브레이즈 캔버스(Canvas)는 고객의 행동과 속성을 기준으로 개인화된 메시지 흐름을 설계하는 고객 여정 오케스트레이션 도구입니다. 단일 캠페인이 하나의 캠페인을 특정 조건에 따라 발송하는 데 초점을 맞춘다면, 캔버스는 고객의 행동에 따라 여러 메시지와 채널을 유기적으로 연결합니다.
예를 들어, 회원가입 후 7일까지의 유저 저니 설계, 첫 구매까지의 지속적인 구매 유도 메시지 발송 등 단일 순간에 그치지 않고 지속되는 기간 동안 유저 저니에 따라 메시지를 보낼 수 있습니다.
캔버스를 활용하면, CRM 마케팅을 ‘단발성 메시지 발송’에서, 지속적인 고객 경험 관리로 확장할 수 있습니다.
특히 고객 행동이 빠르게 변화하는 환경에서는, 잘 설계된 캔버스가 마케터의 반복적인 운영 부담을 크게 줄여줍니다.


브레이즈 캔버스는 크게 진입 조건(Entry), 액션(Step), 분기(Split)으로 이루어져 있습니다.
해당 속성을 잘 활용하면, CRM 마케터는 하나의 캔버스 안에서 다양한 시나리오를 운영할 수 있습니다. 그뿐만 아니라 고객의 입장에서도 ‘자연스러운 경험’이 가능해져 더 높은 전환 성과를 기대할 수도 있습니다.
브레이즈 캔버스는 강력한 도구이지만, 설계 목적이 명확하지 않으면 오히려 캠페인 운영이 복잡해질 수 있습니다. 하나의 캔버스에는 하나의 목표를 두고, 온보딩•전환•리텐션 등 목적별로 캔버스를 분리해 설계하는 것이 효과적입니다.
또한, 지나치게 많은 분기와 조건은 운영 중 오류나 누락을 유발할 수 있습니다. 초기에는 단순한 구조로 시작하고, 성과와 데이터를 기반으로 점진적으로 고도화하는 방법이 안정적입니다.
마지막으로 데이터 반영 시점을 고려하여 적절한 대기 시간과 조건을 설정해야 합니다.
캔버스는 한 번 만들고 끝나는 것이 아니라, 운영 후 지속적으로 점검하고 개선해야 성과로 이어집니다.
|
|
브레이즈, 믿을 수 있는
|

January 6, 2026
CRM 마케팅의 중요성이 높아지면서, 많은 기업에서 브레이즈(Braze)를 활용해 CRM 마케팅을 진행하고 있습니다. 간단하게는 푸시 메시지 발송부터, 깊게는 캠페인 자동화까지. 브레이즈는 많은 CRM 마케터들에게 익숙한 도구가 되었습니다. 하지만 실제로 현장에서 듣는 이야기는 조금 다릅니다.
“기능은 많은데, 어디까지 쓰고 있는지 모르겠다”
”이 정도면 잘 쓰고 있는 건지 감이 안 온다”
브레이즈를 사용하는 것과 잘 ‘활용’하는 것은 다른 문제이기 때문입니다.
마티니는 이러한 고민에서 출발해, 브레이즈 활용도를 자가진단 해볼 수 있는 질문을 마련했습니다. 자가진단의 목적은 단순히 점수를 매기는 것이 아니라, 현재 우리 팀의 CRM 운영이 어느 단계에 와 있는지, 그리고 다음 단계로 나아가기 위해 무엇이 필요한지를 스스로 인식할 수 있도록 돕는 데 있습니다.
실제로 자가진단에 참여한 기업들을 살펴보면, 캠페인과 자동화는 잘 운영되고 있지만, 데이터 활용, AI 기능, 신규 채널(RCS 등)은 아직 충분히 활용되지 못하고 있는 경우가 많았습니다.

브레이즈를 사용하고 있다면, 이제는 ‘얼마나 잘 활용하고 있는지’를 점검해야 할 시점입니다. 지금 바로 우리 팀의 브레이즈 활용도를 진단해 보세요.
자가진단 점수 구간에 따라 현재 브레이즈 활용도가 어느 수준인지 쉽게 확인해볼 수 있습니다. 결과 페이지에서는 현재 활용 단계에 따른 제안도 함께 확인해볼 수 있습니다.
마티니가 정리한 브레이즈 활용 인사이트와 실제 사례를 통해, CRM을 한 단계 더 고도화하는 방법을 확인해 보세요.

July 16, 2024
GA4 데이터를 빅쿼리로 보내면 뭐든 다 해결될 것 같은 이야기들이 많지만 실상은 그렇지 못합니다. GA4 인터페이스와 차이가 많고 많은 데이터 용량으로 ETL 과정으로 생각보다 리소스가 많이 듭니다. 그럼에도 불구하고 빅쿼리를 쓰는 이유가 뭘까요?


GA4 빅쿼리 데이터를 가공하다보면 어? 뭐지? 하는 현상들이 있는데 대표적인 하나의 케이스를 공유해볼까합니다. 바로! 빅쿼리에 저장되는 GA4 데이터에는 구글 관련 트래픽에 가장 큰 문제가 있다는 것입니다ㅜㅜ
gclid 파라미터(구글 애즈 캠페인으로 들어온 트래픽이라는 의미)가 있는 세션이 시작 되었을 때 빅쿼리는 utm_medium, utm_campaign 파라미터를 (organic)으로 기록해버립니다
다시 말하면 구글 애즈로 들어왔다는 데이터라고 식별은 되지만 캠페인 명이 증발해버리는 현상입니다.

with events as (
select
cast(event_date as date format 'YYYYMMDD') as date,
concat(user_pseudo_id, (select value.int_value from unnest(event_params) where key = 'ga_session_id')) as session_id,
user_pseudo_id,
(select value.int_value from unnest(event_params) where key = 'ga_session_id') as session_start,
if(
(select value.string_value from unnest(event_params) where key in ('campaign_id', 'campaign', 'source', 'medium', 'term', 'content', 'gclid', 'dclid', 'srsltid') and value.string_value is not null limit 1) is not null,
(
select as struct
(select value.string_value from unnest(event_params) where key = 'campaign_id') as manual_campaign_id,
(select value.string_value from unnest(event_params) where key = 'campaign') as manual_campaign_name,
(select value.string_value from unnest(event_params) where key = 'source') as manual_source,
(select value.string_value from unnest(event_params) where key = 'medium') as manual_medium,
(select value.string_value from unnest(event_params) where key = 'term') as manual_term,
(select value.string_value from unnest(event_params) where key = 'content') as manual_content,
(select value.string_value from unnest(event_params) where key = 'gclid') as gclid,
(select value.string_value from unnest(event_params) where key = 'dclid') as dclid,
(select value.string_value from unnest(event_params) where key = 'srsltid') as srsltid
),
null
) as collected_traffic_source,
event_timestamp,
stream_id,
(select value.string_value from unnest(event_params) where key = 'device_category') device_category,
event_name,
ecommerce.purchase_revenue_in_usd as purchase_revenue_in_usd,
case
when event_name = 'purchase'
then 1 else 0 end AS purchase
from
`테이블명`
where
_TABLE_SUFFIX >= '20231001' AND _TABLE_SUFFIX <= '20231001'
and (select value.string_value from unnest(event_params) where key = 'source') = 'google'
)
select * from events
order by session_id
이 현상을 해결하려면 UTM 파라미터를 자동 태깅(gclid)를 대신해서 사용하거나 URL에 커스텀 파라미터를 붙여서 해결할 수 있긴 합니다.
유저 레벨 분석이 아닌 마케팅 성과를 집계하기 위한 목적으로 GA4 데이터를 활용하고자 한다면 Bigquery Export 보다는 Google Analytics Data API 를 활용해서 일별로 내부 DataWarehouse에 저장하는 방식이 더 효율적일 것 같습니다.
참고로 Google Analytics Data API 를 활용한다면 집계된 데이터를 받아오기 때문에 Total Users 와 같은 유니크한 집계값 (Count Distinct)를 해야되는 지표는 제외하고 이벤트 단위의 지표만 활용해야합니다. 이유는 아래와 같습니다.
4명의 유저가 2024-01-01 ~ 2024-01-03 에 방문했습니다.(로우 데이터)

일별 Total User 를 집계해보면

전체 기간의 Total User 를 집계해보면

일별, 기간별 집계 했을 때 유니크 사용자수는 완전히 다릅니다. (DAU, MAU 개념과 동일)일별 테이블을 다 더해서 집계를 해서 사용하시면 쓸모없는 지표가 되어버리기 때문입니다.
그래도 유저레벨 단위로 혹은 GA4 인터페이스에서 처리 못하는 방식의 데이터 가공이 필요하다면 위의 케이스를 반드시 고려해서 빅쿼리를 사용하시는 걸 권장드립니다.
Why your BigQuery results don't (exactly) match with Google Analytics reports (GA4)

July 15, 2024

SEO 분석의 핵심 채널은 구글과 네이버 입니다. 그 중 구글에서는 사이트로 들어오는 유저의 검색 키워드를 분석 할 수 있게 도와주는 구글서치콘솔(GSC)을 제공하고 있습니다. 이를 통해 어떤 키워드가 더 노출과 클릭이 잘 되고 있는지 어떤 키워드가 문제인지를 확인할 수 있습니다.
다만 구글서치콘솔의 기본 목적은 구글이 도메인의 정보를 수집해가는 사이트맵 관리용으로 출발하다 보니 키워드별 깊이있는 통계 분석을 하기는 어렵습니다.
이로 인해 구글서치콘솔의 다소 부족한 통계를 보완하여 더 효과적인 구글 SEO 분석에 도움을 주기 위해 대시보드를 구성하였습니다. 총 4개의 영역으로 구성되어 있으며 각 대시보드의 활용 방식은 아래와 같습니다. SEO 관리를 위해 분석하면 좋을 지표와 방식들에 집중해서 같이 살펴보시면 좋을 것 같습니다.





July 12, 2024

데이터를 구성하는 형식은 크게 Long format data와 Wide format data로 구분할 수 있습니다.
각 유형 별 특징 및 장단점에 대해 살펴보겠습니다.
Wide Format Data는 각 주제 또는 관찰단위가 단일 행으로 표시되는 구조입니다.

특징:
사용시 장점:

특징:
사용시 장점:
Wide Format 데이터를 태블로에 입력하면 학생Id는 차원에, 점수관련 항목은 측정값으로 구분됩니다.
이를 활용해 하나의 테이블을 생성하기 위해서는 점수관련 항목을 모두 선택해주어야합니다.

반면 Long Format 데이터를 태블로에 입력하면 학생Id와 시험 항목은 차원에, 점수는 측정값으로 구분됩니다. 이를 활용해 하나의 테이블을 생성하기 위해서는 열에 시험 차원을, 행에 학생 Id차원을 올려놓은 후 점수 값을 표에 입력하면 됩니다.

다음은 해당 데이터들을 활용해 그래프를 생성해보겠습니다.
먼저 Wide Format 데이터의 경우 국어시험, 수학시험, 영어시험은 각각 다른 차원에 존재하는 데이터이므로 이를 하나로 합친 차트를 구현하는 것은 불가능합니다.

반면 Long Format 데이터의 경우, 시험이라는 하나의 차원을 기준으로 점수라는 측정값이 적재되어 있기때문에 해당 데이터를 이용해서는 하나의 차트 내에서 3가지 항목을 구분하여 구현할 수 있습니다.

→ 따라서 Tableau를 활용하여 시각화를 구현할 때에는 Long Format형식의 데이터를 사용하는 것이 더욱더 다양한 시각화가 가능합니다.

July 10, 2024


이번 글에서는 Udemy교육 플랫폼에 대한 분석과 해당 분석을 바탕으로한 대시보드를 그려보려고 합니다. 교육관련 비즈니스나 지식 기반 서비스 운영하는 경우 해당 분석과 대시보드가 참고가 될 수 있을 것입니다.
Kaggle에 올라와 있는 Udemy 데이터를 활용하여 분석을 진행하였습니다. 혹시 데이터가 필요한 분들은 아래 링크를 참고해주세요.

Udemy는 글로벌 교육 커머스 플랫폼 입니다. 마케팅이나 데이터 분석 뿐 아니라 개발, 라이프스타일, 비즈니스 등 다양한 분야의 강의들이 판매되고 있습니다. 가격이 그렇게 부담되지 않기 때문에 기회가 되신 다면 한번 들어보시면 좋을듯합니다. 다양한 국가 언어를 제공해 주지만 한글 비율은 높은편은 압니다. 다만 대부분 자막을 제공해주기 때문에 어렵지 않게 양질의 자료들을 보실 수 있습니다.

국내에서 Udemy와 비슷한 비즈니스 모델로는 패스트캠퍼스, 클래스 101, 인프런 같은 서비스가 있습니다.

지식 기반 상품을 판매하는 이러한 비즈니스 모델의 특징은 커머스와 크게 다르지 않습니다. 다양한 주제(카테고리 & 브랜드)의 강의(상품)가 있고 고객이 원하는 강의가 있다면 개별 강의를 구매하는 방식으로 구매 여정이 이루어져 있습니다.
일반 상품과 다르게 무형의 상품이다보니 체험 형식의 무료 과정이 활발하게 활용되는 편입니다. 강좌 개설도 자유롭게 할 수 있으며, 강좌에 대한 홍보도 직접 진행할 수 있다보니 스마트스토어에 상품을 직접올려서 판매하는 오픈마켓의 방식과 거의 유사합니다.
해당 분석의 목표는 강좌를 만드는 강의자와 Udemy에서 강좌를 서포트하는 매니저가 사용 할 수 있는 분석과 대시보드 제작을 목적으로 진행하려고합니다. 이를 통해 주요 인기 카테고리와 상위 강좌로 올라가기 위한 조건이나 기준들을 살펴보도록 하겠습니다.
데이터 세트는 총 12개 항목(컬럼)으로 이루어져 있습니다.

데이터 수는 3682개로 이루어져 있습니다.
EDA를 통해 기본적으로 데이터의 모양을 살펴보고, 데이터 특징을 파악하며 데이터 퀄리티를 높이는 작업을 합니다.
EDA 진행 전 필수적으로 확인해야하는 단계가 데이터 퀄리티 확인 단계입니다. 이는 '데이터 클리닝' 이라고도 부르는 단계로 데이터 결측치, 데이터 중복, 이상치를 확인하는 단계 입니다. 실제로 해당 Raw 데이터는 결측치가 있는 데이터로 적절한 결측치 처리가 필요하였습니다. 이번 데이터는 결측치가 6개 row에서 발견되어 해당 row를 제거하는 방식으로 진행하였습니다. 만약 결측치가 많다면 보간 방식으로 데이터를 적절하게 채워 분석을 진행할 수 있습니다.
EDA를 통해 몇가지 특징을 확인할 수 있었습니다.


앞서 진행한 EDA 과정을 통해 분석 대시보드는 주요 지표를 보여주는 Overview와 주요 지표를 드릴다운해서 볼 수 있는 개별 영역으로 나누어서 구성하였습니다.
각 화면별 자세한 구성은 아래와 같습니다.
개요 대시보드의 구성은 대부분 유사하게 구성합니다.

주요 KPI와 해당 KPI의 시간별 퍼포먼스를 볼 수 있는 영역을 기본으로 구성합니다. 이외에 주요 지표 구성 요소를 배치하여 가볍게 드릴 다운 해서 볼 수 있는 구성을 합니다.
시간에따른 KPI 성과 영역은 선택 측정항목 기능을 활용하여 측정항목을 자유롭게 변경하며 분석하거나 기간 단위를 일 -> 주 -> 월 로 변경하면서 트렌드를 다양하게 확인할 수 있게 구성하였습니다.
커머스로 비유하면 교육 산업에서 구독자는 구매자와 동일합니다. 다만 서비스하는 교육과정이 많다보니 적정한 기준으로 교육과정을 나누어 과정 별 특징을 확인하면 분석 편의성을 높일 수 있습니다.
가장 간단한 그룹화 방법 중 하나는 파레토 법칙을 이용하는 방식입니다. 아래 그림과 같이 가장 많은 교육과정 or 상위 10% 기준을 확인한다면 새롭게 강의를 런칭하는 신규 강사의 입장에서 바라봐야할 목표 지표를 세울 수 있습니다.

교육 산업의 특징 중 하나는 무료 강의를 통해 플랫폼에 대한 인지를 높이는 전략을 가져가는 것입니다. Udemy 또한 평균 10% 내외의 무료 강의 비율을 보이고 있습니다. 강의 수는 10% 내 외이지만 실제 해당 무료 과정을 통해 플랫폼 경험을 하는 유저 수는 30% 이상 될 정도로 무료 과정은 중요한 역할을 하고 있습니다.

상품을 구매하는데 있어 중요한 항목 중 하나는 누군가의 추천입니다. 공급자는 대부분 상품의 좋은 점을 강조하기 때문에 다른 유사 상품과의 차이가 두드러지지 않습니다. 특히나 비슷한 주제의 강의라면 커리큘럼과 실습방식 외 나머지 강의 요소를 상세페이지에 표현하기 어렵습니다. 강의 전달 방식이나 강의자의 톤, 발성, 논리정연한 강의력 등 실제 강의를 들은 수강생의 생생한 후기는 많은 경우 구매 전환에 매우 큰 영향을 줍니다. 실제로 리뷰와 수강생의 상관도가 높은 것으로 확인되며 상위 5% 강의의 리뷰율은 다른 하위 강의 대비 2배 가까이 높은것을 알 수 있습니다.
카테고리 또는 레벨, 유무료 별 평균 리뷰율을 알았다면 특정 강의의 매출을 높이는 데 있어 하나의 기준이 될 수 있습니다. 평균 대비 리뷰율이 낮다면 단기적으로 리뷰를 높이는 이벤트를 열거나 리뷰가 낮은 부분을 피드백하며 강의 자체의 개선에 활용하는 방식을 가져갈 수 있습니다.

어떤 카테고리가 현재 인기 있는지 알 수 있습니다. 카테고리에 상관없이 Beginner or All level이 개설 과정수도 많고 매출 비율도 높습니다. 레벨이 올라갈수록 타겟 가능한 사람을 찾는 것도 어렵고 해당 타겟의 구매 전환도 낮은편입니다. 실제로 강사의 입장에서도 레벨이 높아질수록 강의 준비 과정 난이도가 높아지기 때문에 낮은 레벨을 더 선호하는 편입니다.
카테고리 & 레벨 별로 현재 비어있는 과정을 보면서 전략적으로 강의를 개설할 수 있습니다.

앞서 파레토 법칙에 따라 구독자수 기준 상위 5%, 10%, 20%, 50%, 기타 그룹으로 계급을 나누었습니다. 그리고 상위 그룹과 리뷰의 상관도가 높은 것을 알 수 있었습니다. 즉, 상위 그룹에 올라가기 위해서는 필수적으로 수강생 리뷰가 쌓이고 구매 선순환이 이루어지는 시간이 필요합니다. 따라서 계급별 평균 개설 시간을 보면서 상위 계급에 올라가기 위해 얼마 만큼의 기간이 필요한지 대략적으로 가늠할 수 있습니다.
또한 계급별 주요 지표간 상관도를 보면서 어떤 지표를 우선으로 해서 강의를 만들지 전략적으로 접근할 수 있습니다. 실제 계급 구독수와 강의수 & 강의시간의 상관도가 높은것을 알 수 있습니다.
반대로 구독자수와 강의가격은 생각보다 높은 상관도를 보이지 않습니다. 충분히 유용한 강의수와 시간을 보유하고 있다면 강의 가격은 구매 결정에 상대적으로 낮은 영향력을 보입니다.
해당 글에서 예시로 활용한 데이터는 과거의 데이터다보니 앞서 도출한 인사이트가 현재 강의 환경과 맞지 않을 수 있습니다. 다만, 분석 과정과 주요 지표 표현 방식 등은 충분히 유효합니다. 앞서 서두에 설명 한 것 처럼 지식 기반 비즈니스가 아닌 일반 커머스 비지니스에서도 해당 분석 흐름과 대시보드 구성을 참고해서 활용해보시면 좋을 것 같습니다.

July 10, 2024
리텐션(Retention)은 고객이나 사용자가 특정 기간 동안 어떤 제품이나 서비스에 계속 관여하거나 이용하는 비율을 말합니다. 즉, 얼마나 많은 사용자가 시간이 지남에 따라 제품이나 서비스를 계속 사용하는지를 나타내는 지표입니다. 높은 리텐션율은 고객 충성도가 높고, 제품이나 서비스에 대한 만족도가 높음을 의미합니다.
리텐션을 지속적으로 측정하고 관리하는 것이 중요한 이유는 여러가지가 있습니다. 리텐션은 단순히 고객이 제품이나 서비스를 계속 사용하는 것을 넘어서 기업의 지속가능성과 직접적으로 연결되는 핵심 지표입니다. 리텐션이 중요한 이유를 좀 더 자세히 살펴보면 다음과 같습니다.
리텐션을 측정하는 기준에는 다양한 방법이 존재합니다. 그 중 Amplitude에서 확인할 수 있는 리텐션의 종류인 ‘N-day Retention’과 ‘Unbounded Retention’에 대해 좀 더 자세히 알아보려고 합니다.


N-day Retention은 사용자가 처음 제품이나 서비스를 이용한 후 특정 일수(N일) 후에도 계속 이용하는지를 측정하는 방법입니다. 예를 들어, 7-day Retention은 사용자가 서비스를 처음 이용한 후 7일째 되는 날에도 서비스를 이용하는 비율을 의미합니다. 해당 리텐션은 초기 사용자 참여, 온보딩, 새로운 기능, 단기 마케팅 캠페인 분석을 위해 사용됩니다.
Unbounded Retention은 특정 기간 동안 사용자가 최소 한 번이라도 제품이나 서비스를 이용했는지를 측정하는 방법입니다. 이 방법은 시간이 지나도 사용자가 이탈하지 않고 계속해서 제품을 사용했는지의 여부만을 고려합니다. 해당 리텐션은 장기적인 참여, 고객 충성도, 반복 구매, 주기적인 콘텐츠 업데이트 분석을 위해 사용됩니다.

리텐션 차트는 시간에 따른 사용자의 이탈 및 유지 패턴을 시각적으로 표현한 그래프입니다. 이 차트는 특정 기간 동안 사용자 그룹의 리텐션율 변화를 보여줍니다. 리텐션 차트를 통해 크게 행 기준 분석과 열 기준 분석을 수행할 수 있습니다.


리텐션 커브는 시간에 따른 리텐션율의 변화를 나타낸 것입니다. 이 커브는 초기 사용자 참여 이후 리텐션율의 감소 패턴을 한눈에 파악할 수 있게 해줍니다.
리텐션 커브는 감소형태에 따라 유형를 크게 3가지로 나눌 수 있습니다.

시간이 지남에 따라 사용자 참여가 감소되는 패턴의 커브입니다. 이는 가장 흔히 보이는 커브의 형태로, 초기참여 이후 사용자의 관심이 감소됨을 의미합니다.
초기 감소 후 리텐션율이 안정적으로 유지되는 패턴의 커브입니다. 이는 사용자들이 제품이나 서비스에 익숙해지고 일정수준의 참여를 계속해서 유지함을 나타냅니다.
리텐션 감소 후 시간이 지남에 따라 다시 증가하는 패턴의 커브입니다. 이는 매우 긍정적인 상황으로, 사용자들이 초기 이탈후 일정시간이 지나 다시 제품이나 서비스에 관심을 가지기 시작함을 의미합니다.

July 8, 2024
블로그를 하다보니 SEO에 대한 키워드 최적화와 분석을 많이 하고 있습니다.
그 중 최근 많이 활용하는 분석 방법 중 하나는 풍선 차트를 활용한 키워드 분석입니다.
풍선(버블) 차트는 여러개의 측정기준을 두고 분석할 수 있다보니, SEO 같이 단일 키워드 별로 다양한 측정기준 간 비교를 해야하는 경우 유용합니다.
아래는 풍선차트로 분석하는 SEO 예시입니다.

X축 : 클릭율(CTR)
Y축 : 노출 순위(Average position)
풍선크기 : 노출(Impression)
풍선색상 : 기기 카테고리(Device Category)
1. 날짜 필터SEO는 즉각적인 효과 분석보단 장기간에 걸친 데이터 분석이 필요합니다. 기간별 키워드 지표의 변화를 확인할 수 있습니다.
2. 검색어(Query)관리해야하는 키워드가 수 백개를 넘어갑니다. 관리 할 키워드가 많은 경우 노출이나 클릭 기준으로 키워드 필터를 걸어서 관리하면 편합니다.
3. 기기서비스의 특성에 따라 PC, MO 중 검색 선호 기기가 다른 경우가 많습니다.
4. 국가글로벌 서비스의 경우 국가별로 반응하는 키워드와 키워드별 지표 트렌드가 달라질 수 있습니다.
5. 최소노출량롱테일 키워드는 노출량이 적지만 키워드의 양이 많습니다. 따라서 최소 노출량 필터를 두어서 분석 편의성을 높일 수 있습니다.
6. 축 평균값각 축의 평균값 선을 두어서 평균값 기준 키워드 그룹을 4분면으로 나누어 관리할 수 있습니다.
7. Y축 역방향Y축은 평균 게재순위 입니다. 기본적으로 1에 가까울 수록 좋은 키워드 그룹이기 때문에 Y축 방향을 반전 시켜 1이 위쪽으로 배치될 수 있게 하면 분석 편의성을 가질 수 있습니다.
8. 로그 스케일키워드간 지표의 차이가 크게 발생하는 경우 로그 스케일을 사용하면 차트에 분포되어 있는 검색어를 더 쉽게 파악할 수 있습니다.
👉 관련 대시보드 : https://lnkd.in/gQQ9_8r7
분석은 축 평균 기준으로 4개 분면으로 키워드 그룹을 나누어 전략을 다르게 가져갈 수 있습니다.

1️사분면 : 노출순위가 높고, CTR도 우수한 유효 키워드 그룹
2️사분면 : 노출순위가 낮고, CTR은 높은 잠재 우수 키워드
3️사분면 : 노출순위도 낮고, CTR도 낮은 문제 키워드 그룹
4️사분면 : 노출순위가 높지만, CTR은 낮은 관리 필요 그룹
👉 자세한 SEO 분석 전략 : https://lnkd.in/gJDbrBzp

July 4, 2024
태그 설치를 끝낸 후 GA4 대시보드에서 데이터가 잘 수집되는 것을 확인했다면 이제 데이터 시각화 기능인 루커 대시보드와 연동하여 나만의 대시보드를 만들 수 있다.
GA4의 유입 데이터와 내부 데이터를 연동하여 한 화면에서 비즈니스 데이터를 확인할 수 있기 때문에 데이터 기반 인사이트를 용이하게 확인할 수 있다. 내 웹사이트에 어떤 경로로 들어왔는지, 어느 페이지에서 이탈률이 높은지, *스크롤은 몇 % 내리는지, 어느 광고 매체에서 구매 전환 혹은 매출이 많이 일어나는지 한 화면에서 확인이 가능하다.
그리고 루커 대시보드는 gmail 계정만 있으면 관련 담당자와 쉽게 공유할 수 있으므로 타 부서와 긴밀하게 매출과 비즈니스 KPI를 관리할 수 있다는 장점이 있다.
루커 대시보드에서 차트를 구현할 때 연동하는 데이터 세트를 ‘데이터 소스’라고 한다. 데이터 소스는 루커 스튜디오의 커넥터를 클릭하여 쉽게 연동이 가능한데, 루커는 무려 1,000개 이상의 다양한 데이터 소스를 간편하게 연동할 수 있도록 지원하고 있다. (연동 가능한 데이터 소스 종류 확인하기)
만약 내가 기존에 적재하고 있던 구글 시트 보고서의 데이터와 GA4 데이터를 기반으로 대시보드를 만들고자 한다면 구글시트와 GA4 계정을 커넥터에 연결해서 확인할 수 있다.

구글 시트 보고서와 GA4 데이터를 연결해야 하기문에 커넥터에서 ‘Google 애널리틱스’와 Google Sheet를 클릭하여 연동을 시작한다. 구글 시트는 워크시트별로 연동이 가능하고 GA4는 해당 계정에 대해 권한이 있어야 연동이 가능하다. 다만 이때 각 열의 헤더(제목)이 있어야 하고 헤더는 중복되면 안된다.

루커 스튜디오는 ‘보기’모드와 ‘수정’모드가 있다. 보기 모드는 편집자 권한이 없는 사람이 대시보드가 보이는 형태를 확인할 수 있고 편집자 모드가 있을 경우 ‘수정’모드에서 각 차트와 대시보드 스타일에 대한 요소들을 생성 및 수정할 수 있다.


수정 모드에서는 가장 우측 데이터, 속성, 필터 표시줄 이모티콘을 클릭함으로써 각 기능에 대한 툴바를 숨김 처리할 수 있다.

(상단 좌측부터 순서대로 설명)
[✔︎ 가장 많이 쓰는 차트 예시]
(1) 막대그래프 및 열 차트 (링크)

(2) 선 차트 및 콤보 차트 (링크)

(3) 스코어카드 (링크)
1개의 측정항목에 대한 요약 수치를 표시할 수 있다. 전자상거래 대시보드에서는 총매출, 구매 수, 광고소진액, 신규 유저, MAU, DAU에 대한 수치를 증감률과 함께 확인할 수 있다.

(4) 시계열 (링크)
시간의 흐름에 따라 데이터가 어떻게 변화되는지 확인할 수 있다. 전자상거래 대시보드에서는 일별 구매수, 세션별 일별 구매자 수, 일별 광고비 등을 확인할 수 있다.

(5) 원형 차트 (링크)
값 비율 차이가 큰 데이터를 비교할 때 많이 쓰는 차트로 전자상거래 대시보드에서는 광고비 비중, 채널별 비중을 확인할 수 있다.

(6) 트리맵 차트 (링크)
값이 큰 데이터 항목일수록 색상이 진하고 크기가 크게 표시되는 차트로 계층별로 정리하여 비교할 수 있다는 장점이 있다.

(7) 피벗 테이블

루커 시보드에서 데이터를 연결하고 어떤 차트를 구현할 수 있는지 파악이 완료되었다면 실제로 내가 활용할 대시보드의 목차를 기획해야 한다. 대시보드를 이용하는 사용자가 누군지 파악해야 하고 가능하면 사용자 관점에서 보기 편리하도록 대시보드를 구성해야 한다. 즉, 사용자가 무엇을 알고 싶어 하는지를 파악해야 한다.
가장 좋은 방법은 파악한 사용자들과 함께 회의를 통해 목차를 구성하고 아웃라인을 작성하는 것이지만 그것이 어렵다면 목차라도 함께 작성해야 한다. 사용자가 대시보드를 보고 의미를 쉽게 파악하지 못하거나, 알고 싶은 데이터가 대시보드에 반영되어 있지 않다면 지금까지 노력을 기울여 만든 대시보드의 활용성을 떨어지기 때문에 이 부분을 가장 중점적으로 생각해야 한다.
이커머스 서비스에서 가장 기본적으로 파악해야 하는 그래프를 바탕으로 대시보드 목차를 생각해 보면 다음과 같다.
GA4, 루커 스튜디오와 같이 구글 플랫폼을 활용할 때 많이 들어볼 수 있는 측정항목과 측정 기준의 개념을 이해하고 가는 것이 좋다.

Dimensions (측정기준)
Metrics (측정항목)

예를 들어 위 그림처럼 매체별 광고 성과에 대한 피벗 테이블 차트를 구현하고 대시보드에 추가하려고 한다면 어떻게 해야 할까?

피벗 테이블을 추가하고 수식을 걸지 않은 광고비, 노출, 클릭, 구매, 구매금액까지는 데이터 소스에서 추출하여 측정항목을 선택하여 그대로 차트에 넣으면 된다. 단, CPC, CTR, ROAS의 경우 수식 계산이 필요한데 계산된 필드로 만들어서 측정항목으로 추가할 수 있다.

계산된 필드 생성을 클릭하면 필드 생성 창이 뜨는데, 원하는 측정항목 이름으로 필드 이름을 적은 후 수식에 루커 스튜디오 함수 목록을 참고하여 수식을 입력한다.
[✔︎ 많이 쓰는 함수식]
(1) CPC
SUM(광고비) / SUM(클릭수)
(2) CTR
SUM(클릭) / SUM(노출)
(3) ROAS
SUM(구매금액) / SUM(광고비)
(4) CPI
SUM(광고비) / SUM(설치수)
(5) CPA (구매)
SUM(광고비) / SUM(구매이벤트수)
* 루커스튜디오 함수 목록 (링크)

이렇게 맞춤으로 생성한 계산된 필드는 데이터 툴바에서 파란색으로 필드명이 보이게 된다. 대시보드 화면에 추가한 차트를 클릭하여 해당 차트의 측정항목에 필드명을 가져온다.

속성 툴바에서는 설정과 스타일 탭 두 가지가 있는데 설정 탭에서는 차트에 들어가는 측정항목에 대한 추가/삭제, 필터, 정렬을 설정할 수 있고 스타일 툴바에서는 차트 색, 소수점, 글꼴, 데이터 없음 표시 종류 등 디자인과 관련한 항목을 설정할 수 있다.
(1) 소수점 변경하는 방법

(2) 색상 변경하는 방법

(3) 데이터 누락 서식 지정하는 방법

지금까지 루커 대시보드를 구현하는 방법에 대해 데이터 연결부터, 시각화 구성, 루커 대시보드 구현하는 방법까지 설명하였는데 루커 대시보드를 직접 구현해 보는 데 도움이 되었으면 좋겠다. 예시 대시보드를 참고하여 우리 서비스만의 대시보드를 만드는 것도 좋은 연습이 될 것 같다. 실제 우리 데이터를 연결해 보고 다양한 시각화를 시도해 보며 경험을 쌓는 데 좋은 시작이 될 것이라고 믿는다.
*궁금한 점이나 추가적인 도움이 필요하다면 언제든지 문의해 주세요! 여러분의 데이터 시각화 여정에 도움이 되기를 바랍니다. 감사합니다😊

July 3, 2024
본업이 그로스마케터이므로... '그로스마케팅'와 관련된 포스팅을 지속적으로 작성하고 있는데요. 관련 키워드로 '패션마케팅'이 검색량이 높아 무신사, 29CM, W컨셉을 사례로 준비해 보았습니다. (좀 더 알아보니 패션마케팅은 대학교 학과가 있어 입시생들의 검색량이 높은 키워드인 듯은 하네요.)
무신사의 브랜드마케터 채용 공고를 먼저 보겠습니다.

cf. https://brunch.co.kr/@marketer-emje/13

퍼포먼스마케팅에서 배너 광고를 운영할 때 그 소재로 브랜드가 강조될 수 있고, 프로모션이 강조될 수도 있고, 인플루언서가 강조될 수도 있고 메인 콘셉트를 무엇으로 하느냐에 따라서 소재 베리에이션은 다채로울 수 있는데요. 예시와 함께 보겠습니다.

페이스북 광고 라이브러리에서 'WConcept'을 검색했을 때 결과 중 일부를 가져왔는데요.


W컨셉에서 W컨셉 페이지로 랜딩 시키는 것은 당연한데, W컨셉에 입점해있는 '브랜드'들이 광고의 랜딩을 랜딩을 W컨셉으로 보내네요!
소규모 브랜드라면 개별 웹사이트를 관리, 운영하는 것보다 수수료를 감안하더라도 의류 플랫폼(W컨셉 등)에서의 매출을 높이는 것이 더 낫다고 판단했다고 추측할 수 있습니다.

신규 가입과 앱 첫 구매의 내용이 담겼다는 것은 해당 광고의 세팅이 '리타겟팅'이 아닐 것이라 추측할 수 있습니다. 아마 성별만 '남성'으로 지정하고 오픈 타겟으로 열지 않았을까 싶네요. 디타겟팅(=타겟에서 제외하는 것)으로 이미 회원인 분들과 앱이 있는 분들을 타겟에서 제외하고요.
해당 업무는 일반적인 퍼포먼스마케터/그로스마케터가 진행하기보다는 무신사의 예시처럼 '인플루언서 마케터'의 직무가 따로 있는 경우가 많습니다.

인스타그래머라면 피드, 스토리의 이미지/워딩 그리고 유튜버라면 유튜브 구성안과 기획안을 검토하면서 논의를 이어가게 됩니다. 일정, 비용, 스토리라인, 강조되어야 하는 점, 해시태그 등을 이야기하고요.
하단 예시처럼 유상 광고 소재(인스타그램 광고 소재)로 인플루언서의 이미지를 활용하는 경우 추가 협의가 필요합니다.



새로운 회원들을 어느 정도 유치했다면, 그 회원들을 계속해서 유지하는 것이 관건이겠죠. 리텐션(=재방문율/재구매율)이 그 지표가 되는데요. 리텐션의 기본으로 여겨지는 것 중 하나가 멤버십입니다.
W컨셉은 5개의 멤버십 등급을 가지고 있고, 그 기준으로는 누적 구매액과 함께 구매'수량'을 같이 보고 있습니다. 해석해 보자면 딱 한 개의 상품만 샀는데 - 그 상품이 100만 원짜리였다 -라고 했을 때 한 번에 VIP로 가는 것을 방지하기 위함이라고 볼 수 있습니다. 한 번 들어와서 비싼 것 한 개 산 사람보다, 여러 번 들어와서 중고가를 여러 개 산 사람이 더 충성도가 높다고 판단하는 것이겠죠?
29CM의 경우 동일한 워딩에 여러 브랜드X상품 이미지를 활용하기 위해 조금 포괄적인 내용을 광고 워딩으로 썼는데요. 29CM의 아이덴티티 + 매월 멤버십 쿠폰 ~15% 혜택을 강조합니다. 여기엔 신규 회원 가입이나 앱 설치 쿠폰이 없는 것을 보아 신규를 대상으로만 하는 광고가 아님을 알 수 있고요.


무신사스탠다드(무신사의 PB브랜드)의 마케팅 팀장 채용 공고에도 '중요 이벤트와 프로모션 지원을 통해' 라는 워딩을 통해 마케팅과 연계된 프로모션의 중요성을 인지할 수 있습니다.

상품 할인과 쿠폰 할인(상품 쿠폰, 장바구니 쿠폰)의 구분은 커머스에서 혜택을 설계할 때나 손익을 계산할 떄 때 그리고 심지어 프로덕트 애널리틱스에서 이벤트/프로퍼티의 택소노미를 설계할 때도 아주 중요한 요소입니다.



앱 설치 쿠폰 및 가입 혜택 프로모션은 Always-on 올웨이즈온 캠페인에 속하고, 홀리데이 프로모션은 팝업/애드훅 캠페인으로 볼 수 있겠죠? (와 쉽다!)
보통 앱 설치, 가입의 경우 장기적인 관점의 KPI 달성을 위해 진행되는 캠페인으로 일간/주간/월간 성과를 지속적으로 모니터링하고요. 팝업/애드훅 캠페인의 경우 정해진 기간 동안 최대 매출 등의 목표치를 달성하는 것이 중요합니다. (무신사의 무진장세일이 매년 역대급 매출을 갱신한다고 하죠...? 그렇지만 무진장 정도면 이제는 정규 캠페인이라고도 볼 수 있겠네요)


CRM 수단으로는 앱 중심의 서비스인 경우 앱푸시, 카카오톡을 위주로 사용하고 웹의 경우 배너/팝업 또한 CRM의 일환으로 볼 수 있겠습니다. 문자 및 이메일은 조금 더 전통적인 수단이겠죠?

CRM 마케팅은 CRM 마케터 직무로도 많이 채용하지만, 그로스마케터의 수행 업무에 수반되는 경우도 꽤 있습니다. 29CM의 그로스 마케터 채용 공고를 보면 '고객 커뮤니케이션 타겟 / 채널 / 메시지 테스트 및 운영' 이라는 워딩을 볼 수 있는데요. 하단처럼 쪼개서 생각할 수 있고, 결국 CRM 마케팅에 대한 내용이라는 것을 알 수 있습니다.
CRM 마케팅이 최근 뜨는 이유는 개인 정보 보호 트렌드 때문인데요. 과거 퍼포먼스마케팅에서는 정교한 타겟팅을 위해 사용자가 웹 내에서 행동했던 것들을 추적하는 (cookie, 쿠키! 한 번쯤은 지워보셨죠?) 것이 중요했는데 이 쿠키 정보의 제공이 중단되면서 일반적인 퍼포먼스마케팅의 효율이 낮아지며 비용이 높아진 것도 일부 원인이 있고요.
상대적으로 CRM은 이미 보유한 회원 모수를 대상으로 메시지를 보내기에, 신규 사용자를 획득하는 것보다 효율이 높고(=비용이 낮고) 운영에 필요한 실 비용이 메시지 발송 비용 정도로 상대적으로 비용이 낮기 때문도 있습니다. CRM마케팅은 기회가 된다면 다음에 좀 더 자세하게 풀어보도록 할게요!
이렇게 패션 플랫폼의 그로스 마케팅 (ft. 무신사, 29CM, W컨셉)을 광고 소재와 채용 공고, 프로덕트를 통해서 Acquisition과 Retention 위주로 알아봤습니다.
[다른 글 보러 가기]
그로스마케팅과 AARRR 퍼널 분석 (ft. 29CM)
https://brunch.co.kr/@marketer-emje/11
그로스마케팅이란? 콘텐츠도 퍼포먼스도 UIUX개선도!
https://brunch.co.kr/@marketer-emje/10

그로스마케팅과 AARRR:Acquisition 획득
https://brunch.co.kr/@marketer-emje/13

풀스택 마케팅 컨설팅펌 마티니아이오

July 2, 2024
블로그나 서비스를 운영하다 보면 내 게시물이나 제품이 자연스럽게 Google 또는 Naver 검색 결과에 노출되길 기대하게 됩니다.
이러한 관점에서 접근하는 방법이 Search Engine Optimization(SEO)입니다.
Google과 Naver 모두 자체 검색 엔진에서 노출되는 다양한 방법과 데이터를 제공합니다. 이는 각각 Google Search Console과 Naver Webmaster Tools입니다.
그 중 Google에서 제공하는 Google Search Console은 키워드 노출, 클릭 수, 순위 등 유용한 정보를 제공하지만, 여전히 복잡한 정보를 얻기에는 어려움이 있습니다.
저 또한 블로그를 운영하면서 Google Search Console을 자주 방문하고 관찰하지만, 이러한 점이 아쉬워 복잡한 데이터를 확인할 수 있는 대시보드를 만들었습니다.
1️. 좌측 하단의 구글서치콘솔 변경 시 내 데이터를 확인할 수 있습니다.
2️. 노출도에 따른 키워드 그룹을 두어서 그룹간 관리가 용이합니다.
3️. 새롭게 등장하는 키워드를 파악할 수 있습니다.
4️. 기간, 기기, 국가에 따라 다양한 지표 변화를 빠르게 확인할 수 있습니다.





